









一、简介
**easyocr**:
- EasyOCR 是一个使用 Java 语言实现的 OCR 识别引擎(基于Tesseract)。借助几个简单的API,即能使用Java语言完成图片内容识别工作。并集成了图片清理、识别 CAPTCHA 验证码图片,票据等内容的一体化工作。
- EasyOCR不仅可以为消费者提供服务,更主要面向开发,能够提供本地化的开发SDK集成,与 C/S,B/S 及 Android 移动端项目进行原生集成。
- EasyOCR 4.X 新架构上线,最新版本 4.2.0。
主要特点:- API 极简,一个方法,一行代码即可完成
- 纯本地化SDK,JAVA原生支持,可作为引擎嵌入各种项目,支持 Android 移动端集成
- 支持 API 级别的识别白名单限定,限定识别范围
- 支持上百种语言识别,并支持混合语言识别,如:英文+日文+德文
- 专门针对常用票据、验证码图片的清理、识别一体化实现,内置多种常见类型的验证码图片选项
- 支持自定义插件,能够编写基于EasyOCR一体化识别的图片清理扩展插件
- ETD模板支持,提供图形化ETD模板设计工具(EasyTemplateDesigner),准确可控提高识别率
- EasyOCR Suite 跨平台 GUI 套件支持,为开发人员和消费者提供设计和使用工具
- 标准输入输出,支持Socket网络接口的输入输出
- 支持识别训练,基于规则的结果修正训练,让识别准确合理,提供后天能力增长
- 性能卓越,默认纯内存运算交换
- 可脱离环境变量运行
- 跨平台支持:Window, Linux, Unix, Android
二、安装
# 安装稳定版本
pip install easyocr -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# 安装最新版本
pip install git+https://github.com/JaidedAI/EasyOCR.git
测试
import easyocr
print(easyocr.__version__)
下载模型地址:
https://www.jaided.ai/easyocr/modelhub/
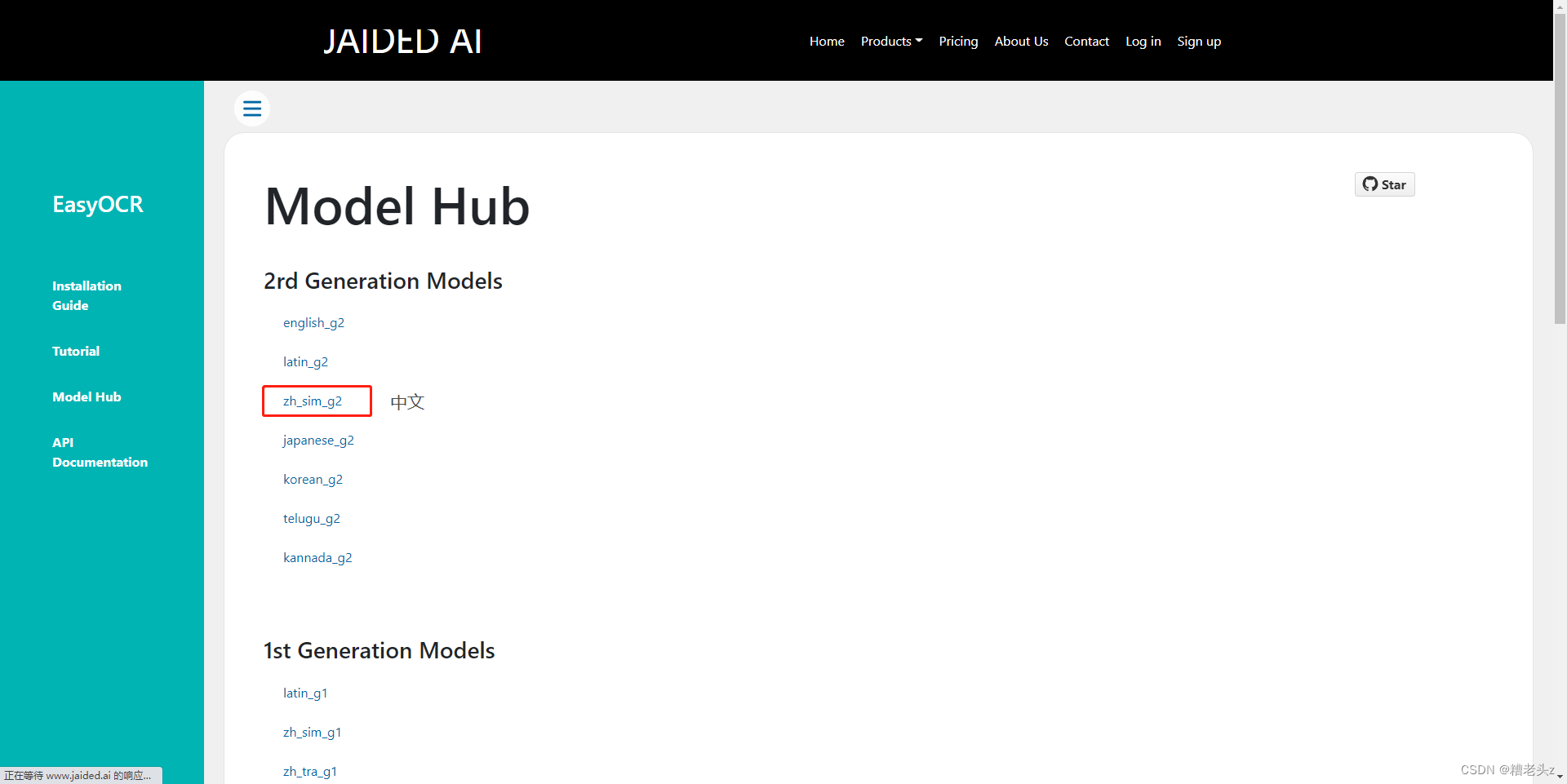
下载后把模型文件解压后拷贝到用户目录:C:\Users\用户名.EasyOCR\model
三、使用
Reader 方法详解:
- lang_list (list):识别语言代码,比如[‘ch_sim’,’en’]分别表示简体中文和英文。
- gpu (bool, string, default = True) :是否使能GPU,只有安装了GPU版本才有效。
- model_storage_directory (string, default = None) :模型存储位置,依次查找系统变量
- download_enabled (bool, default = True):如果没有对应模型文件时,自动下载模型。
- user_network_directory (bool, default = None) :用户自定义识别网络的路径
- recog_network (string, default = ‘standard’) :替代标准模型,使用自定义的识别网络。
- detector (bool, default = True) :是否加载检测模型。
- recognizer (bool, default = True) :是否加载识别模型。
readtext 方法详解
- image (string, numpy array, byte) : 输入图像;
- decoder (string, default = ‘greedy’):选项有 ‘greedy’、‘beamsearch’ 和 ‘wordbeamsearch’;
- beamWidth (int, default = 5) : 当解码器 = ‘beamsearch’ 或 ‘wordbeamsearch’ 时要保留多少光束;
- batch_size (int, default = 1) : batch_size>1 将使 EasyOCR 更快但使用更多内存;
- worker (int, default = 0) : 数据加载器中使用的编号线程;
- allowlist (string) : 强制 EasyOCR 只识别字符的子集。对特定问题有用(例如车牌等);
- blocklist (string) : 字符的块子集。如果给定了允许列表,则此参数将被忽略。
- detail (int, default = 1): 将此设置为 0 以进行简单输出;
- paragraph (bool, default = False):将结果合并到段落中;
- min_size (int, default = 10) : 过滤文本框小于最小值(以像素为单位);
- rotation_info (list, default = None) : 允许 EasyOCR 旋转每个文本框并返回具有最佳置信度分数的文本框。符合条件的值为 90、180 和 270。例如,对所有可能的文本方向尝试 [90, 180 ,270]。
- contrast_ths (float, default = 0.1) : 对比度低于此值的文本框将被传入模型 2 次。首先是原始图像,其次是对比度调整为“adjust_contrast”值。结果将返回具有更高置信度的那个;
- adjust_contrast (float, default = 0.5) : 低对比度文本框的目标对比度级别。
- text_threshold (float, default = 0.7) : 文本置信度阈值
- low_text (float, default = 0.4) : 文本下限分数
- link_threshold (float, default = 0.4) : 链接置信度阈值
- canvas_size (int, default = 2560) :最大图像尺寸。大于此值的图像将被缩小。
- mag_ratio (float, default = 1) :图像放大率
- slope_ths (float, default = 0.1) - 考虑合并的最大斜率 (delta y/delta x)。低值意味着不会合并平铺框。
- ycenter_ths (float, default = 0.5) - y 方向的最大偏移。不应该合并不同级别的框。
- height_ths (float, default = 0.5) - 盒子高度的最大差异。不应合并文本大小非常不同的框。
- width_ths (float, default = 0.5) - 合并框的最大水平距离。
- add_margin (float, default = 0.1) - 将边界框向所有方向扩展某个值。这对于具有复杂脚本的语言(例如泰语)很重要。
- x_ths (float, default = 1.0) - 当段落=True 时合并文本框的最大水平距离。
- y_ths (float, default = 0.5) - 当段落 = True 时合并文本框的最大垂直距离。
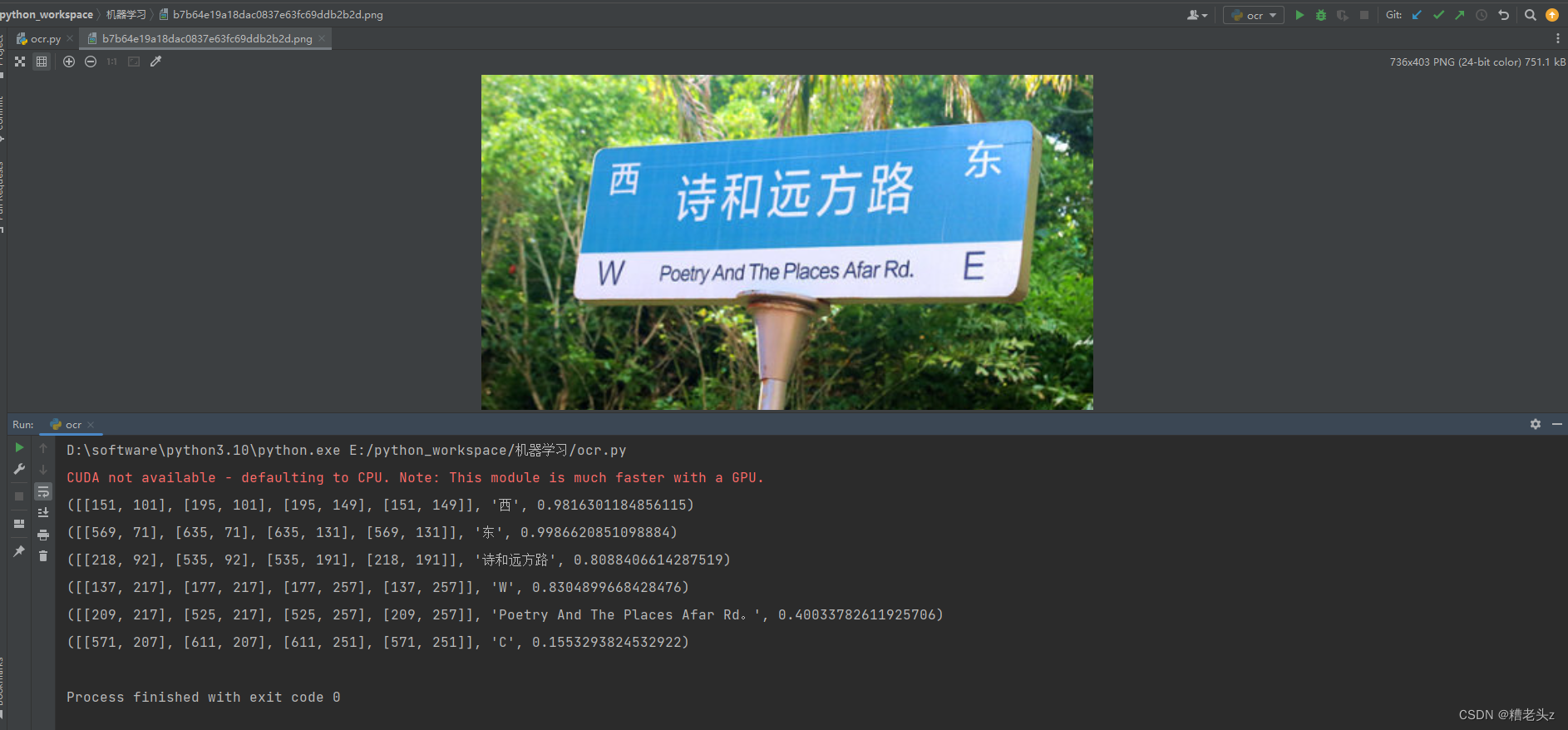
调用方式
import easyocr
reader = easyocr.Reader(['ch_sim', 'en'])
result = reader.readtext('xxxx.png')
for res in result:
print(res)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









