






Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image
相关:
Getting Start
这篇文献介绍了一种新技术 SMPLify。通过使用 SMPLify,我们可以在不进行手工标注特征的情况下将一幅单纯 2D 的人体姿势图像转化为对应的 3D 模型。首先,作者使用了一个名为 DeepCut 的 CNN 来提取 2D 图像输入的特征关节点,但此时的关节点是缺乏深度信息的。作者接下来对上一步获得的 2D 关节点使用他们先前提出的 SMPL 模型来生成对应的 3D 模型,然后通过 Powell’s dogleg method(狗腿算法) 来优化 3D 模型的关节点,最后获得所需要的输出。
DeepCut
在正式介绍 SMPLify 的内容前,我想先简略地描述一下 SMPLify 所用到的两个重要的工具。DeepCut 是一个 CNN,它首先提取图片中的 body part candidates(人体部件候选区域),然后令每一个候选区域对应一个关节点,令每一个关节点作为图中的一个节点。接下来,DeepCut 将属于同一个人的关节点归位一类,同时标记每一个节点属于哪一个人体部分。最后,分别将同一类中拥有不同标记的节点组合成一个人的姿态估计。
这种姿态估计的文章涉及到很多新的知识点,很难在一时半刻完全掌握 DeepCut 的内容,所有这里就暂时不进行过多的介绍了。在这篇文章中,我们只需要知道,DeepCut 可以提取出 2D 人像中的关节点,并对这些关节点计算出对应的自信度。实际上,目前已有名为 Deepercut,它貌似在效率与效果上都对 DeepCut 进行了改进,如果在 SMPLify 上应用 Deepercut 的话,或许能获得更好的效果。但考虑到我们项目的主要方向是 fashion style generator,在此就暂时不深究这方面的内容的(如果日后要寻求进一步的改善的话,Deepercut 技术或许是一个很好的 alternative),我们只需要探讨如何把 SMPLify 应用到自己的项目中即可。
此处是一些相关的阅读材料:DeepCut: Joint subset partition and labeling for multi person pose estimation、DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model。
SMPL
SMPL 是一种基于参数化模型的人体建模方法,它由 Loper et al. 所提出。要彻底弄清楚 SMPL 的优势需要大量的背景知识,我们这里只需先了解它的一些基本信息。在 SMPL 中,一个 3D 模型可以被 β 与 θ 表示,其中,β 为 body shape(即人体的高矮胖瘦、头身比例等 10 个参数),θ 为 body pose(即人体整体运动位姿和 24 个关节的相对角度,共 75 个参数)。
此处是一些相关的阅读材料:SMPL: A Skinned Multi-Person Linear Model、SMPL official website。
SMPLify
Introduction
SMPLify 在 2016 由 Bogo et al. 提出,它能将一张 2D 人像转化为对应的 3D 模型,并在包含众多复杂姿势的 Leeds Sports Pose Dataset 中取得了不错的成果,其官方网站为:SMPLify official website。
我们可以从一下的效果图中观察到,SMPLify 的确能在处理 2D 人像转化为对应的 3D 模型的问题上有优秀的表现,同时,它的最大优点在于不需要进行手动特征标注即可获得很好的转换效果(尽管如此,手动进行性别标注可以获得更好的效果)。

SMPLify 的人体模型可以表示为 M(β, θ, γ),其中:β 表示 shape 参数;θ 表示 pose 参数;γ 表示相
机的空间变换参数。SMPLify 的输出 M 是由 6890 个顶点构成的三角网格,且 β 与 θ 的定义与SMPL 中的定义一致。SMPLify 包含了 3 个模版模型,使用 2000 个男性 registration 与 2000 个女性 registration 来训练出两个 gender-specific 模型 (粉色) 与一个 gender-neutral 模型 (蓝色)。
模型的姿势变换是通过 24 个关节点的骨骼蒙皮实现的,θ 是每个关节点的相对旋转角。最开始,我们能从模版模型中获得 3D 关节点与网格顶点的初始位置。然后,我们通过 β 计算出考虑人体体型后的关节位置,记为 J(β)。之后,我们通过 θ 计算出考虑姿势变换后的关节点位置,记为 R(J(β), θ)。我们还需要注意 LSP 关节点与 SMPL 关节点有一定的差异,无法构建出双射关系。因此,我们将 LSP 关节点与SMPL 关节点中相似度最高的点联系在一起。最后,我们使用 perspective camera model 把SMPL 关节点投影到图片上,我们把相机的投影参数记为 K。LSP 关节点与 SMPL 关节点标号的对应关系如下:
| index | joint name | corresponding SMPL joint ids |
|---|---|---|
| 0 | Right ankle | 8 |
| 1 | Right knee | 5 |
| 2 | Right hip | 2 |
| 3 | Left hip | 1 |
| 4 | Left knee | 4 |
| 5 | Left ankle | 7 |
| 6 | Right wrist | 21 |
| 7 | Right elbow | 19 |
| 8 | Right shoulder | 17 |
| 9 | Left shoulder | 16 |
| 10 | Left elbow | 18 |
| 11 | Left wrist | 20 |
| 12 | Neck | - |
| 13 | Head top | vertex 411 (see line 233:fit_3d.py) |
考虑到 LSP 与 SMPL 对 hips 的定义有较大的差异,且 SMPL 缺少对 neck 与 head top 的定义, 我们有可能能构建更好的映射关系。
而 DeepCut 关节点的输出格式如下:
The pose in 5x14 layout. The first axis is along per-joint information,
the second the joints. Information is:
1. position x,
2. position y,
3. CNN confidence,
4. CNN offset vector x,
5. CNN offset vector y.
Method
首先,我们先通过一张图片来加深对 SMPLify 实现流程的初步认识:
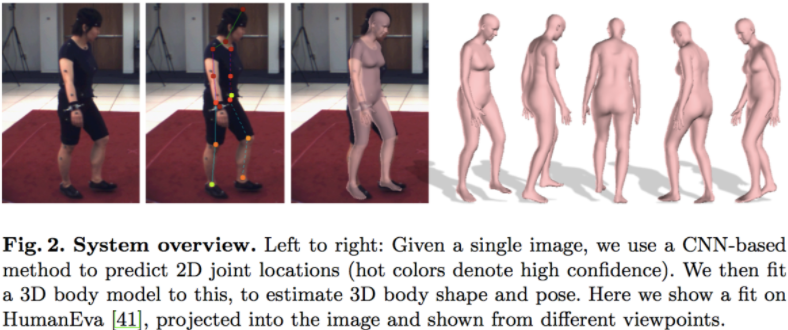
SMPLify 先接收到一张 2D 的人像图片,除了性别信息外,我们不需要再提供其他的额外信息。接下来,我们使用之前提及过的 DeepCut 网络来获得 2D 人像的节点信息。之后,我们使用 SMPL 来生成对应的 3D 模型,并通过 Powell’s dogleg method 来最小化生成模型的节点与 2D 人像节点的误差,从而获得最优的模型。
SMPL 人体模型可表示为 M(β,θ,γ) 的形式,其中,β 为 body shape,θ 为 body pose,γ为 translation(事实上,我们可以从后文中的值,这里的 translation 即为 camera translation)。需要注意的是,DeepCut 所输出的节点数目与 SMPL 输出的节点数目略有不同,作者这里将两种方法中相近的节点联系在了一起。
Approximating Bodies with Capsules
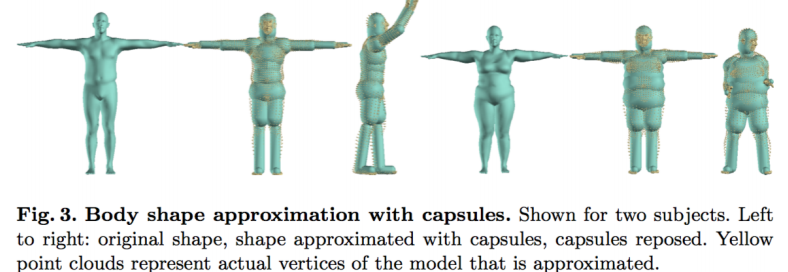
为了避免 interpenetration(即人体模型出现不自然的姿势,人的肢体不正常地相交在了一起),我们往往需要进行额外的计算,而计算人体表面的 interpenetration 的开销是非常大的,作者因此使用了capsule(胶囊体) 来近似人体模型的不同部分。在这里,作者使用了回归的方式完成从 body shape 与 body pose 到 capsule 的转换。
##Objective Function
这部分属于文章的重点内容,我们首先介绍 Powell’s dogleg method 中用到的目标函数 E(β, θ),它是 5 个不同误差项的加权和:

在这条公式中,β 与 θ 已经解释过了,Jest 代表从 DeepCut 获得的 2D 节点,K 代表摄像机参数,四个不同 λ 代表各个子误差的权重。
我们使用关节点误差项 (joint-based data term) 来惩罚预测关节点与 2D 关节点的加权距离和。其中,ΠK 表示预测 3D 关节点根据摄像机投影参数 K 得到的 2D 投影关系。根据不同 2D 关节点的预测自信度 wi,我们在误差项中为其赋予不同的比重。最后,我们使用 Geman-McClure 范数来代表预测关节点与 2D 关节点的距离,借此来改善处理模糊输入图片时的表现。
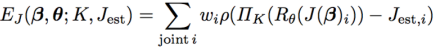
对于 joint-based error term,我们可以将其理解成直接计算对应节点间的误差。J(β)i 表示根据 body shape 所获得的 3D 骨骼节点位置的预测;Rθ(J(β)i) 表示 3D 姿势节点,而 3D 姿势节点是通过 3D 骨骼节点进行变换获得的。在获得 3D 姿势节点后,我们使用 ΠK 将其投影到 2D 上,当中的 K 可以近似理解为视角。然后,我们使用 Geman-McClure 范数来表示模型节点与实际 2D 节点的误差,并使用从 DeepCut 获得的节点的自信度 wi 作为节点误差的权值。最后,joint-based error term 等于每个节点误差的加权和。
上文也提到 interpenetration 的问题,而为了解决这个问题,我们需要引入一个基于先验知识的误差项。这里的 i 代表与膝盖弯曲、肘部弯曲有关的姿势节点。这里的 θ 代表 rotation 的角度,正常情况下,θ 为负值,则 0 < exp(θ) < 1;若 θ 为正值,意味着发生了不自然的扭转,exp(θ) 一般将 » 1。需要注意的是,θ 在不发生旋转时等于 0。
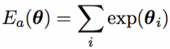
为了进一步淘汰掉不正常的姿势,我们可以预先为模型设定一些 favorable pose(可以理解成较为常见的姿势)。作者在 CMU marker dataset 上通过 MoSh 来获得一系列的 SMPL 模型,然后用这些模型来建立若干个高斯分布。然后在误差项中,gj 代表 8 个高斯分布中的第 j 个,正常情况下,我们需要计算所有高斯分布的加权概率和的负对数,但这种做法在运算上的开销非常大,我们可以用所有高斯分布中最大的加权概率来代替所有高斯分布的加权概率和。因此,我们引入一个常量 c 来抵消这种近似带来的影响。为了节省计算量,作者仅对高斯映射过程中偏离最大的值取对数作为误差。
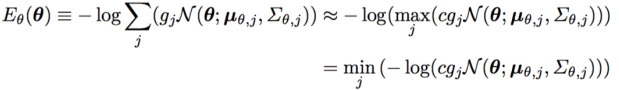
之前也有提到用 capsule 来近似人体部分,并借此避免 interpenetration 的问题,这里给出了其误差计算方法。我们进一步将 capsule 近似为 sphere,这里的 C(θ,β) 代表胶囊的中心坐标,r(β) 代表胶囊的半径,σ(β) 等于 r(β)/3。I(i) 则是对于第 i 个球体,与其不相容的球体的集合。这里比较的主要是两个球体的圆心距和半径和,比较这两者的大小可以获得两个球体的位置关系,从而达到惩罚 interpenetration 的作用。说实话,我这里不太明白 3D isotropic Gaussian 的作用,还需要进一步学习才能彻底理解这一步的操作。
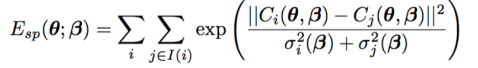
最后,作者定义了一个 shape error term 来衡量 body shape 的误差。这里使用了 PCA(即 Principal Component Analysis,主成分分析,用以消除变量间的关联性) 的方法来获得 error term。
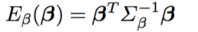
Optimization
由于拍照的角度是不确定的,输入的人像未必正对着拍照平面,因此,我们需要引入 γ(camera translation) 来进一步优化模型。首先,我们可以比较容易地从人像图片中获取到摄像机的大致焦距,然后使用相似三角形的方法计算出人体的大致深度(即根据 3D 模型躯干节点长度与 2D 躯干节点长度的比值估算深度)。然后在正式计算前,先使用 Ej 对 γ 进行优化。
接下来,可以正式开始将 2D 人像转化为 3D 模型。在这个过程中,作者发现为 λθ 与 λβ 设置较高的初始值并让它们逐渐衰减能有效避免结果陷入局部最优。
在最开始的时候,我们是无法得知人体的朝向的,所以当 2D 节点中的肩距小于某一个值时,我们可以认定当前人像并没有正对着镜头,我们尝试选择人体朝向,并筛选出较优的角度。
最后,使用 Powell’s dogleg method 获得一组最优的 3D 节点,整个过程仅需 1 分钟即可完成。
Evaluation
考虑到实际情况中,一幅 2D 图片很少会带有一个 ground truth 的 3D 模型,作者在此同时使用了 synthetic data 与 real data 来进行评估。
在 synthetic data 部分中,作者先从一系列 SMPL 模型中获取到 2D 节点,并对这些 synthetic data 添加随机的高斯噪声,然后以 synthetic data 为输入,通过上述方法对模型进行评估。且外,作者还假设已知 body pose,在此基础上尝试用尽量少的节点来表示 body shape。这部分的结果如下图所示:
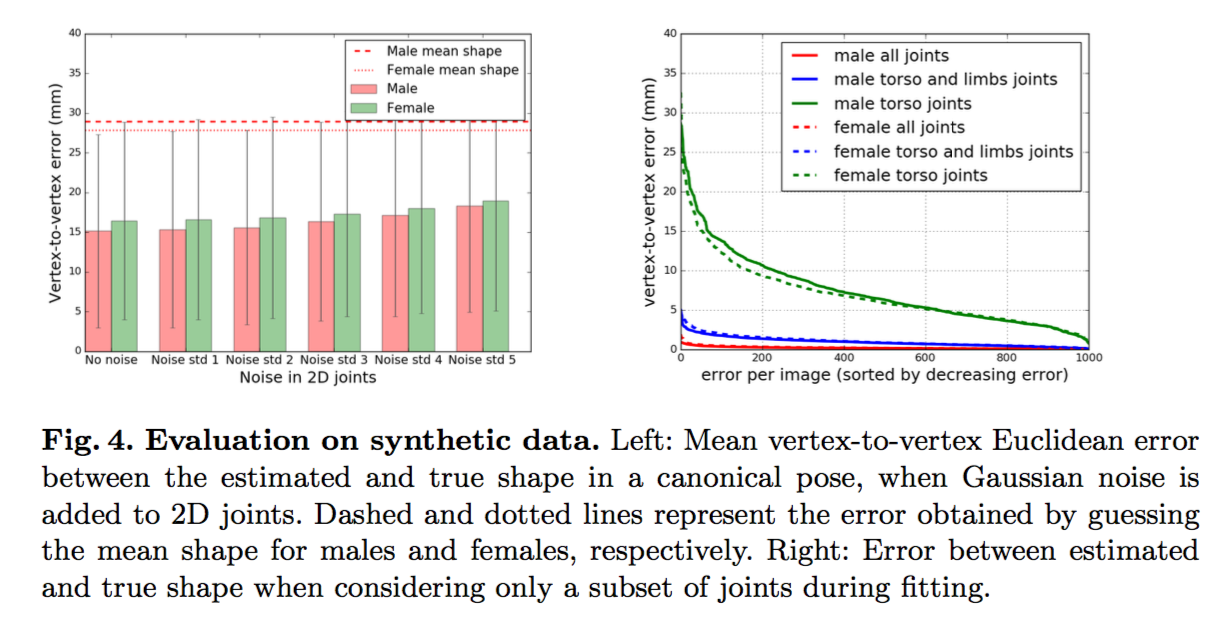
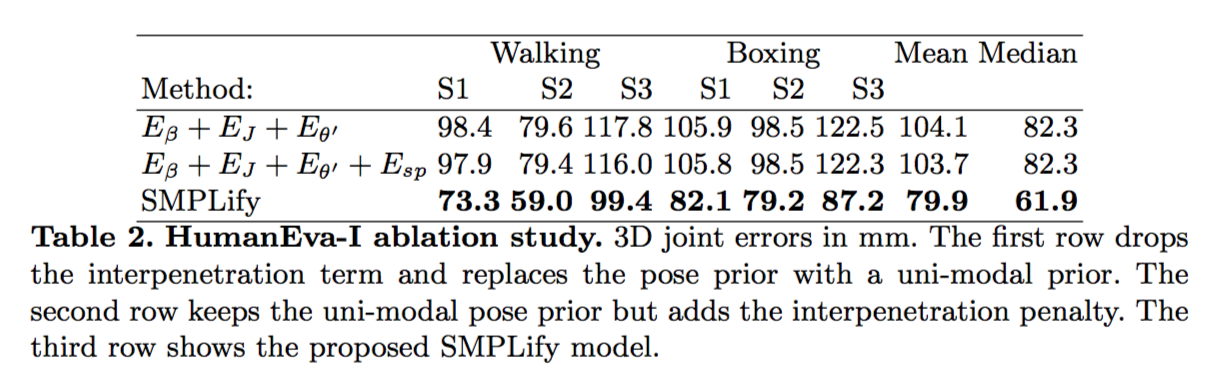
在 real data 部分中,作者分别在 HumanEva-I.、Human3.6M.、Leeds Sports Dataset. 训练集上与其他模型进行了对比评估。一系列的数据表明,SMPLify 要优于其他一些比较先进的模型的,这里只需留意一下数据即可。
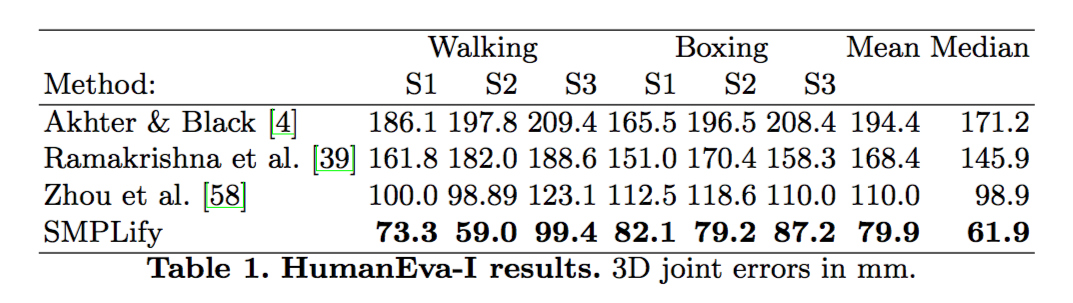
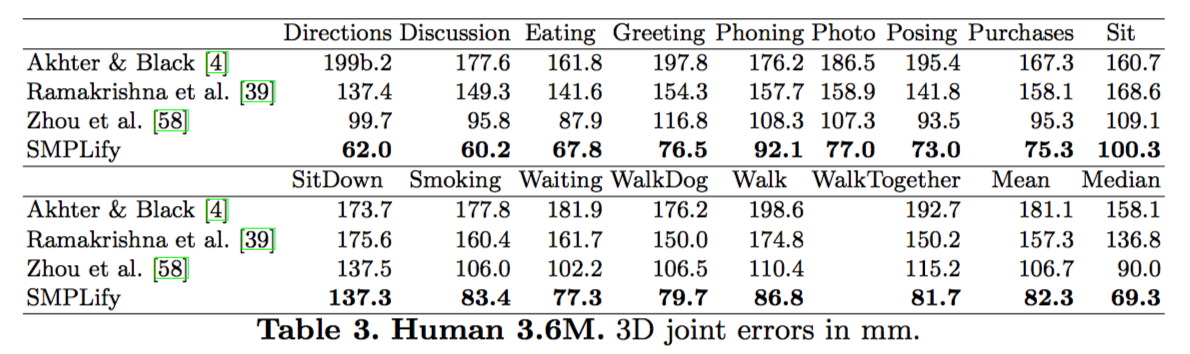
同时,作者也用实验数据证明了,multi-modal pose prior 与 interpenetration error term 能显著提升模型的表现。
接下来也附上一些视觉可见的结果来辅助证明 SMPLify 的优势。我们可以观察到,SMPLify 不仅在一些简单姿势上能获得明显优于其他模型的效果,SMPLify 在处理复杂的运动姿势时依然也能给出很好的表现。


而 SMPLify 也存在失败的情况,在处理 Leeds Sports Dataset. 时 SMPLify 也会生成错误的模型,在此可以简单对失效情况进行概括。可能失效的情况包括:不同四肢的高度重叠、在缺少深度信息情况下不同人物的重叠、无法正确分辨人物朝向。在这当中,我认为第一二种失效情况是比较难解决的;而相对的第三种情况可以通过在测量出的 2D 节点肩距小于某个值时,多尝试几组不同的可能人体朝向角度,而不是仅以 180° 作为步长。

Conclusion
总的来说,SMPLify 能仅依靠单纯的 2D 图像输入获得不俗的 3D 建模结果。实际上,我可能不需要思考如何对 SMPLify 进行改进,而是去思考如何在自己的项目中应用 SMPLify。在我看来,目前的 image-based virtual try-on network 的最大问题在于无法处理复杂的姿势与大幅度的形变,且外,在结果上看,输出也只是单纯的风格迁移,并没能保留服装的一些三维信息。如果我们把 SMPLify 的输出作为 image-based virtual try-on network 输入的深度信息的话,我们或许可以获得更加理想的结果(这一步可以参考目前一些需要用到深度信息的试衣系统,这些系统通常有不错的效果,只是实用性不高,如果使用 SMPLify 的话,就有可能将一个需要深度测量的问题转化为一个 2D 图像处理问题)。
实现
前期准备
CPM和SMPL模型的下载安装参考https://blog.csdn.net/tinghw/article/details/88782572#cpm%E6%A8%A1%E5%9E%8B%EF%BC%9A
需要注意的是SMPL的代码有两个,一个是原始的模型代码http://smpl.is.tue.mpg.de/,一部分是使用SMPL的代码http://smplify.is.tuebingen.mpg.de/faq,不要讲二者搞混了,具体的使用和安装流程在后者的FAQ里讲得已经很清楚了,根据自己的具体情况略微调整即可
分析CPM
models里存放的是CPM原始模型,test_imgs存放的是输入图片,utils里是工具类,其他的都是demo文件,没有特殊要求的情况下我们可以直接使用demo来运行得到我们所要joints点的位置(没有置信度),为14×2的列表。
分析SMPL
分析文件夹结构

smplify_public下

1. requirements里包含需要提前安装的python库,其中opendr库可以先`sudo apt-get install libosmesa6-dev`,`pip3 install opendr==0.78` 小伙伴亲测python3大概率装不上,可以自己改也可以去网上搜python3下的SMPL代码
2. venv是README里提示搭建的一个独立环境virtualvenv,我是直接装在conda虚拟环境里
3. images链接了原始图片
4. results里存放的其实是运行前需要自己设置的参数

est_joints.npz存放的就是人体的关节点信息,也就是我们通过CPM模型得到的关节点位置
lsp_gender.csv里指定了输入图片的性别,从而使之运行时自动调用不同性别的人体模型参数
meshes.hdf5是原有的模型参数,我们这里可以暂时不用管它,有没有都没有关系
5. code里是运行代码

fit_3d.py是运行的主程序,render_model.py是渲染模型的程序,models文件夹里存放的就是SMPL模型
得到任意图片的SMPL模型结果
1. 将kuli.jpg放入test_imgs下,将demo_body_cpm.py中的图片途径改为输入图片的路径
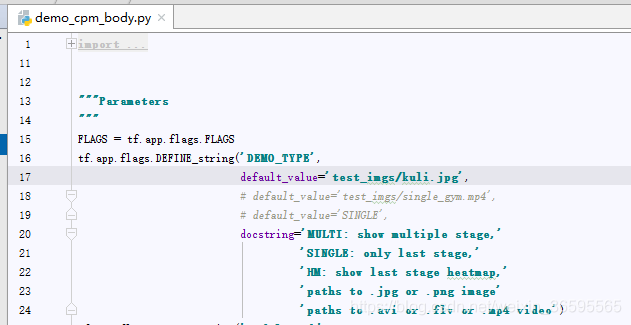
运行demo_body_cpm.py程序,得到关节点的标注图片和关节点信息,我们把关节点信息存为.npy文件以备后续使用

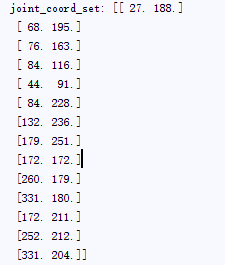
CPM结果的节点顺序是(头部,脖子,左肩,左肘,左臂,右肩,右肘,右臂,左胯,左膝,左脚,右胯,右膝,右脚)
2. SMPL要求的输入的顺序是( Right ankle,Right knee,Right hip,Left hip, Left knee, Left ankle,Right wrist, Right elbow,Right shoulder, Left shoulder, Left elbow ,Left wrist, Neck ,Head top),节点信息要存储在/smplify_public/results/est_joints.npz中,我们把上面得到的数据按这个顺序重写一下然后替换est_joints.npz,并修改性别文件,lsp_gender.csv,最后把自己的图片放到image指向的链接文件夹中
因为这个官方的CPM中的三个模型文件要用googledrive下载,所以我用了民间的代码来得到est_joints.npy。我用的代码的得到的点的顺序跟smplify的输入顺序是一样的所以不用改顺序。
https://github.com/Chen-Junbao/CPM
googledrive里面的best权重也可以在淘宝客服那里下载
3.得到的.npy换掉est_joints.npz中的前两行,这样对源代码的改动可以将到最小。
读取官方的est_joints.npz:
#-*-coding:utf-8-*-
import numpy as np
npz = np.load('last.npz') # 读出来是这样一个类型numpy.lib.npyio.NpzFile
print type(npz)
print npz.files # 读取npz的'键',是est_joints
ndarray = npz['est_joints']
print ndarray # 读取npz的'值',发现是多维数组
print type(ndarray) # 读取类型
print np.array(ndarray).shape # 多元数组维度是(28, 14, 2000)
转换的代码为:
#-*-coding:utf-8-*-
import numpy as np
array = np.load('est_joints.npy').T # 使之变成2×14
ndarray = np.load('est_joints.npz')['est_joints'] # (28,14,2000)
ndarray[:2, :, 0] = array # 前两行变一下
np.savez('last.npz', est_joints = ndarray)
4. 运行fit_3d.py,得到结果。一张输入图对应一个.pkl输出。

# -*- coding:utf-8 -*-
"""
path: smplify_public/code/fit_3d.py
这个文件是smplify项目的主要文件
"""
from os.path import join, exists, abspath, dirname
from os import makedirs
import logging
import cPickle as pickle
from time import time
from glob import glob
import argparse
import cv2
import numpy as np
import chumpy as ch
from opendr.camera import ProjectPoints
from lib.robustifiers import GMOf
from smpl_webuser.serialization import load_model
from smpl_webuser.lbs import global_rigid_transformation
from smpl_webuser.verts import verts_decorated
from lib.sphere_collisions import SphereCollisions
from lib.max_mixture_prior import MaxMixtureCompletePrior
from render_model import render_model
_LOGGER = logging.getLogger(__name__)
# Mapping from LSP joints to SMPL joints.
# 0 Right ankle右脚踝 8
# 1 Right knee左膝盖 5
# 2 Right hip右胯 2
# 3 Left hip左胯 1
# 4 Left knee左膝盖 4
# 5 Left ankle 7
# 6 Right wrist右手腕 21
# 7 Right elbow右手肘 19
# 8 Right shoulder 17
# 9 Left shoulder 16
# 10 Left elbow 18
# 11 Left wrist 20
# 12 Neck -
# 13 Head top added
# --------------------Camera estimation --------------------
def guess_init(model, focal_length, j2d, init_pose):
"""使用躯干关节通过三角形相似度初始化相机平移 .
:param model: SMPL model
:param focal_length: 相机焦距(保持固定)
:param j2d: 14x2 array of CNN joints
:param init_pose: 用于初始化的姿势参数的 72D 向量(保持固定)
:returns: 对应于估计的相机平移的 3D 向量
"""
cids = np.arange(0, 12)
# map from LSP to SMPL joints
j2d_here = j2d[cids]
smpl_ids = [8, 5, 2, 1, 4, 7, 21, 19, 17, 16, 18, 20]
opt_pose = ch.array(init_pose)
(_, A_global) = global_rigid_transformation(
opt_pose, model.J, model.kintree_table, xp=ch)
Jtr = ch.vstack([g[:3, 3] for g in A_global])
Jtr = Jtr[smpl_ids].r
# 9 is L shoulder, 3 is L hip
# 8 is R shoulder, 2 is R hip
diff3d = np.array([Jtr[9] - Jtr[3], Jtr[8] - Jtr[2]])
mean_height3d = np.mean(np.sqrt(np.sum(diff3d**2, axis=1)))
diff2d = np.array([j2d_here[9] - j2d_here[3], j2d_here[8] - j2d_here[2]])
mean_height2d = np.mean(np.sqrt(np.sum(diff2d**2, axis=1)))
est_d = focal_length * (mean_height3d / mean_height2d)
# just set the z value
init_t = np.array([0., 0., est_d])
return init_t
def initialize_camera(model,
j2d,
img,
init_pose,
flength=5000.,
pix_thsh=25.,
viz=False):
"""Initialize camera translation and body orientation
:param model: SMPL model
:param j2d: 14x2 array of CNN joints
:param img: h x w x 3 image
:param init_pose: 72D vector of pose parameters used for initialization
:param flength: camera focal length (kept fixed)
:param pix_thsh: threshold (in pixel), if the distance between shoulder joints in 2D
is lower than pix_thsh, the body orientation as ambiguous (so a fit is run on both
the estimated one and its flip)
:param viz: boolean, if True enables visualization during optimization
:returns: a tuple containing the estimated camera,
a boolean deciding if both the optimized body orientation and its flip should be considered,
3D vector for the body orientation
"""
# optimize camera translation and body orientation based on torso joints
# LSP torso ids:
# 2=right hip, 3=left hip, 8=right shoulder, 9=left shoulder
torso_cids = [2, 3, 8, 9]
# corresponding SMPL torso ids
torso_smpl_ids = [2, 1, 17, 16]
center = np.array([img.shape[1] / 2, img.shape[0] / 2])
# initialize camera rotation
rt = ch.zeros(3)
# initialize camera translation
_LOGGER.info('initializing translation via similar triangles')
init_t = guess_init(model, flength, j2d, init_pose)
t = ch.array(init_t)
# check how close the shoulder joints are
try_both_orient = np.linalg.norm(j2d[8] - j2d[9]) < pix_thsh
opt_pose = ch.array(init_pose)
(_, A_global) = global_rigid_transformation(
opt_pose, model.J, model.kintree_table, xp=ch)
Jtr = ch.vstack([g[:3, 3] for g in A_global])
# initialize the camera
cam = ProjectPoints(
f=np.array([flength, flength]), rt=rt, t=t, k=np.zeros(5), c=center)
# we are going to project the SMPL joints
cam.v = Jtr
if viz:
viz_img = img.copy()
# draw the target (CNN) joints
for coord in np.around(j2d).astype(int):
if (coord[0] < img.shape[1] and coord[0] >= 0 and
coord[1] < img.shape[0] and coord[1] >= 0):
cv2.circle(viz_img, tuple(coord), 3, [0, 255, 0])
import matplotlib.pyplot as plt
plt.ion()
# draw optimized joints at each iteration
def on_step(_):
"""Draw a visualization."""
plt.figure(1, figsize=(5, 5))
plt.subplot(1, 1, 1)
viz_img = img.copy()
for coord in np.around(cam.r[torso_smpl_ids]).astype(int):
if (coord[0] < viz_img.shape[1] and coord[0] >= 0 and
coord[1] < viz_img.shape[0] and coord[1] >= 0):
cv2.circle(viz_img, tuple(coord), 3, [0, 0, 255])
plt.imshow(viz_img[:, :, ::-1])
plt.draw()
plt.show()
plt.pause(1e-3)
else:
on_step = None
# optimize for camera translation and body orientation
free_variables = [cam.t, opt_pose[:3]]
ch.minimize(
# data term defined over torso joints...
{'cam': j2d[torso_cids] - cam[torso_smpl_ids],
# ...plus a regularizer for the camera translation
'cam_t': 1e2 * (cam.t[2] - init_t[2])},
x0=free_variables,
method='dogleg',
callback=on_step,
options={'maxiter': 100,
'e_3': .0001,
# disp set to 1 enables verbose output from the optimizer
'disp': 0})
if viz:
plt.ioff()
return (cam, try_both_orient, opt_pose[:3].r)
# --------------------Core optimization --------------------
def optimize_on_joints(j2d,
model,
cam,
img,
prior,
try_both_orient,
body_orient,
n_betas=10,
regs=None,
conf=None,
viz=False):
"""Fit the model to the given set of joints, given the estimated camera
:param j2d: 14x2 array of CNN joints
:param model: SMPL model
:param cam: estimated camera
:param img: h x w x 3 image
:param prior: mixture of gaussians pose prior
:param try_both_orient: boolean, if True both body_orient and its flip are considered for the fit
:param body_orient: 3D vector, initialization for the body orientation
:param n_betas: number of shape coefficients considered during optimization
:param regs: regressors for capsules' axis and radius, if not None enables the interpenetration error term
:param conf: 14D vector storing the confidence values from the CNN
:param viz: boolean, if True enables visualization during optimization
:returns: a tuple containing the optimized model, its joints projected on image space, the camera translation
"""
t0 = time()
# define the mapping LSP joints -> SMPL joints
# cids are joints ids for LSP:
cids = range(12) + [13]
# joint ids for SMPL
# SMPL does not have a joint for head, instead we use a vertex for the head
# and append it later.
smpl_ids = [8, 5, 2, 1, 4, 7, 21, 19, 17, 16, 18, 20]
# the vertex id for the joint corresponding to the head
head_id = 411
# weights assigned to each joint during optimization;
# the definition of hips in SMPL and LSP is significantly different so set
# their weights to zero
base_weights = np.array(
[1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], dtype=np.float64)
if try_both_orient:
flipped_orient = cv2.Rodrigues(body_orient)[0].dot(
cv2.Rodrigues(np.array([0., np.pi, 0]))[0])
flipped_orient = cv2.Rodrigues(flipped_orient)[0].ravel()
orientations = [body_orient, flipped_orient]
else:
orientations = [body_orient]
if try_both_orient:
# store here the final error for both orientations,
# and pick the orientation resulting in the lowest error
errors = []
svs = []
cams = []
for o_id, orient in enumerate(orientations):
# initialize the shape to the mean shape in the SMPL training set
betas = ch.zeros(n_betas)
# initialize the pose by using the optimized body orientation and the
# pose prior
init_pose = np.hstack((orient, prior.weights.dot(prior.means)))
# instantiate the model:
# verts_decorated allows us to define how many
# shape coefficients (directions) we want to consider (here, n_betas)
sv = verts_decorated(
trans=ch.zeros(3),
pose=ch.array(init_pose),
v_template=model.v_template,
J=model.J_regressor,
betas=betas,
shapedirs=model.shapedirs[:, :, :n_betas],
weights=model.weights,
kintree_table=model.kintree_table,
bs_style=model.bs_style,
f=model.f,
bs_type=model.bs_type,
posedirs=model.posedirs)
# make the SMPL joints depend on betas
Jdirs = np.dstack([model.J_regressor.dot(model.shapedirs[:, :, i])
for i in range(len(betas))])
J_onbetas = ch.array(Jdirs).dot(betas) + model.J_regressor.dot(
model.v_template.r)
# get joint positions as a function of model pose, betas and trans
(_, A_global) = global_rigid_transformation(
sv.pose, J_onbetas, model.kintree_table, xp=ch)
Jtr = ch.vstack([g[:3, 3] for g in A_global]) + sv.trans
# add the head joint, corresponding to a vertex...
Jtr = ch.vstack((Jtr, sv[head_id]))
# ... and add the joint id to the list
if o_id == 0:
smpl_ids.append(len(Jtr) - 1)
# update the weights using confidence values
weights = base_weights * conf[
cids] if conf is not None else base_weights
# project SMPL joints on the image plane using the estimated camera
cam.v = Jtr
# data term: distance between observed and estimated joints in 2D
obj_j2d = lambda w, sigma: (
w * weights.reshape((-1, 1)) * GMOf((j2d[cids] - cam[smpl_ids]), sigma))
# mixture of gaussians pose prior
pprior = lambda w: w * prior(sv.pose)
# joint angles pose prior, defined over a subset of pose parameters:
# 55: left elbow, 90deg bend at -np.pi/2
# 58: right elbow, 90deg bend at np.pi/2
# 12: left knee, 90deg bend at np.pi/2
# 15: right knee, 90deg bend at np.pi/2
alpha = 10
my_exp = lambda x: alpha * ch.exp(x)
obj_angle = lambda w: w * ch.concatenate([my_exp(sv.pose[55]), my_exp(-sv.pose[
58]), my_exp(-sv.pose[12]), my_exp(-sv.pose[15])])
if viz:
import matplotlib.pyplot as plt
plt.ion()
def on_step(_):
"""Create visualization."""
plt.figure(1, figsize=(10, 10))
plt.subplot(1, 2, 1)
# show optimized joints in 2D
tmp_img = img.copy()
for coord, target_coord in zip(
np.around(cam.r[smpl_ids]).astype(int),
np.around(j2d[cids]).astype(int)):
if (coord[0] < tmp_img.shape[1] and coord[0] >= 0 and
coord[1] < tmp_img.shape[0] and coord[1] >= 0):
cv2.circle(tmp_img, tuple(coord), 3, [0, 0, 255])
if (target_coord[0] < tmp_img.shape[1] and
target_coord[0] >= 0 and
target_coord[1] < tmp_img.shape[0] and
target_coord[1] >= 0):
cv2.circle(tmp_img, tuple(target_coord), 3,
[0, 255, 0])
plt.imshow(tmp_img[:, :, ::-1])
plt.draw()
plt.show()
plt.pause(1e-2)
on_step(_)
else:
on_step = None
if regs is not None:
# interpenetration term
sp = SphereCollisions(
pose=sv.pose, betas=sv.betas, model=model, regs=regs)
sp.no_hands = True
# 论文中使用的权重配置,带有来自 CNN 的关节 + 置信度值(代码中使用的所有权重均通过网格搜索获得,有关详细信息,请参阅论文)第一个列表包含姿势先验的权重,第二个列表包含先验形状的权重
opt_weights = zip([4.04 * 1e2, 4.04 * 1e2, 57.4, 4.78],
[1e2, 5 * 1e1, 1e1, .5 * 1e1])
# 分 4 个 stage 运行优化,逐步降低先验的权重
for stage, (w, wbetas) in enumerate(opt_weights):
_LOGGER.info('stage %01d', stage)
objs = {}
objs['j2d'] = obj_j2d(1., 100)
objs['pose'] = pprior(w)
objs['pose_exp'] = obj_angle(0.317 * w)
objs['betas'] = wbetas * betas
if regs is not None:
objs['sph_coll'] = 1e3 * sp
ch.minimize(
objs,
x0=[sv.betas, sv.pose],
method='dogleg',
callback=on_step,
options={'maxiter': 100,
'e_3': .0001,
'disp': 0})
t1 = time()
_LOGGER.info('elapsed %.05f', (t1 - t0))
if try_both_orient:
errors.append((objs['j2d'].r**2).sum())
svs.append(sv)
cams.append(cam)
if try_both_orient and errors[0] > errors[1]:
choose_id = 1
else:
choose_id = 0
if viz:
plt.ioff()
return (svs[choose_id], cams[choose_id].r, cams[choose_id].t.r)
'''
将运行 DeepCut 的得到的数据与原始人像图片作为参数,传入 SMPLify 的 run_single_fit() 函数。
之后,我们可以获得一个包括以下 key 值的 dict 类型的变量:cam_t、f、pose、betas
'''
def run_single_fit(img,
j2d,
conf,
model,
regs=None,
n_betas=10,
flength=5000.,
pix_thsh=25.,
scale_factor=1,
viz=False,
do_degrees=None):
"""Run the fit for one specific image.
:param img: h x w x 3 image
:param j2d: 14x2 array of CNN joints
:param conf: 14D 向量存储来自 CNN 的置信度值
:param model: SMPL model
:param regs: 胶囊轴和半径的回归量,如果不是 None 启用互穿误差项 interpenetration error term
:param n_betas: 优化过程中考虑的形状系数的数量
:param flength: 相机焦距 (kept fixed during optimization)
:param pix_thsh: 阈值(以像素为单位),如果 2D 中肩关节之间的距离小于 pix_thsh,则身体方向不明确(因此对估计的一个和它的翻转都进行了拟合)
:param scale_factor: int,重新缩放图像(对于 LSP,稍微大一点的图像 -- 2x -- 有助于获得更好的拟合)
:param viz: 布尔值,如果 True 在优化期间启用可视化
:param do_degrees: 保存结果时呈现最终拟合的方位角度数list of degrees
:returns: 包含相机/模型参数和具有渲染拟合的图像的元组
"""
if do_degrees is None:
do_degrees = []
# create the pose prior (GMM over CMU)
prior = MaxMixtureCompletePrior(n_gaussians=8).get_gmm_prior()
# get the mean pose as our initial pose
init_pose = np.hstack((np.zeros(3), prior.weights.dot(prior.means)))
if scale_factor != 1:
img = cv2.resize(img, (img.shape[1] * scale_factor,
img.shape[0] * scale_factor))
j2d[:, 0] *= scale_factor
j2d[:, 1] *= scale_factor
# estimate the camera parameters
(cam, try_both_orient, body_orient) = initialize_camera(
model,
j2d,
img,
init_pose,
flength=flength,
pix_thsh=pix_thsh,
viz=viz)
# fit
(sv, opt_j2d, t) = optimize_on_joints(
j2d,
model,
cam,
img,
prior,
try_both_orient,
body_orient,
n_betas=n_betas,
conf=conf,
viz=viz,
regs=regs, )
h = img.shape[0]
w = img.shape[1]
dist = np.abs(cam.t.r[2] - np.mean(sv.r, axis=0)[2])
images = []
orig_v = sv.r
for deg in do_degrees:
if deg != 0:
aroundy = cv2.Rodrigues(np.array([0, np.radians(deg), 0]))[0]
center = orig_v.mean(axis=0)
new_v = np.dot((orig_v - center), aroundy)
verts = new_v + center
else:
verts = orig_v
# now render
im = (render_model(
verts, model.f, w, h, cam, far=20 + dist) * 255.).astype('uint8')
images.append(im)
# return fit parameters
'''
cam_t 是摄像机的平移;
f 是摄像机的焦距;
pose 是 SMPL 模型的 pose 参数;
betas 是 SMPL 模型的shape 参数。
'''
params = {'cam_t': cam.t.r,
'f': cam.f.r,
'pose': sv.pose.r,
'betas': sv.betas.r}
return params, images
def main(base_dir,
out_dir,
use_interpenetration=True,
n_betas=10,
flength=5000.,
pix_thsh=25.,
use_neutral=False,
viz=True):
"""Set up paths to image and joint data, saves results.
:param base_dir: folder containing LSP images and data
:param out_dir: output folder
:param use_interpenetration: boolean, if True enables the interpenetration term
:param n_betas: number of shape coefficients considered during optimization
:param flength: camera focal length (an estimate)
:param pix_thsh: threshold (in pixel), if the distance between shoulder joints in 2D
is lower than pix_thsh, the body orientation as ambiguous (so a fit is run on both
the estimated one and its flip)
:param use_neutral: boolean, if True enables uses the neutral gender SMPL model
:param viz: boolean, if True enables visualization during optimization
"""
img_dir = join(abspath(base_dir), 'testimages/')
print img_dir
data_dir = join(abspath(base_dir), 'results/test')
print data_dir
if not exists(out_dir):
makedirs(out_dir)
_LOGGER.info("make out dir")
# Render degrees: List of degrees in azimuth to render the final fit.
# Note that rendering many views can take a while.
do_degrees = [0.]
sph_regs = None
if not use_neutral:
_LOGGER.info("Reading genders...")
# File storing information about gender in LSP
with open(join(data_dir, 'lsp_gender.csv')) as f:
genders = f.readlines()
model_female = load_model(MODEL_FEMALE_PATH)
model_male = load_model(MODEL_MALE_PATH)
if use_interpenetration:
sph_regs_male = np.load(SPH_REGS_MALE_PATH)
sph_regs_female = np.load(SPH_REGS_FEMALE_PATH)
else:
gender = 'neutral'
model = load_model(MODEL_NEUTRAL_PATH)
if use_interpenetration:
sph_regs = np.load(SPH_REGS_NEUTRAL_PATH)
# Load joints
est = np.load(join(data_dir, 'last.npz'))['est_joints']
# Load images
img_paths = sorted(glob(join(img_dir, '*[0-9].jpg')))
for ind, img_path in enumerate(img_paths):
out_path = '%s/%04d.pkl' % (out_dir, ind) # outpath是对应图片生成的.pkl模型文件路径
if not exists(out_path):
_LOGGER.info('Fitting 3D body on `%s` (saving to `%s`).', img_path,
out_path)
img = cv2.imread(img_path)
if img.ndim == 2:
_LOGGER.warn("图像是灰度的!")
img = np.dstack((img, img, img))
# joints坐标只是est里的前两行,置信度是第三行
joints = est[:2, :, ind].T
conf = est[2, :, ind]
if not use_neutral:
gender = 'male' if int(genders[ind]) == 0 else 'female'
if gender == 'female':
model = model_female
if use_interpenetration:
sph_regs = sph_regs_female
elif gender == 'male':
model = model_male
if use_interpenetration:
sph_regs = sph_regs_male
params, vis = run_single_fit(
img,
joints,
conf,
model,
regs=sph_regs,
n_betas=n_betas,
flength=flength,
pix_thsh=pix_thsh,
scale_factor=2,
viz=viz,
do_degrees=do_degrees)
print params
if viz:
import matplotlib.pyplot as plt
plt.ion()
plt.show()
plt.subplot(121)
plt.imshow(img[:, :, ::-1])
if do_degrees is not None:
for di, deg in enumerate(do_degrees):
plt.subplot(122)
plt.cla()
plt.imshow(vis[di])
plt.draw()
plt.title('%d deg' % deg)
plt.pause(1)
raw_input('Press any key to continue...')
with open(out_path, 'w') as outf:
pickle.dump(params, outf)
# This only saves the first rendering.
if do_degrees is not None:
cv2.imwrite(out_path.replace('.pkl', '.png'), vis[0])
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
parser = argparse.ArgumentParser(description='run SMPLify on LSP dataset')
parser.add_argument(
'base_dir',
default='/scratch1/projects/smplify_public/',
nargs='?',
help="Directory that contains images/lsp and results/lps , i.e."
"the directory you untared smplify_code.tar.gz")
parser.add_argument(
'--out_dir',
default='/tmp/smplify_lsp/',
type=str,
help='Where results will be saved, default is /tmp/smplify_lsp')
parser.add_argument(
'--no_interpenetration',
default=False,
action='store_true',
help="Using this flag removes the interpenetration term, which speeds"
"up optimization at the expense of possible interpenetration.")
parser.add_argument(
'--gender_neutral',
default=False,
action='store_true',
help="Using this flag always uses the neutral SMPL model, otherwise "
"gender specified SMPL models are used.")
parser.add_argument(
'--n_betas',
default=10,
type=int,
help="Specify the number of shape coefficients to use.")
parser.add_argument(
'--flength',
default=5000,
type=float,
help="Specify value of focal length.")
parser.add_argument(
'--side_view_thsh',
default=25,
type=float,
help="This is thresholding value that determines whether the human is captured in a side view. If the pixel distance between the shoulders is less than this value, two initializations of SMPL fits are tried.")
parser.add_argument(
'--viz',
default=False,
action='store_true',
help="Turns on visualization of intermediate optimization steps "
"and final results.")
args = parser.parse_args()
use_interpenetration = not args.no_interpenetration
if not use_interpenetration:
_LOGGER.info('Not using interpenetration term.')
if args.gender_neutral:
_LOGGER.info('Using gender neutral model.')
# Set up paths & load models.
# Assumes 'models' in the 'code/' directory where this file is in.
MODEL_DIR = join(abspath(dirname(__file__)), 'models')
# Model paths:
MODEL_NEUTRAL_PATH = join(
MODEL_DIR, 'basicModel_neutral_lbs_10_207_0_v1.0.0.pkl')
MODEL_FEMALE_PATH = join(
MODEL_DIR, 'basicModel_f_lbs_10_207_0_v1.0.0.pkl')
MODEL_MALE_PATH = join(MODEL_DIR,
'basicmodel_m_lbs_10_207_0_v1.0.0.pkl')
if use_interpenetration:
# paths to the npz files storing the regressors for capsules
SPH_REGS_NEUTRAL_PATH = join(MODEL_DIR,
'regressors_locked_normalized_hybrid.npz')
SPH_REGS_FEMALE_PATH = join(MODEL_DIR,
'regressors_locked_normalized_female.npz')
SPH_REGS_MALE_PATH = join(MODEL_DIR,
'regressors_locked_normalized_male.npz')
main(args.base_dir, args.out_dir, use_interpenetration, args.n_betas,
args.flength, args.side_view_thsh, args.gender_neutral, args.viz)
后面输出的一个字典是SMPLify 代码中fit_3d.py中的 run_single_fit() 函数所返回的值。返回params和渲染好的smpl模型二维图image,其中params是以下 key 值的字典:cam_t、f、pose、betas
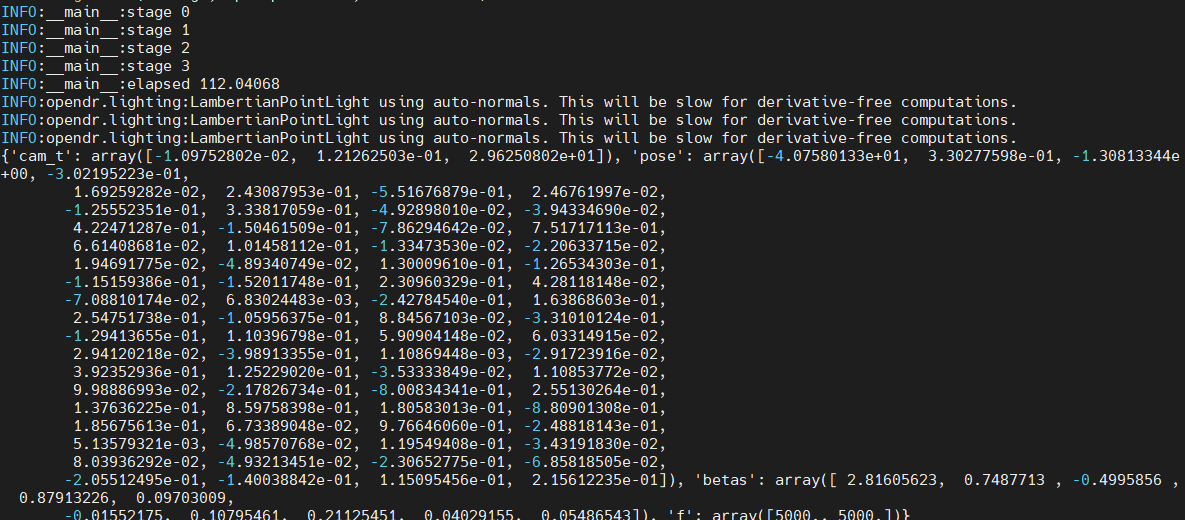
cam_t 是摄像机的平移;f 是摄像机的焦距;pose 是 SMPL 模型的 pose 参数;betas 是 SMPL 模型的shape 参数。如果我们只想实现 3D 上的虚拟试衣,那么我们没必要关注cam_t 与 f;如果我们想要在实现完 3D 上的虚拟试衣后把试衣结果贴回原图像上,我们需要在最后使用 cam_t 与 f 来求解摄像机。这些信息作为parameters的全部内容保存在输出的.pkl中。
当我们想要通过 pose 与 betas 还原出对应的 SMPL 模型的.obj文件时,我们可以直接加载smplify_public/smpl_webuser/hello_word/hello_smpl.py中的load_model函数来加载smpl模板模型,
然后把 model 的 pose 与 betas 参数修改成我们先前得到的.pkl 输出中对应的键值,最后输出成 obj 文件。
'''
path: smplify_public/smpl_webuser/hello_word/hello_smpl.py
'''
from smpl_webuser.serialization import load_model
import numpy as np
## Load SMPL model (here we load the female model)
## Make sure path is correct
m = load_model( '../models/basicModel_f_lbs_10_207_0_v1.0.0.pkl' )
## Assign random pose and shape parameters
m.pose[:] = np.random.rand(m.pose.size) * .2
m.betas[:] = np.random.rand(m.betas.size) * .03
## Write to an .obj file
outmesh_path = './hello_smpl.obj'
with open( outmesh_path, 'w') as fp:
for v in m.r:
fp.write( 'v %f %f %f\n' % ( v[0], v[1], v[2]) )
for f in m.f+1: # Faces are 1-based, not 0-based in obj files
fp.write( 'f %d %d %d\n' % (f[0], f[1], f[2]) )
## Print message
print '..Output mesh saved to: ', outmesh_path

















 69
69

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









