from transformers import AutoTokenizer, AutoModel
import torch
from sentence_transformers.util import cos_sim
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
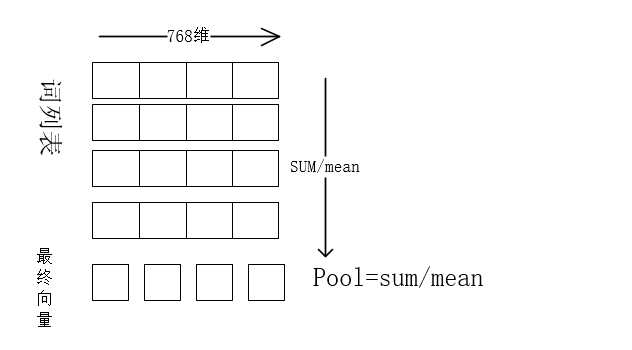
token_embeddings = model_output.last_hidden_state #First element of model_output contains all token embeddings
print(attention_mask.shape)#(batch,maxlen(seq0,seq1))
print(attention_mask.unsqueeze(-1).shape,token_embeddings.size())
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
print(input_mask_expanded.shape)#(2,8,768)
print(torch.sum(token_embeddings * input_mask_expanded, 1).shape)#torch.Size([batch, 768])
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["他很高兴", "他很开心"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('google-bert/bert-base-chinese')
model = AutoModel.from_pretrained('google-bert/bert-base-chinese')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
print(model_output.last_hidden_state.shape)#(2,seq_len,768)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(cos_sim(sentence_embeddings[0], sentence_embeddings[1]))

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









