







Python数据分析:图表美观清晰,自带对比功能
本文转自Github 点此链接跳转原文
sweetviz库的使用
特点:
1.目标分析
How target values (boolean or numerical) relate to other features
2.可视化及比较分析:
(1)两个数据集之间 Distinct datasets (e.g. training vs test data)
(2)同个数据集的不同类别 Intra-set characteristics (e.g. male versus female)
3.混合型关联
Sweetviz integrates associations for numerical (Pearson’s correlation), categorical (uncertainty coefficient) and categorical-numerical (correlation ratio) datatypes seamlessly, to provide maximum information for all data types.
4.类型推断
automatically detects numerical, categorical and text features, with optional manual overrides
5.总结性信息分析:
(1)Type, unique values, missing values, duplicate rows, most frequent values
(2)Numerical analysis:min/max/range, quartiles, mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness

1.库的安装
pip install sweetviz2.基本使用语法
创建DataframeReport对象,然后使用show_xxx函数可视化报告
Note: Currently the only rendering supported is to a standalone HTML file, using a “widescreen” aspect ratio (i.e. 1080p resolution or wider). Please let me know of formats/resolutions you would like to be supported in our Discourse Forum.
三个主要函数:
- analyze(…)
- compare(…)
- compare_intra(…)
3.分析单个数据(及其可选的目标功能)
直接上代码
import sweetviz as sv
my_report = sv.analyze(my_dataframe)
my_report.show_html() # Default arguments will generate to "SWEETVIZ_REPORT.html"
** 可选参数 **
analyze()函数的其他参数
analyze(source: Union[pd.DataFrame, Tuple[pd.DataFrame, str]],
target_feat: str = None,
feat_cfg: FeatureConfig = None,
pairwise_analysis: str = 'auto'):- source: Either the data frame (as in the example) or a tuple containing the data frame and a name to show in the report. e.g.
my_dfor[my_df, "Training"] - target_feat: A string representing the name of the feature to be marked as “target”. Only BOOLEAN and NUMERICAL features can be targets for now.
- feat_cfg: A FeatureConfig object representing features to be skipped, or to be forced a certain type in the analysis. The arguments can either be a single string or list of strings. Parameters are
skip,force_cat,force_numandforce_text. The “force_” arguments override the built-in type detection. They can be constructed as follows:
feature_config = sv.FeatureConfig(skip="PassengerId", force_text=["Age"])- pairwise_analysis: Correlations and other associations can take quadratic time (n^2) to complete. The default setting (“auto”) will run without warning until a data set contains “association_auto_threshold” features. Past that threshold, you need to explicitly pass the parameter
pairwise_analysis="on"(or ="off") since processing that many features would take a long time. This parameter also covers the generation of the association graphs (based on Drazen Zaric’s concept):
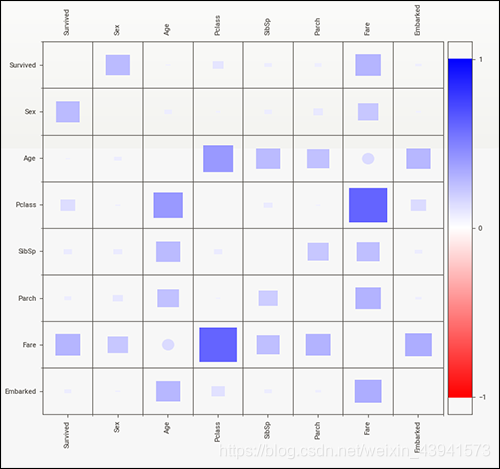
4.两个数据对比(如:测试集 vs 训练集)
To compare two data sets, simply use the compare() function. Its parameters are the same as analyze(), except with an inserted second parameter to cover the comparison dataframe. It is recommended to use the [dataframe, “name”] format of parameters to better differentiate between the base and compared dataframes. (e.g. [my_df, “Train”] vs my_df)
my_report = sv.compare([my_dataframe, "Training Data"], [test_df, "Test Data"], "Survived", feature_config)5.比较同个数据中两个子集(e.g. Male vs Female)
Another way to get great insights is to use the comparison functionality to split your dataset into 2 sub-populations.Support for this is built in through the compare_intra() function. This function takes a boolean series as one of the arguments, as well as an explicit “name” tuple for naming the (true, false) resulting datasets. Note that internally, this creates 2 separate dataframes to represent each resulting group. As such, it is more of a shorthand function of doing such processing manually.
my_report = sv.compare_intra(my_dataframe, my_dataframe["Sex"] == "male", ["Male", "Female"], feature_config)













 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









