






前提
需要了解@FunctionalInterface:函数式接口,很多方法参数都是函数式接口,需要了解的可以看下这篇文章
Jdk8,@FunctionalInterface:函数式接口,学会使用lamda表达式,通俗易懂
比如转化Map的toMap方法
比如对集合分组的groupingBy方法
比如获取最大值的maxBy方法



数据转换
1:转List
1.基础转化
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void toList() {
List<String> collect = list.stream().map(t -> t + "*").collect(Collectors.toList());
System.out.println("collect = " + collect);
}
输出:对集合每个元素拼接"*",然后将拼接结果转为List
collect = [5*, 2*, 4*, 1*, 6*, 3*, 10*, 8*, 7*, 9*]
2.List嵌套转List(List<List>转List:借助flatMap)
@Test
public void nestList() {
List<List<Integer>> nestList = Arrays.asList(Arrays.asList(1, 2), Arrays.asList(3, 4), Collections.emptyList(), Arrays.asList(5, 6));
System.out.println("nestList = " + nestList);
List<Integer> normalList = nestList.stream().flatMap(Collection::stream).collect(Collectors.toList());
System.out.println("normalList = " + normalList);
}
输出:可以看到List里面就算嵌套一个空的list:[],也是可以正常转化
nestList = [[1, 2], [3, 4], [], [5, 6]]
normalList = [1, 2, 3, 4, 5, 6]
2:转Set
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void toSet() {
Set<Integer> collect = list.stream().collect(Collectors.toSet());
System.out.println("collect = " + collect);
}
输出
collect = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
3:转Collection
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void toCollection() {
Set<Integer> collect = list.stream().collect(Collectors.toCollection(TreeSet::new));
System.out.println("collect.getClass().getName() = " + collect.getClass().getName());
}
输出:将List转成了TreeSet
collect.getClass().getName() = java.util.TreeSet
4:转Map
1.基础转化
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void toMap() {
Map<Integer, Integer> collect = list.stream().collect(Collectors.toMap(Function.identity(), v -> v * 10));
System.out.println("collect = " + collect);
}
这里使用到了Function.identity(),其实对应的就是我们平时的写法:t -> t,意思就是传入对象t,然后把这个传入的对象直接返回
/**
* Returns a function that always returns its input argument.
*
* @param <T> the type of the input and output objects to the function
* @return a function that always returns its input argument
*/
static <T> Function<T, T> identity() {
return t -> t;
}
输出:key为对象自身,value为对象自身 * 10
collect = {1=10, 2=20, 3=30, 4=40, 5=50, 6=60, 7=70, 8=80, 9=90, 10=100}
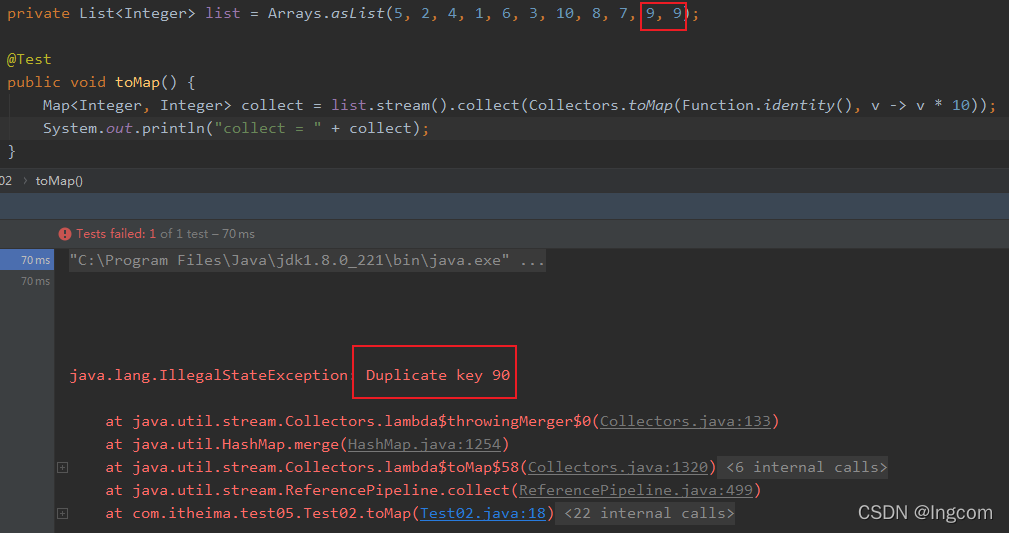
2.处理key值重复
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9, 9);
@Test
public void toMapWithMergeFunction() {
Map<Integer, Integer> collect = list.stream().collect(Collectors.toMap(Function.identity(), v -> v * 10, (first, second) -> second));
System.out.println("collect = " + collect);
}
这里使用到了mergeFunction,也就是:(first, second) -> second,意思就是key值重复的话,使用重复的这个做为key
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) {
return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
}
如果key值重复不使用这个mergeFunction对象,代码会报错!!!
输出:key为对象自身,value为对象自身 * 10
collect = {1=10, 2=20, 3=30, 4=40, 5=50, 6=60, 7=70, 8=80, 9=90, 10=100}
3.指定Map类型
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void toMapWithMapSupplier() {
Map<Integer, Integer> collect = list.stream().collect(Collectors.toMap(Function.identity(), v -> v * 10, (first, second) -> second, LinkedHashMap::new));
System.out.println("collect.getClass().getName() = " + collect.getClass().getName());
}
这里使用到了mapSupplier,也就是:LinkedHashMap::new,意思就是使用LinkedHashMap类型的Map
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) {
return toMap(keyMapper, valueMapper, mergeFunction, HashMap::new);
}
输出:
collect.getClass().getName() = java.util.LinkedHashMap
4.并发转化
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void toConcurrentMapWithMergeFunction() {
Map<Integer, Integer> collect = list.parallelStream().collect(Collectors.toConcurrentMap(Function.identity(), v -> {
System.out.println("Thread.currentThread().getName() = " + Thread.currentThread().getName());
return v * 10;
}, (first, second) -> second));
System.out.println("collect = " + collect);
System.out.println("collect.getClass().getName() = " + collect.getClass().getName());
}
@Test
public void toConcurrentMapWithMergeFunction() {
Map<Integer, Integer> collect = list.parallelStream().collect(Collectors.toConcurrentMap(Function.identity(), v -> v * 10, (first, second) -> second));
System.out.println("collect = " + collect);
System.out.println("collect.getClass().getName() = " + collect.getClass().getName());
}
输出:这里使用到了parallelStream,也就是并发流,默认使用系统自带的ForkJoinPool线程池进行多线程处理,可以看到主线程和线程池线程都参与了处理,使用了线程线程安全的ConcurrentHashMap
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-4
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-2
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-3
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-5
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-1
Thread.currentThread().getName() = main
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-3
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-6
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-2
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-4
collect = {1=10, 2=20, 3=30, 4=40, 5=50, 6=60, 7=70, 8=80, 9=90, 10=100}
collect.getClass().getName() = java.util.concurrent.ConcurrentHashMap
数据分组
1:普通分组
1.基础分组
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void groupingBy() {
Map<Integer, List<Integer>> collect = list.stream().collect(Collectors.groupingBy(k -> k % 2));
System.out.println("collect = " + collect);
}
输出:根据除以2的余数进行分组,共两组,key为0和1
collect = {0=[2, 4, 6, 10, 8], 1=[5, 1, 3, 7, 9]}
2.分组后,操作组内数据
例子1
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void groupingByWithDownstream() {
Map<Integer, Map<Integer, List<Integer>>> collect = list.stream().collect(Collectors.groupingBy(k -> k % 2, Collectors.groupingBy(k -> k % 3)));
System.out.println("collect = " + collect);
}
这里使用到了downstream,也就是:Collectors.groupingBy(k -> k % 3),意思就是根据除以3的余数进行分组
public static <T, K, A, D>
Collector<T, ?, Map<K, D>> groupingBy(Function<? super T, ? extends K> classifier,
Collector<? super T, A, D> downstream) {
return groupingBy(classifier, HashMap::new, downstream);
}
输出:根据除以2的余数进行分组,共两组,key为0和1。分完组后再对组内数据进行二次分组,二次分组根据除以3的余数进行分组,共三组,key为0,1和2
collect = {0={0=[6], 1=[4, 10], 2=[2, 8]}, 1={0=[3, 9], 1=[1, 7], 2=[5]}}
例子2
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void groupingByWithDownstream2() {
Map<Integer, List<Integer>> collect = list.stream().collect(Collectors.groupingBy(k -> k % 2, Collectors.mapping(t -> t + 10, Collectors.toList())));
System.out.println("collect = " + collect);
}
输出:根据除以2的余数进行分组,共两组,key为0和1。分完组后再对组内每个数据分别加上10
collect = {0=[12, 14, 16, 20, 18], 1=[15, 11, 13, 17, 19]}
3.指定Map类型
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void groupingByWithMapFactory() {
Map<Integer, Map<Integer, List<Integer>>> collect = list.stream().collect(Collectors.groupingBy(k -> k % 2, LinkedHashMap::new, Collectors.groupingBy(k -> k % 3)));
System.out.println("collect.getClass().getName() = " + collect.getClass().getName());
}
这里使用到了mapFactory,也就是:LinkedHashMap::new,意思就是使用LinkedHashMap类型的Map
public static <T, K, D, A, M extends Map<K, D>>
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream)
输出:
collect.getClass().getName() = java.util.LinkedHashMap
4.并发分组
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void groupingByConcurrent() {
Map<Integer, List<Integer>> collect = list.parallelStream().collect(Collectors.groupingByConcurrent(k -> {
System.out.println("Thread.currentThread().getName() = " + Thread.currentThread().getName());
return k % 2;
}));
System.out.println("collect = " + collect);
System.out.println("collect.getClass().getName() = " + collect.getClass().getName());
}
@Test
public void groupingByConcurrentWithDownstream() {
Map<Integer, Map<Integer, List<Integer>>> collect = list.parallelStream().collect(Collectors.groupingByConcurrent(k -> k % 2, Collectors.groupingBy(k -> k % 3)));
System.out.println("collect = " + collect);
System.out.println("collect.getClass().getName() = " + collect.getClass().getName());
}
输出:这里使用到了parallelStream,也就是并发流,默认使用系统自带的ForkJoinPool线程池进行多线程处理,可以看到主线程和线程池线程都参与了处理,使用了线程线程安全的ConcurrentHashMap
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-4
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-6
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-3
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-4
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-4
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-2
Thread.currentThread().getName() = main
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-1
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-1
Thread.currentThread().getName() = ForkJoinPool.commonPool-worker-5
collect = {0=[8, 2, 10, 4, 6], 1=[9, 3, 7, 5, 1]}
collect.getClass().getName() = java.util.concurrent.ConcurrentHashMap
2:Boolean分组
1.基础分组
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void partitioningBy() {
Map<Boolean, List<Integer>> collect = list.stream().collect(Collectors.partitioningBy(k -> k % 2 == 0));
System.out.println("collect = " + collect);
}
输出:根据除以2的余数是否等于0进行分组,共两组,key为true和false
collect = {false=[5, 1, 3, 7, 9], true=[2, 4, 6, 10, 8]}
2.分组后,操作组内数据
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void partitioningByWithDownstream() {
Map<Boolean, Map<Boolean, List<Integer>>> collect = list.stream().collect(Collectors.partitioningBy(k -> k % 2 == 0, Collectors.partitioningBy(k -> k % 3 == 0)));
System.out.println("collect = " + collect);
}
这里使用到了downstream,也就是:Collectors.groupingBy(k -> k % 3 == 0),意思就是根据除以3的余数是否等于0进行分组
public static <T, D, A>
Collector<T, ?, Map<Boolean, D>> partitioningBy(Predicate<? super T> predicate,
Collector<? super T, A, D> downstream)
输出:根据除以2的余数是否等于0进行分组,共两组,key为true和false。分完组后再对组内数据进行二次分组,二次分组根据除以3的余数是否等于0进行分组,共两组,key为true和false
collect = {false={false=[5, 1, 7], true=[3, 9]}, true={false=[2, 4, 10, 8], true=[6]}}
数据统计
1:统计数量
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void counting() {
Long collect = list.stream().collect(Collectors.counting());
System.out.println("collect = " + collect);
}
输出
collect = 10
2:统计和
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void summingInt() {
Integer collect = list.stream().collect(Collectors.summingInt(t -> t));
System.out.println("collect = " + collect);
}
@Test
public void summingLong() {
Long collect = list.stream().collect(Collectors.summingLong(t -> t));
System.out.println("collect = " + collect);
}
@Test
public void summingDouble() {
Double collect = list.stream().collect(Collectors.summingDouble(t -> t));
System.out.println("collect = " + collect);
}
输出:三个方法都是统计和,区别只在于统计结果的数据类型,分别为 Integer ,Long ,和Double
collect = 55
collect = 55
collect = 55.0
3:统计平均数
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void averagingInt() {
Double collect = list.stream().collect(Collectors.averagingInt(t -> t));
System.out.println("collect = " + collect);
}
@Test
public void averagingLong() {
Double collect = list.stream().collect(Collectors.averagingLong(t -> t));
System.out.println("collect = " + collect);
}
@Test
public void averagingDouble() {
Double collect = list.stream().collect(Collectors.averagingDouble(t -> t));
System.out.println("collect = " + collect);
}
输出:三个方法都是统计平均数,区别只在于统计结果的数据类型,分别为 Integer ,Long ,和Double
collect = 5.5
collect = 5.5
collect = 5.5
4:统计最小值
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void minBy() {
Optional<Integer> collect = list.stream().collect(Collectors.minBy(Integer::compareTo));
System.out.println("collect = " + collect);
}
输出
collect = Optional[1]
5:统计最大值
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void maxBy() {
Optional<Integer> collect = list.stream().collect(Collectors.maxBy(Integer::compareTo));
System.out.println("collect = " + collect);
}
输出
collect = Optional[10]
6:组合统计
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void summarizingInt() {
IntSummaryStatistics collect = list.stream().collect(Collectors.summarizingInt(t -> t));
System.out.println("collect = " + collect);
}
@Test
public void summarizingLong() {
LongSummaryStatistics collect = list.stream().collect(Collectors.summarizingLong(t -> t));
System.out.println("collect = " + collect);
}
@Test
public void summarizingDouble() {
DoubleSummaryStatistics collect = list.stream().collect(Collectors.summarizingDouble(t -> t));
System.out.println("collect = " + collect);
}
输出:统计出数量,和,最小值,平均数,最大值
collect = IntSummaryStatistics{count=10, sum=55, min=1, average=5.500000, max=10}
collect = LongSummaryStatistics{count=10, sum=55, min=1, average=5.500000, max=10}
collect = DoubleSummaryStatistics{count=10, sum=55.000000, min=1.000000, average=5.500000, max=10.000000}
其他操作
1:处理集合里的每个元素,然后进行二次操作
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void mapping() {
Map<Integer, List<Integer>> collect = list.stream().collect(Collectors.mapping(t -> t * t, Collectors.groupingBy(k -> k % 2)));
System.out.println("collect = " + collect);
}
输出:这里先对集合的每个元素进行平方操作,然后对平方的结果除以2的余数进行分组
collect = {0=[4, 16, 36, 100, 64], 1=[25, 1, 9, 49, 81]}
2:获取第一次操作结果,进行第二次操作
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void collectingAndThen() {
Map<Integer, List<Integer>> collect = list.stream().collect(Collectors.collectingAndThen(Collectors.groupingBy(k -> k % 2), d -> {
Map<Integer, List<Integer>> map = new HashMap<>((int) (d.size() / 0.75F));
d.forEach((key, value) -> map.put(key + 10, value.stream().map(t -> t * 10).collect(Collectors.toList())));
return map;
}));
System.out.println("collect = " + collect);
}
输出:这里第一次操作是根据除以2的余数进行分组,第二次操作对分组后的结果进行遍历,对key + 10 ,对value * 10,组成一个新的map并返回
collect = {10=[20, 40, 60, 100, 80], 11=[50, 10, 30, 70, 90]}
3:将集合数据进行字符串拼接
1.无拼接符拼接
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void joining() {
String collect = list.stream().map(Objects::toString).collect(Collectors.joining());
System.out.println("collect = " + collect);
}
输出
collect = 52416310879
2.根据拼接符进行拼接
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void joiningWithDelimiter() {
String collect = list.stream().map(Objects::toString).collect(Collectors.joining(","));
System.out.println("collect = " + collect);
}
输出
collect = 5,2,4,1,6,3,10,8,7,9
3.根据拼接符进行拼接,并对开始前和结束后拼接自定义的字符串
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void joiningWithStartAndEnd() {
String collect = list.stream().map(Objects::toString).collect(Collectors.joining(",", "[", "]"));
System.out.println("collect = " + collect);
}
输出
collect = [5,2,4,1,6,3,10,8,7,9]
4:聚合操作
1.基础聚合
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void reducing() {
Optional<Integer> collect = list.stream().collect(Collectors.reducing((t, u) -> {
System.out.println("t = " + t);
System.out.println("u = " + u);
System.out.println("--------");
return t - u;
}));
System.out.println("collect = " + collect);
}
输出:对集合元素进行累减,从第二个参数t可以看出, t为上一次操作的结果。在这里第一个t = 5,u = 2,t - u = 3赋值到第二个t,所以二个t = 3
t = 5
u = 2
--------
t = 3
u = 4
--------
t = -1
u = 1
--------
t = -2
u = 6
--------
t = -8
u = 3
--------
t = -11
u = 10
--------
t = -21
u = 8
--------
t = -29
u = 7
--------
t = -36
u = 9
--------
collect = Optional[-45]
2.指定初始值聚合
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void reducingWithIdentity() {
Integer collect = list.stream().collect(Collectors.reducing(100, (t, u) -> {
System.out.println("t = " + t);
System.out.println("u = " + u);
System.out.println("--------");
return t - u;
}));
System.out.println("collect = " + collect);
}
输出:第一个参数t,跟上面例子对比,发现不是5,而是指定的初始值100
t = 100
u = 5
--------
t = 95
u = 2
--------
t = 93
u = 4
--------
t = 89
u = 1
--------
t = 88
u = 6
--------
t = 82
u = 3
--------
t = 79
u = 10
--------
t = 69
u = 8
--------
t = 61
u = 7
--------
t = 54
u = 9
--------
collect = 45
3.处理集合每个元素再聚合
private List<Integer> list = Arrays.asList(5, 2, 4, 1, 6, 3, 10, 8, 7, 9);
@Test
public void reducingWithMapper() {
Integer collect = list.stream().collect(Collectors.reducing(100, t -> t + 10, (t, u) -> {
System.out.println("t = " + t);
System.out.println("u = " + u);
System.out.println("--------");
return t - u;
}));
System.out.println("collect = " + collect);
}
输出:从参数可以看到,这里执行了 t -> t + 10 操作,对集合的每个元素进行自增10
t = 100
u = 15
--------
t = 85
u = 12
--------
t = 73
u = 14
--------
t = 59
u = 11
--------
t = 48
u = 16
--------
t = 32
u = 13
--------
t = 19
u = 20
--------
t = -1
u = 18
--------
t = -19
u = 17
--------
t = -36
u = 19
--------
collect = -55














 5054
5054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









