







一、原理
1.定义
CRITIC方法是一种客观权重赋权法。它的基本思路是确定指标的客观权数以两个基本概念为基础。一是对比强度,它表示同一指标各个评价方案取值差距的大小,以标准差的形式来表现。二是评价指标之间的冲突性,指标之间的冲突性是以指标之间的相关性为基础,如两个指标之间具有较强的正相关,说明两个指标冲突性较低。
2.作用
CRITIC权重法适用于判断数据稳定性,并且适合分析指标或因素之间有着一定的关联的数据。
二、相关概念
1.对比强度
是指同一个指标各个评价方案之间取值差距的大小,以标准差的形式来表现。标准差越大,说明波动越大,即各方案之间的取值差距越大,权重会越高。其中,假设m个待评对象,n个评价指标。
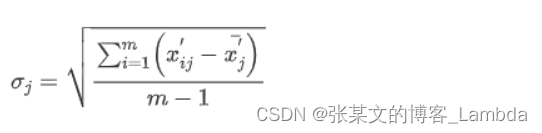
2.冲突性
指标之间的冲突性用相关系数进行表示,若两个指标之间具有较强的正相关,说明其冲突性越小,权重会越低。

3.信息承载量
设信息承载量为Cj,公式为:

三、步骤
1.数据标准化
每个指标的数量级不一样,需要把它们化到同一个范围内比较。指标也都需要正向化。此篇把正向化和标准化结合。
设有m个待评对象,n个评价指标,可以构成数据矩阵X = (xij)mxn.
- 若xj为负向指标(越小越优型指标),需如下处理:

- 若xj为正向指标(越大越优型指标),需如下处理:
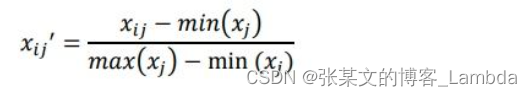
2.计算信息承载量
根据上述第二部分所列对比强度及冲突性公式,推导得信息承载量公式。
根据以上3个公式,计算所需信息承载量C。
3.计算权重
这里将计算的信息承载量 Cj 进行归一化,即为所计算的权重 W。可以看出,信息承载量越大时,权重越大。

4.计算评分
将权重 W 与处理后的矩阵 x 相乘,获得测评对象的分数(该公式中,分数未转为百分比形式)。

四、代码
import numpy as np
'''
4
5
1 1 2 1 1
0.483 13.2682 0.0 4.3646 5.1070
0.4035 13.4909 39.0131 3.6151 5.5005
0.8979 25.7776 9.0513 4.8920 7.5342
0.5927 16.0245 13.2935 4.4529 6.5913
'''
'''1.输入数据'''
print("请输入参评对象数目:")
n = eval(input())
print("请输入评价指标数目:")
m = eval(input())
print("请输入指标类型:1:极大型,2:极小型")
kind = input().split(" ")
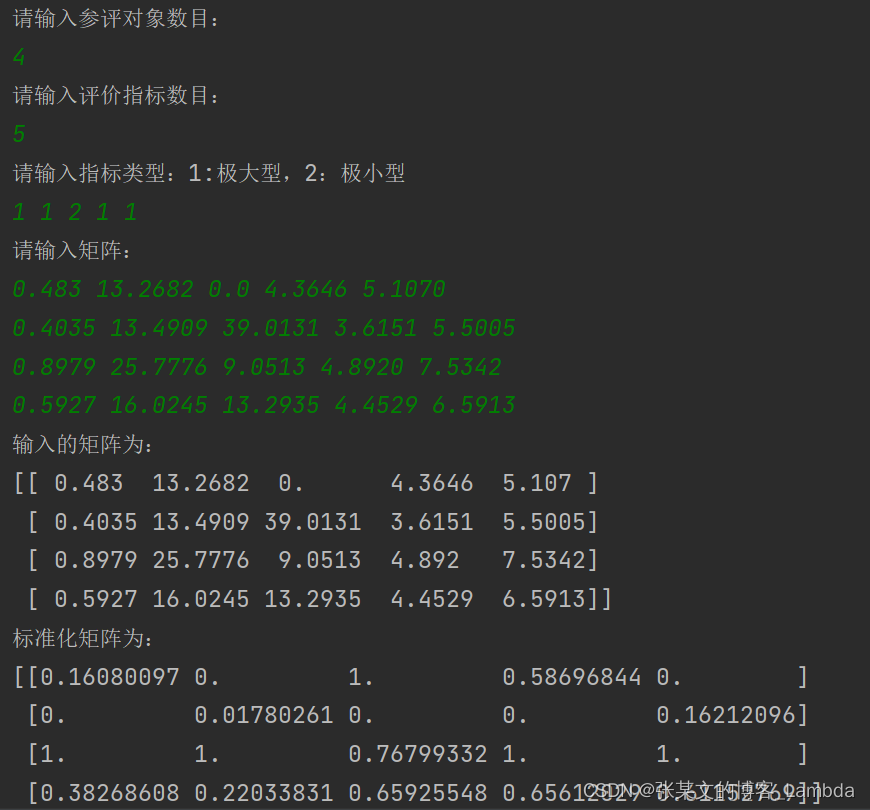
print("请输入矩阵:")
X = np.zeros(shape=(n, m))
for i in range(n):
X[i] = input().split(" ")
X[i] = list(map(float, X[i]))
print("输入的矩阵为:\n{}".format(X))
'''2.标准化处理'''
def maxTomax(maxx, minx, x):
x = list(x)
ans = [[(e-minx)]/(maxx-minx) for e in x]
return np.array(ans)
def minTomax(maxx, minx, x):
x = list(x)
ans = [[(maxx-e)]/(maxx-minx) for e in x]
return np.array(ans)
A = np.zeros(shape=(n, 1))
for i in range(m):
maxA = max(X[:, i])
minA = min(X[:, i])
if kind[i] == "1":
v = maxTomax(maxA, minA, X[:, i])
elif kind[i] == "2":
v = minTomax(maxA, minA, X[:, i])
if i == 0:
A = v.reshape(-1, 1)
else:
A = np.hstack([A, v.reshape(-1, 1)])
print("标准化矩阵为:\n{}".format(A))
'''3.计算对比强度'''
V = np.std(A, axis=0)
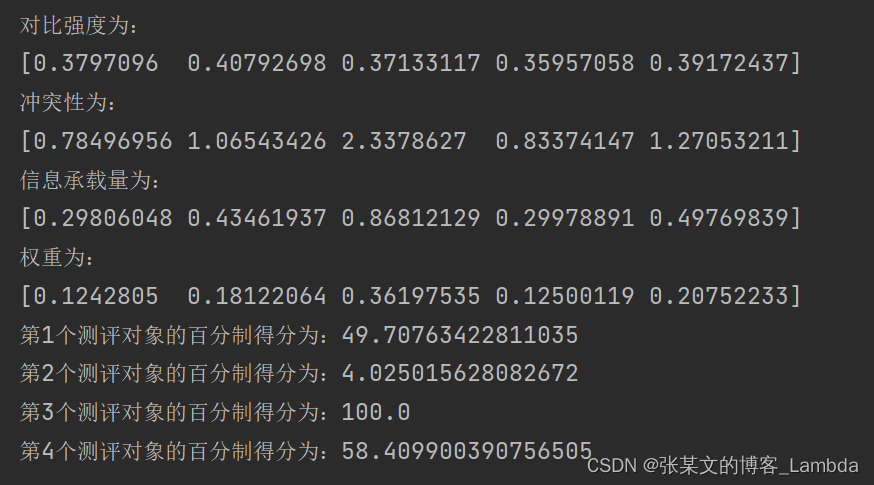
print("对比强度为:\n{}".format(V))
'''4.计算冲突性'''
A2 = list(map(list, zip(*A))) # 矩阵转置
r = np.corrcoef(A2) # 求皮尔逊相关系数
f = np.sum(1-r, axis=1)
print("冲突性为:\n{}".format(f))
'''5.计算信息承载量'''
C = V*f
print('信息承载量为:\n{}'.format(C))
'''6.计算权重'''
w = C/np.sum(C)
print('权重为:\n{}'.format(w))
'''7.计算得分'''
s = np.dot(A, w)
Score = 100*s/max(s)
for i in range(len(Score)):
print(f"第{i+1}个测评对象的百分制得分为:{Score[i]}")















 2661
2661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











