







一、最小距离分类
在统计模式识别中,可以采用最小距离分类器,它是计算待分类的样本到各个已知类别的中心(通常是训练集中同类样本的重心)的距离,将其划分到据它最近的类别中去,这可以看做是一种最近邻的分类规则。
二、最近邻分类器
最近邻分类器是在最小距离分类的基础上进行拓展,将训练集中的每一个样本作为判别依据,找出和测试样例属性比较接近的所有训练样例,这些训练样例被称为最近邻,可以用来确定测试样例的类标号。
这和“物以类聚,人以群分”是一个道理。最近邻分类器把每个训练样例看做d维空间上的一个点,其中d是属性个数,给定一个测试样例z,计算z与每个训练样例的邻近度,找出与之最近的k个训练样例,将这k个训练样例中出现最多的类标号赋给z。
对比:
一般的分类器,比如决策树和支撑向量机,只要有训练数据可用,它们就开始学习从输入属性到类标号的映射模型,这类学习策略被称为积极学习方法。
与之相对的是消极学习算法,它的策略是推迟对训练数据的建模,在需要分类测试样例时再进行。消极学习的一个例子是Rote分类器,它记住整个训练集,只有当测试样例和某个训练样例完全匹配时才进行分类。这个分类算法有个明显的缺陷就是经常会出现测试样例不能被分类的情况,因为没有任何训练样例与它们匹配。最近邻分类器是对Rote分类器的改进。
三、计算步骤
1、算距离:给定测试对象,计算它与训练集中每个对象的距离
2、找邻居:圈定距离最近的 k个对象,作为测试对象的近邻
3、做分类:根据这k个近邻归属的主要类别,来对测试对象分类
四、有关K的取值
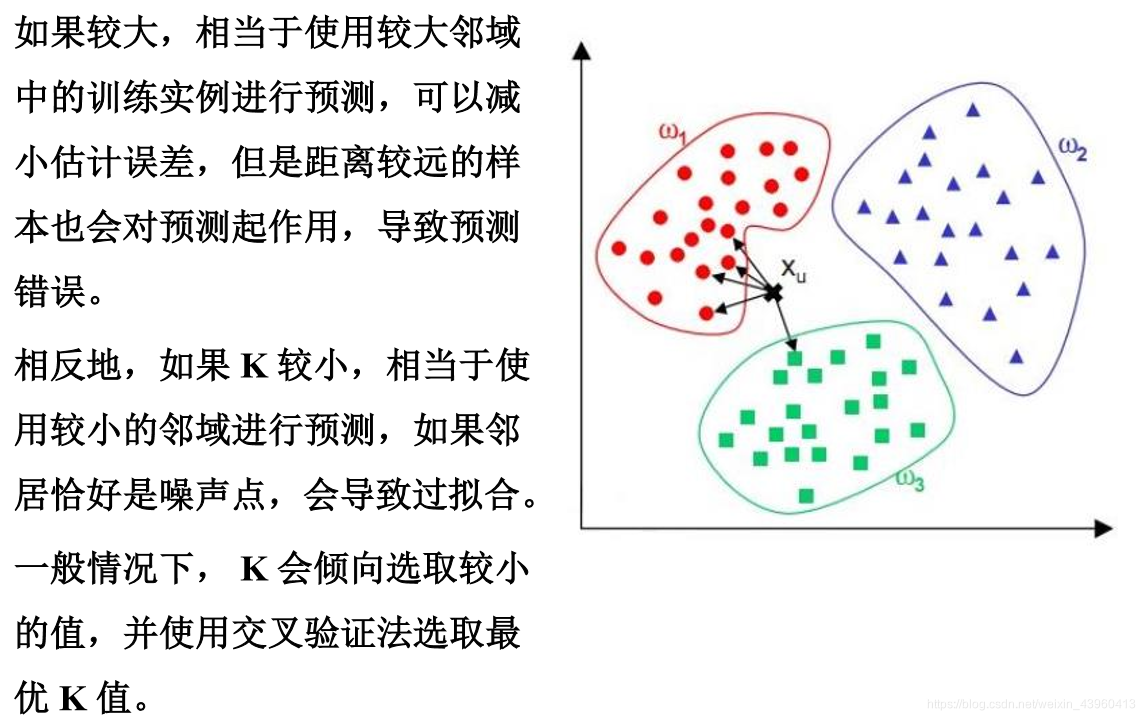
要降低k的选择造成的影响,一种途径就是根据每个最近邻xi距离的不同对其作用加权:
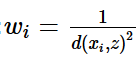
这样,距离较远的最近邻对分类结果的影响就相对较小。
五、最近邻分类器的优缺点
最近邻分类器的优点
- 不需要为训练集建立模型。
- 最近邻分类器可以生成任何形状的决策边界。
最近邻分类器的缺点
- 容易受到噪声的影响。
- 往往需要对训练集进行预处理才能使用。
- 每一次分类耗时长。
六、代码实现-sklearn中的K近邻分类器
#创建一组数据 X 和它对应的标签 y:
>>> X = [[0], [1], [2], [3]]
>>> y = [0, 0, 1, 1]
#使用 import 语句导入 K 近邻分类器。
>>> from sklearn.neighbors import KNeighborsClassifier
#使用最近的3个邻居作为分类的依据
>>> neigh = KNeighborsClassifier(n_neighbors=3)
#调用 fit() 函数,将训练数据 X 和 标签 y 送入分类器进行学习
>>> neigh.fit(X, y)
#对未知样本分类:
>>> print(neigh.predict([[1.1]]))
结果如图:

七、参考文档链接
https://blog.csdn.net/vvcrm01/article/details/80930330
https://blog.csdn.net/tyzttzzz/article/details/41695007
https://blog.csdn.net/lihaitao000/article/details/51221344
https://blog.csdn.net/m0_37860003/article/details/96445957
https://www.cnblogs.com/bugsheep/p/7879407.html
https://www.jianshu.com/p/ded20ec93280
https://wenku.baidu.com/view/d0924523a45177232e60a201.html















 678
678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









