







索引的作用
为了提⾼数据查询的效率,原理类似于书的目录
索引的常见类型
- 哈希表:利用链表法解决哈希冲突,在链表里元素无序,因此做区间查询很慢。所以哈希索引一般是用来做单一的元素的等值查找。
- 有序数组:在等值查询和范围查询性能表现都很优秀。但是在插入删除元素时,由于涉及到元素的移动,所以性能表现很差。所以适用于很少执行插入删除操作的静态数据。
- 搜索树(B+树)
B树索引
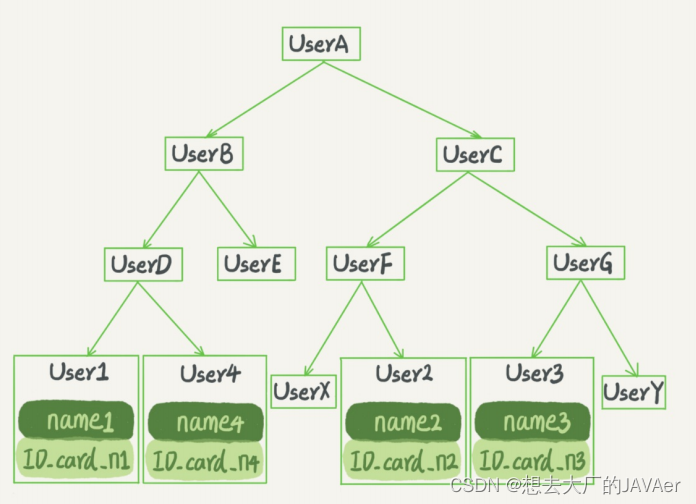
索引被存放在磁盘上,若采用二叉树的方法建立索引的话,树高较高。每次向子节点进行查找时,可能都需要寻址访问新的数据块。为尽量减少读磁盘,则必须让访问过程访问尽量少的数据块。则不用二叉树的树状结构而采用N叉树的结构,可让N适当加大。如当N=1200时,可以令树高为4,则可以存放17亿左右的数据。且由于树根的数据块总是在内存中,则查找一个值最多只需要访问三次磁盘中的数据块。
InnoDB 的索引
InnoDB使⽤了B+树索引模型。
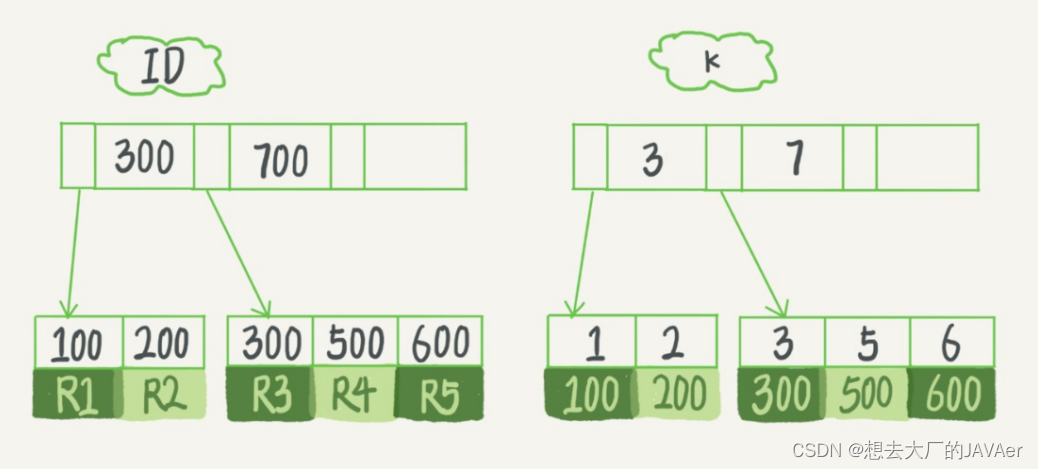
根据叶子结点的内容,可以将索引分为主键索引和非主键索引:
- 主键索引(聚簇索引):主键索引的叶⼦节点存的是整⾏数据。
- 非主键索引:⾮主键索引的叶⼦节点内容是主键的值。
若根据主键字段进行查找时,则会直接扫描主键索引的B+树,得到所要查找的数据;
若根据非主键字段进行查找时,则会先扫描对应的非主键索引的B+树,在叶子节点处得到对应的主键值,再去主键索引的B+树进行查找,得到所需要查找的值。
故在应用中应该尽量采用主键进行查询。
最左前缀匹配原则
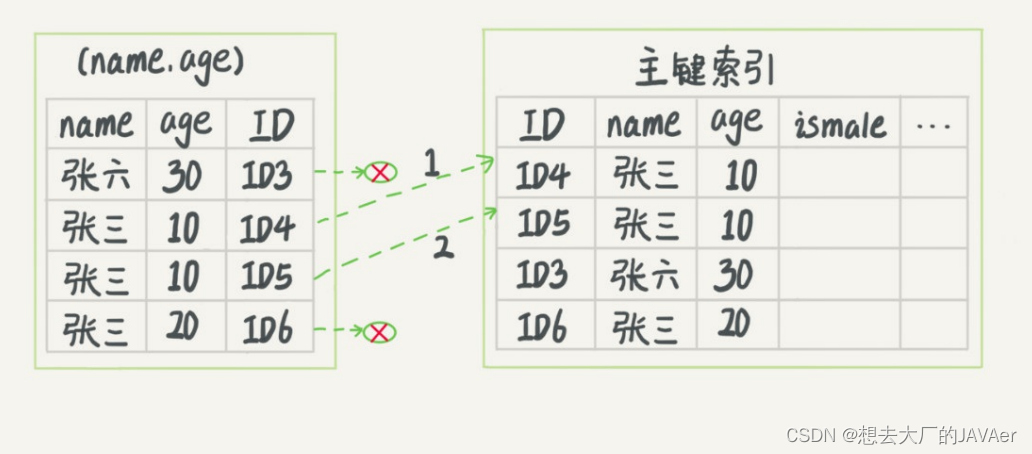
MySQL 建立多列索引(联合索引)有最左匹配的原则,即最左优先:
- 建立一个索引,对于索引中的字段,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,不能跳过中间的字段。比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的。如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
- =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
- 对于联合索引(a,b,c),而采用(b),(b c)和©是不会命中索引的。但(a c)组合可以命中,且只能利用a的索引
如果有一个 2 列的索引 (a, b),则已经对 (a)、(a, b) 上建立了索引;
如果有一个 3 列索引 (a, b, c),则已经对 (a)、(a, b)、(a, b, c) 上建立了索引;
只要满⾜最左前缀,就可以利⽤索引来加速检索。这个最左前缀可以是联合索引的最左N 个字段,也可以是字符串索引的最左M个字符。
联合索引的好处
- 减少开销:建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。对于大量数据的表,使用联合索引会大大的减少开销
- 覆盖索引:可以通过联合索引直接遍历取的数据,而无需回表查询,减少IO次数。
- 效率高:通过联合索引限定多个字段的方式可以筛选出更少的数据,提升效率















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









