







大家好,之前有朋友反馈说GPT-Sovits有些难上手,操作比较复杂,问我有没有比较简单的工具,今天给大家分享的语音克隆工具操作非常简单,可商用!(整合包在文章末尾自取)
配置要求
WIN
- Windwos10/11操作系统
- 支持CPU/GPU
MAC
- Apple Silicon M系列芯片
- MacOS 10.13以上版本
如果需求多的话,我会考虑推出适用于Mac Intel芯片的版本。
使用教程
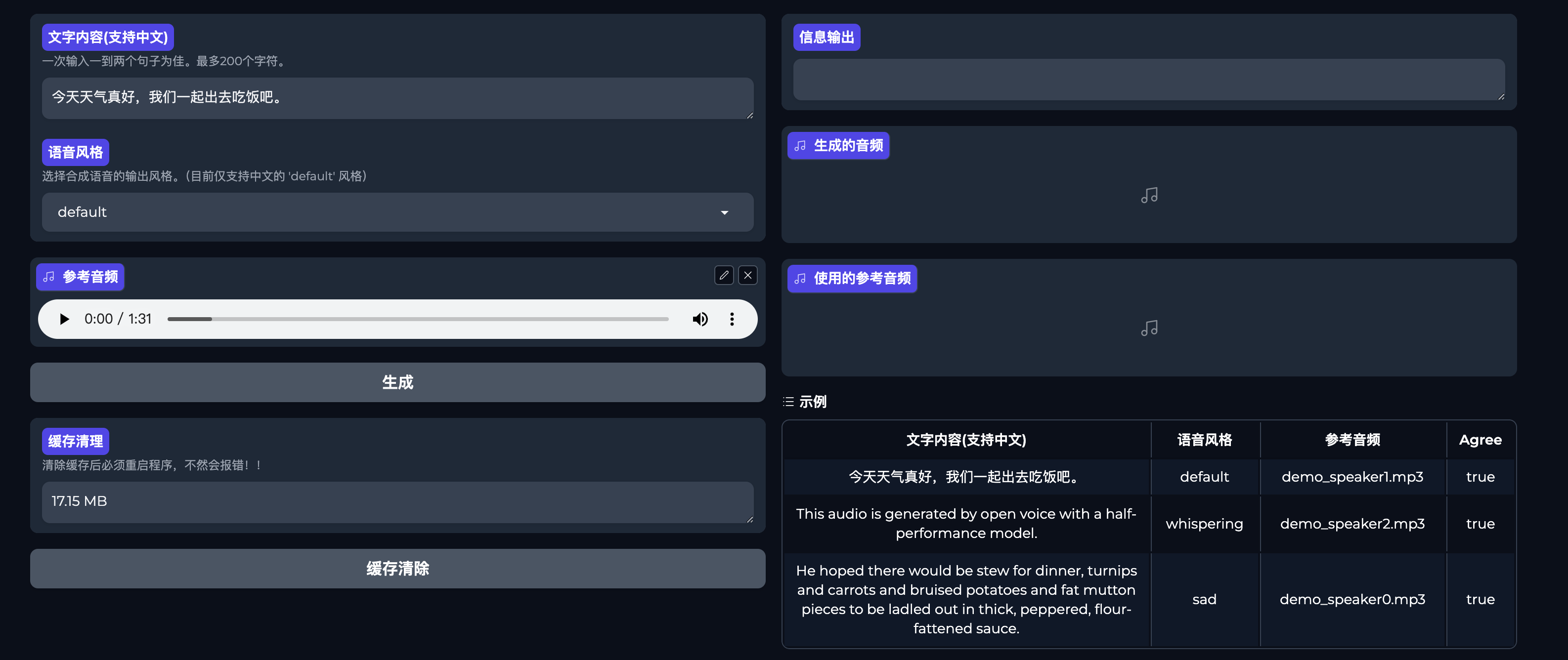
使用非常滴简单,在文字内容这栏里输入你想要生成的语音文案。(去掉了200字限制,理论上你可以输入更多的字数,自行尝试下)
语音风格选择default。(中文必须选择default)
参考音频上传一段你想要模仿的音色音频。
然后点击生成。耐心等待一会儿,可在生成的音频这里看到结果。
示例这里可以点击选择查看对应的效果。(这个示例里的中文参考音频太抽象了,建议自己上传自己的玩玩)
缓存清理这个是我新增的一个功能,防止内存被占满,可以适当的清理下。需要注意的是清理完后需重启下软件。否则再次生成的时候会报错。
常见问题
生成音频的口音和情感与参考音频不相似
首先,OpenVoice 仅克隆参考扬声器的音色。它不会克隆口音或情感。口音和情感由基础扬声器 TTS 模型控制,而不是由音色转换器克隆。如果想要改变输出的口音或情感,需要有一个具有该口音的基础扬声器模型。
生成的语音的音频质量较差
请检查以下内容:
- 参考音频是否足够干净,没有任何背景噪音?
- 你的音频是否太短?
- 你的音频是否包含多个人的讲话?
- 参考音频是否包含长空白部分?
- 检查是否将参考音频命名为与之前使用的名称相同但忘记删除processed文件夹?
整合包获取
👇🏻👇🏻👇🏻什么?是不是收费的?👇🏻👇🏻👇🏻

关注公众号,发送【OpenVoice】关键字获取整合包。

如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!


















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









