







我的数据结构和算法专栏和其他专栏一样,严格按照《照顾萌新》的原则。先从最基本的理解开始
查询的演进
查询或者说搜索是生活中随处可见的场景。
说一个最简单的场景:
8 1 2 3 5 2 5 6 7 2 1
在这串数字中 计算机要找出7
它不可能像人一样 一眼就认出 7在哪里。
而且 这串数字 看着也没什么 规律
所以它最笨的方法
就是从第一个遍历。一个一个找 一个一个认。
这种效率无疑是低下的。
于是有人想出先把数字排序
1 1 2 2 2 3 5 5 6 7 8
然后我二分查找, 既然它是有序的 先找出中间的 3, 7比3小 那么找右边。
右边的中间是6 再找右边。 一直找到 7
一下子就排除了一半选项
性能是高了不少。
可是问题来了 这样搞 查询是爽了
可是这么多数字 你先要把它排序
这个排序的过程 岂不是累死人????
于是就有了
二叉搜索树
在弄明白它的原理之前——你先要记住一点 就是二叉搜索里面的元素 已经是牌好序的
重点在这个’已经‘
也就是说 你每往里面丢一个东西进去 它就帮你排好序了,不用你再自己另外排一遍 这就解决了 上面那个累死人的问题。
我们知道标准的树结构:
class TreeNode {
int value;
TreeNode left;
TreeNode right;
TreeNode parent;
public TreeNode(int value) {
this.value = value;
this.left = null;
this.right = null;
this.parent = null;
}
}
正常情况下 除了value 节点本身的值 二叉搜索树会有另外一个key 单独来排序。
但是这里因为排的是数字 我们直接就用value当key。
这里就要有定义了:
- 作为一个二叉搜索树 key 不能重复!
- 任何一个key节点 它的key都要比左边大 比右边小(其实就是在实践排序的流程思想)
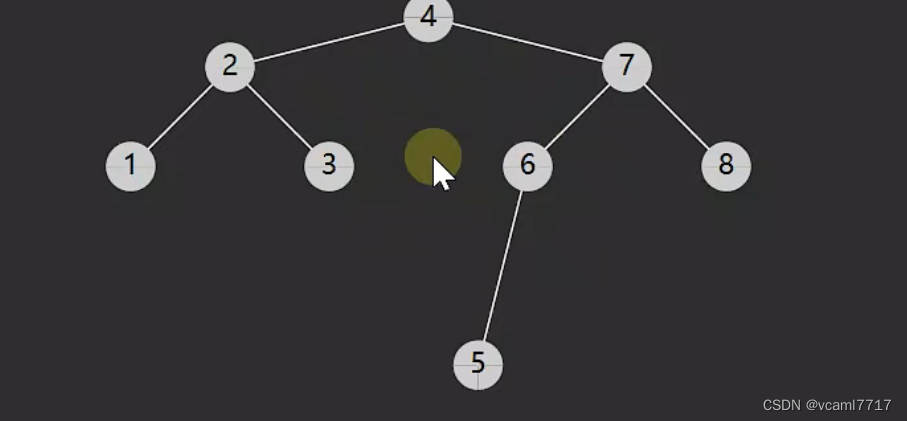
看这个树 假设现在 只有一个根节点4.
这时候来个 2 放左边
来个1 放4的左边 再放2的左边
来个 7 放4的右边
来个6 放4的右边 再放7的左边
依次类推。
这是插入 查询同理
特殊情况
你是否体会到了? 二叉搜索树 建立的适合 你要把一堆东西扔进去查询
先扔哪一个 是有很大影响的
因为你先扔进去一个中间的数字 为根节点 这个树 就显得比较平衡
但是如果 1 2 3 4 5 你先把5扔进去
那就会变成这样:
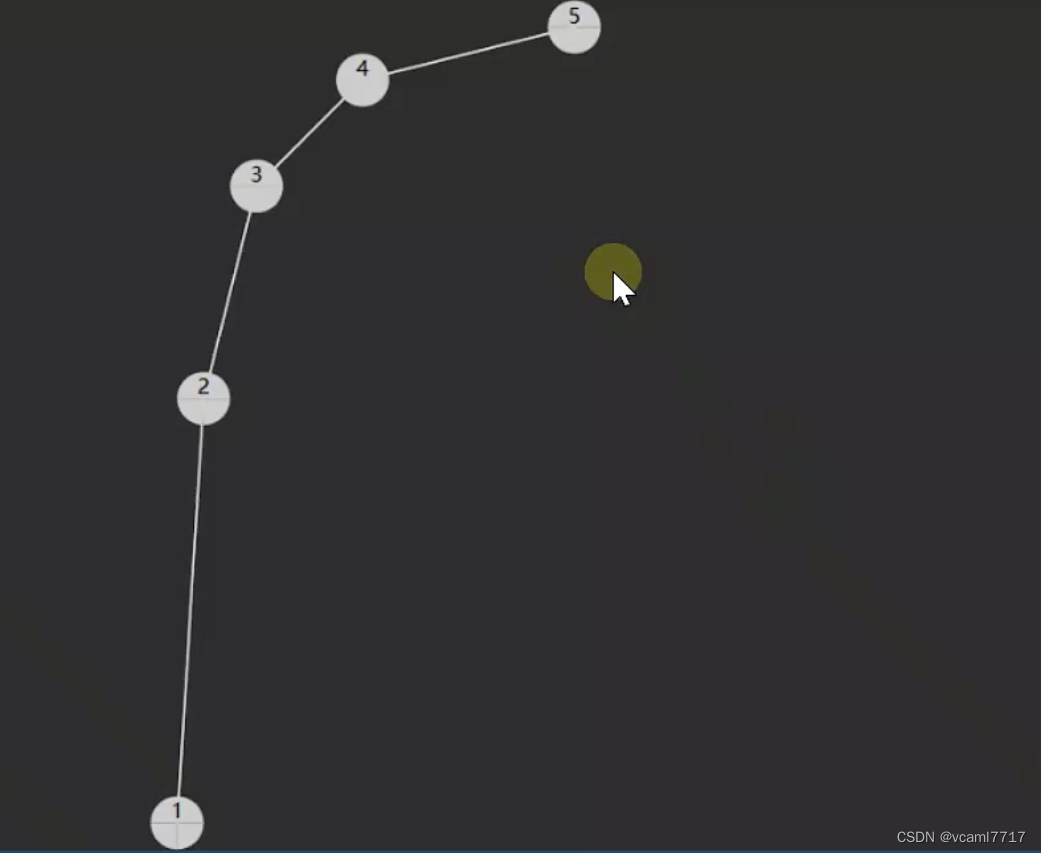
说是树 它已经变成了一个链表。
所以这种情况下它的查询效率 又回到了 最初的一个一个傻傻的找。
分析删除的情况
树本身是由链表组成的 作为一个链表 你可以任意删除某一个节点
但是在我们的二叉搜索树中,某个节点被删了 那这里就断了 你需要把它的子节点和父节点重新连来。 但是连的时候 要保持这个原则不变:
- 任何一个key节点 它的key都要比左边大 比右边小
所以这里的删就不能随便删了,我们来分析一下;
- 首先 如果 这个节点是叶节点 它没有左右子节点 那就直接删了 最简单。
- 然后如果它只有左/或者只有右节点 这个也很简单。
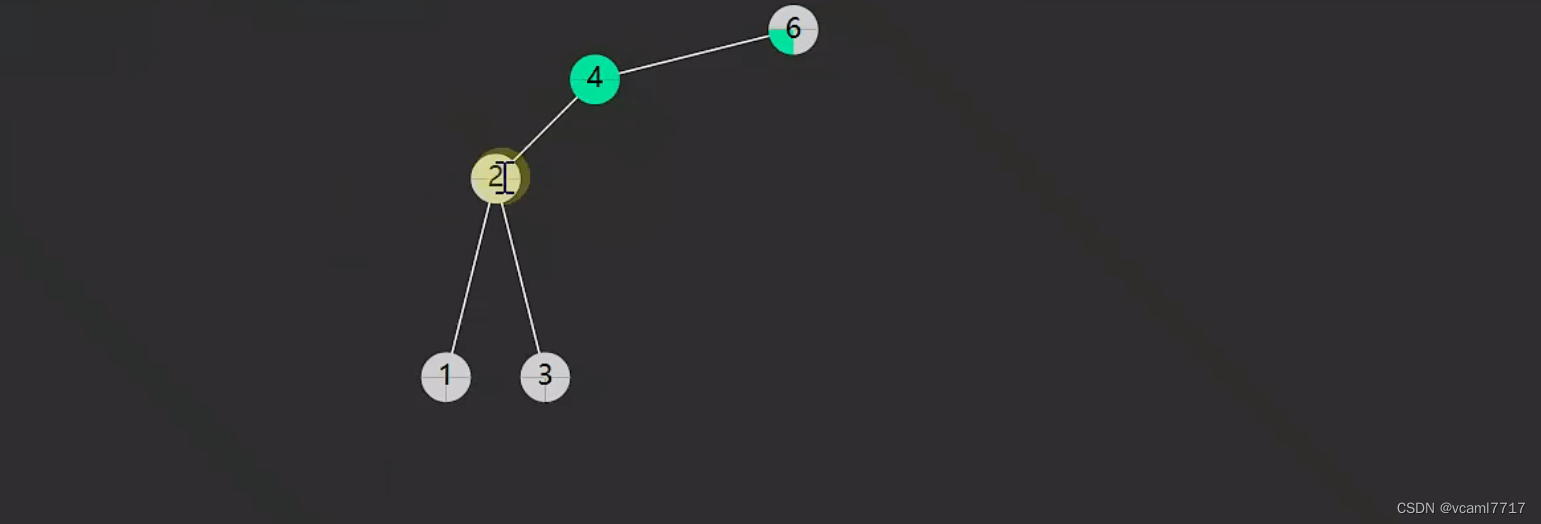
比如我们要删除 4,
它只有2 一个节点
只需要把2 托付给 6.
就ok;了。
- 然后 比较关键的是 如果它是儿女双全的节点 比如 :删除20
30
/
20
/ \
1 25
/ \
22 28
这时候
我们需要去寻找 被删除节点的
后继节点(右子树中的最小节点)或前驱节点(左子树中的最大节点
这两个都可以, 比如我们找后继节点
20 的右子树 里面最小的是哪个?22
我们把22替换到20的位置 然后把22删掉
30
/
22
/ \
1 25
\
28
就可以了
你发现了一个规律没有? 后继节点(右子树中的最小节点)或前驱节点(左子树中的最大节点肯定是叶节点
所以你不用担心替换之后 删掉原节点会有什么问题
这就是二叉查找树的基本理解















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









