







第一次种树:先向大佬学习:https://blog.csdn.net/yangliuy/article/details/7322015
话不多说,开始干!
决策树作为最常用的机器学习方法,也是最容易理解的算法,顾名思义,就是对当前样本做出决策。
举个栗子:
晴天,空气湿度正常–>可以外出活动
但是决策树不是这么简单的照本宣科,它的一大功能:对未知属性集合做出决策
这其实也暗示着:得到一颗决策树不需要通过训练所有属性集合

开始构建决策树:
一颗决策树有且仅有一个根节点(outlook),以及至少一个叶节点(NO/Yes)
构建决策树的过程==挑选最优节点的过程
- 选择最优节点的依据:我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的"纯度"(purity)尽可能的高。而信息熵(information entropy)是度量样本集合纯度最常用的一种指标,假定当前样本集合S第i类样本所占比例为Pi,则D的信息熵定义为
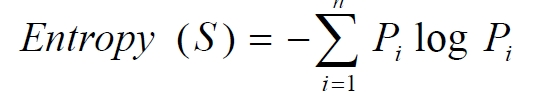
若Ent(S)的值越小,则D的纯度越高 - 假定离散属性A有V个可能取值{A1,A2,A3,…AV},若使用α来对也样本S进行划分,则会产生V个分支结点,其中第V个分支结点包含了S所有在属性A上取值为AV的样本,记为SV。再根据样本所占比重赋予权重: |SV| / |S|, 可得"信息增益"(information gain)

一般而言,信息增益越大,说明使用属性A划分所获得的“纯度提升”越大。这篇博客就是以信息增益为准则进行划分属性的 ID3决策树
注意:由于这个决策树只是为了在项目要求的环境下运行,所以有些数据格式的转化是必需的。还有博主为了方便(毕竟ID3本身容易过拟合,不去测试也知道结果怎么样),没有去分割测试集,直接拿训练集来测试,所以测试集要自己分割,建议采用bagging法
数据集已经上传,请自行下载
下面是完整的决策树代码:
#include <iostream>
#include <string>
#include <vector>
#include <map>
#include <algorithm>
#include <cmath>
#include <fstream>
#include<sstream>
using namespace std;
const int row = 12960;
const int feather = 9;
int mmData[row][feather];//截取数据12960个
int toNum(string str)//Enclave无法接受string类型数据,转化成整数
{
int ans = 0;
for (unsigned int i = 0; i < str.length(); i++)
{
ans = ans * 10 + (str[i] - '0');
}
return ans;
}
void loaddata(string path)//读取文本数据,并存储在二维数组
{
ifstream Filein;
try { Filein.open(path); }
catch (exception e)
{
cout << "File open failed!";
}
string line;
int data_num = 0;
while (getline(Filein, line)) {
int before = 0;
int cnt = 0;
data_num++;
for (unsigned int i = 0; i < line.length(); i++) {
if (line[i] == ',' || line[i] == '\n') {
string sub = line.substr(before, i - before);
before = i + 1;
mmData[data_num - 1][cnt] = toNum(sub);
cnt++;
}
}
mmData[data_num - 1][cnt] = toNum(line.substr(before, line.length()));
}
cout << "data loading done.\nthe amount of data is: " << data_num << endl;
}
int tree_size = 0;
vector<vector<int>>Data;//保存实例集
vector<string>attribute_row;//保存属性集
vector<int>item(feather);//保存一整行数据
int not_recom(91);
int recommend(92);
int very_recom(93);
int priority(94);
int spec_prior(95);
int blank(0);
map<string, vector < int > > map_attribute_values;//存储属性对应的所有的值
struct Node {//决策树节点
int attribute;//属性值
string bestAttribute;
int arrived_value;//到达的属性值
bool LeafNode;
vector<Node *> childs;//所有的孩子
Node() {
attribute = 0;
arrived_value = blank;
bestAttribute = "";
LeafNode = false;
}
};
Node * root;
void setAttribute()
{
string att[9] = { "parents","has_nurs","form","children","housing","finance","socila","health","Distribution" };
for (int i = 0; i < feather; i++)
attribute_row.push_back(att[i]);
}
void GetSgxData(int maindata[12960][9])
{
vector<int>temp;
for (int i = 0; i < row; i++)
{
for (int j = 0; j < feather; j++)
{
temp.push_back(maindata[i][j]);
}
Data.push_back(temp);
temp.clear();
}
}
//建立属性map(字典)
void ComputeMapFrom2DVector() {
unsigned int i, j, k;
bool exited = false;
vector<int> values;
for (i = 0; i < feather - 1; i++) {//按照列遍历
for (j = 0; j < Data.size(); j++) {
for (k = 0; k < values.size(); k++) {
if (values[k] == Data[j][i]) exited = true;
}
if (!exited) {
values.push_back(Data[j][i]);//注意Vector的插入都是从前面插入的,注意更新it,始终指向vector头
}
exited = false;
}
map_attribute_values[attribute_row[i]] = values;
cout << values[0] << endl;
values.erase(values.begin(), values.end());
}
}
//计算信息熵,values(91,92...)
double ComputeEntropy(vector <vector <int> > remain_data, string attribute, int value, bool ifparent) {
vector<int> count(5, 0);
unsigned int i, j;
bool done_flag = false;//哨兵值
for (j = 0; j < feather; j++) {
if (done_flag) break;
if (!attribute_row[j].compare(attribute)) {
for (i = 0; i < remain_data.size(); i++) {
if ((!ifparent && (remain_data[i][j] == value)) || ifparent) {//ifparent记录是否算父节点
for (int k = 91; k < 96; k++) {//计数,看不同结果的各占多少
if (remain_data[i][feather - 1] == k) {
count[k - 91]++;
break;
}
}
}
}
done_flag = true;
}
}
if (count[0] == 0 || count[1] == 0 || count[2] == 0 || count[3] == 0 || count[4] == 0) return 0;//全部是正实例或者负实例
//具体计算熵 根据[+count[0],-count[1]],log2为底通过换底公式换成自然数底数
double sum = count[0] + count[1] + count[2] + count[3] + count[4];
double entropy = 0;
for (int i = 0; i < 5; i++) {
entropy += -count[i] / sum * log(count[i] / sum) / log(2.0);
}
return entropy;
}
double ComputeGain(vector <vector <int> > remain_data, string attribute) {
unsigned int j, k, m;
//首先求不做划分时的熵
double parent_entropy = ComputeEntropy(remain_data, attribute, 0, true);
double children_entropy = 0;
//然后求做划分后各个值的熵,values存放了某个属性的所有可能取值
vector<int> values = map_attribute_values[attribute];
vector<double> ratio;
vector<int> count_values;
int tempint;
for (m = 0; m < values.size(); m++) {
tempint = 0;
for (k = 0; k < feather - 1; k++) {
if (!attribute_row[k].compare(attribute)) {
for (j = 0; j < remain_data.size(); j++) {
if (remain_data[j][k] == values[m]) {
tempint++;
}
}
}
}
count_values.push_back(tempint);
}
for (j = 0; j < values.size(); j++) {
ratio.push_back((double)count_values[j] / (double)(remain_data.size()));
}
double temp_entropy;
for (j = 0; j < values.size(); j++) {
temp_entropy = ComputeEntropy(remain_data, attribute, values[j], false);
children_entropy += ratio[j] * temp_entropy;
}
return (parent_entropy - children_entropy);
}
int FindAttriNumByName(string attri) {
for (int i = 0; i < feather; i++) {
if (!attribute_row[i].compare(attri)) return i;
}
/*cout << "can't find the numth of attribute" << endl;*/
return 0;
}
//找出样例中占多数的结果(91,92,93...)
int MostCommonLabel(vector <vector <int> > remain_state) {
int p[5] = { 0 };
for (unsigned i = 0; i < remain_state.size(); i++) {
for (int j = 0; j < 5; j++) {
if (remain_state[i][feather - 1] == 91 + j) {
p[j]++;
break;
}
}
}
int temp = 0;
for (int i = 0; i < 5; i++) {
if (temp < p[i])
temp = p[i];
}
return temp;
}
//判断样例是否(正负)性都为label
bool AllTheSameLabel(vector <vector <int> > remain_state, int label) {
int count = 0;
for (unsigned int i = 0; i < remain_state.size(); i++) {
if (remain_state[i][feather - 1] == label) count++;
}
if (count == remain_state.size()) return true;
else return false;
}
//计算信息增益,DFS构建决策树
//current_node为当前的节点
//remain_state为剩余待分类的样例
//remian_attribute为剩余还没有考虑的属性
//返回根结点指针
Node * BulidDecisionTreeDFS(Node * p, vector <vector <int> > remain_state, vector <string> remain_attribute) {
if (p == NULL)
p = new Node();
//先看搜索到树叶的情况
for (int i = 91; i < 96; i++) {
if (AllTheSameLabel(remain_state, i)){
p->attribute = i;
p->LeafNode = true;
return p;
}
}
if (remain_attribute.size() == 0) {//所有的属性均已经考虑完了,还没有分尽
int label = MostCommonLabel(remain_state);
p->attribute = label;
return p;
}
double max_gain = 0, temp_gain;
vector <string>::iterator max_it = remain_attribute.begin();
vector <string>::iterator it1;
for (it1 = remain_attribute.begin(); it1 != remain_attribute.end(); it1++) {
temp_gain = ComputeGain(remain_state, (*it1));
if (temp_gain > max_gain) {
max_gain = temp_gain;
max_it = it1;
}
}
//下面根据max_it指向的属性来划分当前样例,更新样例集和属性集
vector <string> new_attribute;
vector <vector <int> > new_state;
for (vector <string>::iterator it2 = remain_attribute.begin(); it2 != remain_attribute.end(); it2++) {
if ((*it2).compare(*max_it))
new_attribute.push_back(*it2);
}
//确定了最佳划分属性,注意保存
p->bestAttribute = *max_it;
vector <int> values = map_attribute_values[*max_it];
int attribue_num = FindAttriNumByName(*max_it);
/*new_state.push_back(attribute_row);*/
for (vector <int>::iterator it3 = values.begin(); it3 != values.end(); it3++) {
for (unsigned int i = 0; i < remain_state.size(); i++) {
if (remain_state[i][attribue_num] == *it3) {
new_state.push_back(remain_state[i]);
}
}
Node * new_node = new Node();
new_node->arrived_value = *it3;
if (new_state.size() == 0) {//表示当前没有这个分支的样例,当前的new_node为叶子节点
new_node->attribute = MostCommonLabel(remain_state);
}
else
BulidDecisionTreeDFS(new_node, new_state, new_attribute);
//递归函数返回时即回溯时需要1 将新结点加入父节点孩子容器 2清除new_state容器
p->childs.push_back(new_node);
new_state.erase(new_state.begin(), new_state.end());//注意先清空new_state中的前一个取值的样例,准备遍历下一个取值样例
}
return p;
}
void PrintTree(Node *p, int depth) {
for (int i = 0; i < depth; i++) printf("\t");//按照树的深度先输出tab
if (!(p->arrived_value == 0)) {
printf("%d\n", p->arrived_value);//某一属性所代表的值
for (int i = 0; i < depth + 1; i++) printf("\t");//按照树的深度先输出tab
}
cout << p->bestAttribute <<'\t';
printf("%d\n", p->attribute);//标签
for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++) {
PrintTree(*it, depth + 1);
}
}
void FreeTree(Node *p) {
if (p == NULL)
return;
for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++) {
FreeTree(*it);
}
delete p;
tree_size++;
}
int getIndex(int num)
{
num = (num / 10) - 1;
if (num==-1)
return 3;
else return num;
}
int num = 0;
int predictTree(Node *p,vector<int>test,int depth)
{
if (p->LeafNode&&depth != 0)
{
//cout << "p->attribute:" << p->attribute << endl;
num = p->attribute;
return num;
}
else {
Node *temp;
for (vector<Node*>::iterator it = p->childs.begin(); it != p->childs.end(); it++) {
temp = *it;
//cout <<"p->arrive_val:" <<temp->arrived_value << endl;
int indexAtt = getIndex(temp->arrived_value);
if (test[indexAtt] != temp->arrived_value)
continue;
predictTree(*it, test,depth+1);
}
return 0;
}
}
vector<int>retest;
void BuildSgxTree()
{
setAttribute();
vector <string> remain_attribute;
string att[8] = { "parents","has_nurs","form","children","housing","finance","socila","health"};
for (int i = 0; i < feather - 1; i++)
remain_attribute.push_back(att[i]);
vector <vector <int> > remain_state;
for (unsigned int i = 0; i < Data.size(); i++) {
remain_state.push_back(Data[i]);
}
ComputeMapFrom2DVector();
root = BulidDecisionTreeDFS(root, remain_state, remain_attribute);
//PrintTree(root, 0);
vector<int>test;
for (int x = 0; x < 12960; x++)
{
for (int i = 0; i < 8; i++)
{
if (x == 1)
Data[1][0] = 14;
test.push_back(Data[x][i]);
}
int result = 0;
result = predictTree(root, test, 0);
result = num;
//cout << "result:" << result << endl;
test.clear();
if (result == 0)
{
result = rand() % 5 + 91;
cout << "reslut:" << result << endl;
}
retest.push_back(result);
}
FreeTree(root);
}
int main()
{
loaddata("boring.txt");//获取数据集,并存于Data数组
int x = 2;
int t = 32;
GetSgxData(mmData);
BuildSgxTree();
cout << "tree_size:" << tree_size << endl;
map<string, vector<int>>::iterator it;
for (it = map_attribute_values.begin(); it != map_attribute_values.end(); it++)
{
cout << it->first << ":";
for (unsigned int i = 0; i < it->second.size(); i++)
cout << it->second[i] << '\t';
cout << endl;
}
double bingo = 0;
for (int i = 0; i < 12960; i++)
{
if (retest[i] == Data[i][8])
bingo++;
}
cout << "accrucy:" << bingo / 12960.00 << endl;
system("pause");
return 0;
}
这个是决策树的效果图,用代码生成的那个不好看,这个是用其他软件生成的
















 7276
7276











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









