







实验1 安装Hadoop
实验2 通过Shell 访问hdfs
实验3 通过Java API 访问HDFS
常见问题:
1. 编译无法通过
参考解决方法
查看Import包是否正确
查看Maven版本是否为自定义版本而不是系统自带版本
查看Maven仓是否为自定义路径。
尝试删除Maven仓或者重新设置Maven仓目录。
重启Idea, 重启系统
查看依赖包是否正确
查看Java包是否安装正确
2. 运行后无法上传文件,或者直接报Configuration错误
参考解决方法
查看Java包配置是否正确
查看Pom文件有没有配置hadoop相关内容
尝试去掉字段
查看Hadoop-windows是否配置正确。注意一定是Windows版本的依赖包不要弄成Linux了!
3. 无法完成下载,或者下载是空文件
查看Hadoop-windows是否配置正确。注意一定是Windows版本的依赖包不要弄成Linux了!
重启Idea, 重启电脑(重启大法好!)
4 其他问题
系统防火墙不让进行多线程操作或者不让写入文件。
尝试用管理员模式进入
尝试关闭防火墙
实验4 WordCount
常见问题:
1. 无法启动集群:
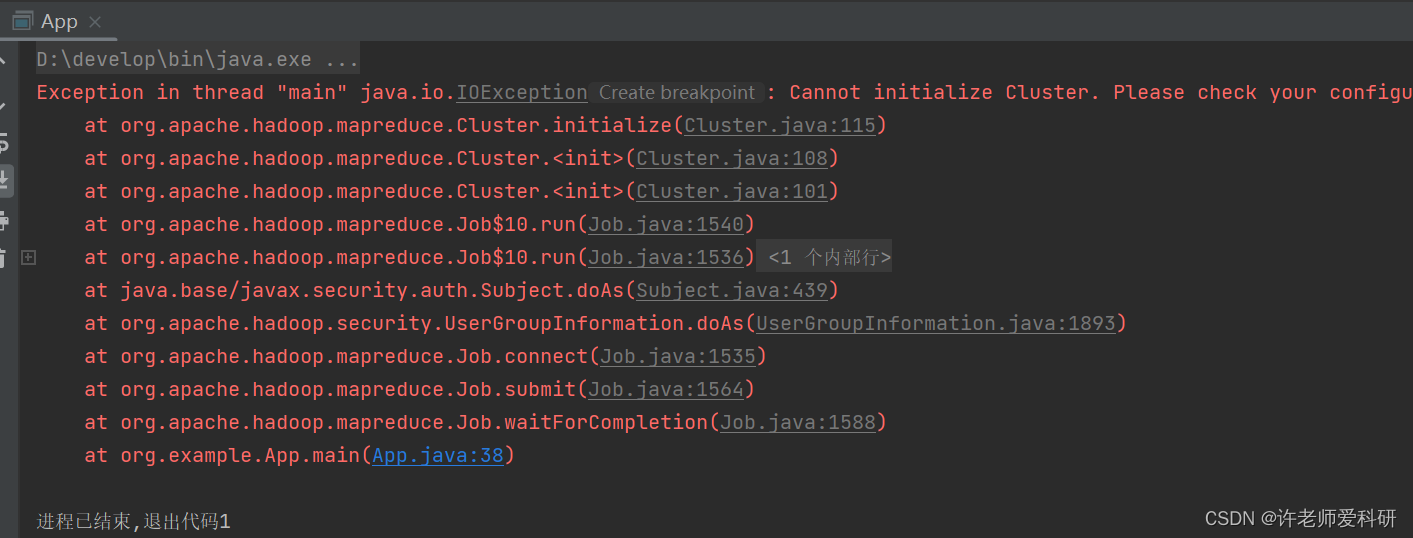
参考解决方法:
检查pom文件
查看依赖项是否正确,如果报错注意字段,可以尝试删除。
查看是否添加mapreduce的依赖项
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.9.2</version>
</dependency>
如果修改无效,重启Idea, 重启系统。
2. 可以启动集群,但是运行的时候说output目录有问题
解决方案
删掉output 文件夹
3. Mapredue正常运行,能够生成output文件夹,但是没有内容
查看代码是否正确
查看input文件是否符合要求
查看hadoop-windows 是否安装正确
Text 包没有引用正确
由idea自动生成的函数引用包不正确。
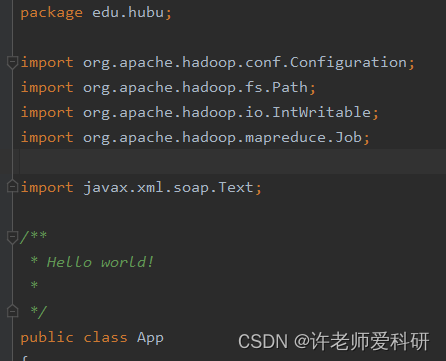
这里的Text不是hadoop包,正确如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
附参考main文件
package edu.hubu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class App
{
public static void main( String[] args ) throws Exception {
//创建Configuration对象时,会自动加载默认配置参数
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 1、封装参数:main方法所在的class
job.setJarByClass(App.class);
// 2、封装参数: 本次job所要调用的Mapper实现类、Reducer实现类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 3、封装参数:本次job的Mapper实现类、Reducer实现类产生的结果数据的key、value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 4、封装参数:本次job要处理的输入数据集所在路径、最终结果的输出路径
//需要提前将素材文件保存到windows的d:/wordcount/input目录中
FileInputFormat.setInputPaths(job, new Path("d:/wordcount/input"));
FileOutputFormat.setOutputPath(job, new Path("d:/wordcount/output")); // 注意:输出路径必须不存在
// 5、封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(1);
// 6、提交job给yarn
boolean res = job.waitForCompletion(true);
System.exit(res?0:-1);
}
}
实验5 序列化、分区
1. 结果不正确,字段无法进行分片
Writable序列化的时候readfields()有问题
@Override
public void readFields(DataInput input) throws IOException {
// 反序列化
this.empno = input.readInt();
this.ename = input.readUTF();
this.job = input.readUTF();
this.mgr = input.readInt();
this.hiredate = input.readUTF();
this.sal = input.readInt();
this.comm = input.readInt();
this.deptno = input.readInt();
}
没有重写 testing()
@Override
public String toString() {
return "Employee [empno=" + empno + ", ename=" + ename + ", sal=" + sal + ", deptno=" + deptno + "]";















 715
715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









