







Background: optimizer the bert model updating in 2021/10/18
首先,改进基于文本分类任务或多文本分类任务的bert模型的方法主要有三种:
(from 《How to Fine-Tune BERT for Text Classification?》)
我们可以整理文章的上下文,对于通常的微调策略,一个问题是如何处理非常长的文本?
ELT(超长文本)意味着bert可以处理的最大长度为512,因此,根据论文,文本的头部和尾部效果最好。可能里面有很多信息?接下来,有两个重要的问题,一个是如何选择分类任务的最佳层次;另一个是如何选择最佳学习率调整策略?论文中的实验表明对于最好的一层来说是最好的,即层指数为11,对于另一个问题,使用较低的学习率和热身策略可能会
更好。但是一些小例子中的解决方案并不像增加epoch那样有效。
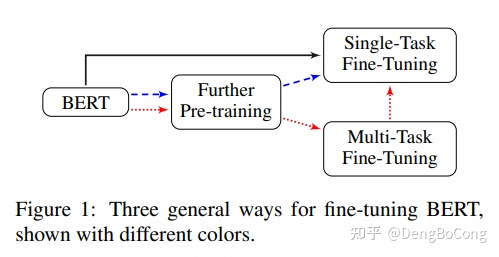
下一个主题是关于进一步的预训练,这是我最喜欢的部分。不管怎么说,这个想法从诞生之日起就受到了重视,
即使是ACL2020中最好的论文也被命名为《不要停止预训练:使语言模型适应领域和任务》,这篇论文的主题是:
“再次预训练”,然而,通常的方法是称为“DAPT”和“TAPT”,有“域自适应预训练”的方法和“任务适应性预训练”。因此,DAPT说,基于第一阶段模型,通常是在巨大语料库上训练的gernal模型,
然后,使用域未标记的示例继续预训练。
另外,关于模型优化有两种不同的方法:图形神经网络和辅助任务。
fine-tuning the model
微调是一项古老的技术,在bert出生之前。但它今天确实很管用。
例如,阿里巴巴举办的多任务学习竞赛,其主要目标是培养泛化能力
训练前语言模式的研究,它可以给我们很好的启示。
无论如何,图表中的这些方法可以帮助我们:

better pretrain_model
我们的基线模型使用“chinese_roberta_wwm_ext_L-12_H-768_A-12”,该模型来自哈尔滨工业大学,
我们变成了另一个名为“RoBERTa-large-pair”。它着重于句子对的模式。
different model structs
整合模式暂不考虑,bone net无法改变,
因此,剩下的选项是这些结构的堆栈:
例如,在pooling技巧中,一些比赛在进行pooling后使用4层接近伯特的输出,
取得了一些成果,给我带来了启示。
loss strategy
多标签分类任务有几个需要考虑的难题:
1.标签数量不确定。
2.标签之间存在依赖关系。
3.输出空间巨大。
为了解决这些问题,有许多方法被提出,如使用rnn或图形神经网络,在成瘾中,
损失函数的设计工作也受到了一定程度的重视。
Such as use focal loss(权重损失函数) and
softmax usage,for example this paper, it want to solve problems I just say,
using by concurrent-softmax and negative sampling.Someone has transferred it into
multi label text classify task,considering the description of this loss function in the paper,
I think this one maybe a good solution.
import torch.nn as nn
import torch
# 普通的softmax用于多标签分类
def criterion2(y_pred,y_true):
y_pred = (1 - 2*y_true)*y_pred
y_pred_neg = y_pred - y_true * 1e12
y_pred_pos = y_pred - (1 - y_true) * 1e12
zeros = torch.zeros_like(y_pred[...,:1])
y_pred_neg = torch.cat((y_pred_neg,zeros),dim=-1)
y_pred_pos = torch.cat((y_pred_pos,zeros),dim=-1)
neg_loss = torch.logsumexp(y_pred_neg,dim=-1)
pos_loss = torch.logsumexp(y_pred_pos,dim=-1)
return torch.mean(neg_loss + pos_loss)
import torch.nn as nn
import torch
def criterion(y_pred, y_true, weight=None, alpha=0.25, gamma=2):
sigmoid_p = nn.Sigmoid(y_pred)
zeros = torch.zeros_like(sigmoid_p)
pos_p_sub = torch.where(y_true > zeros,y_true - sigmoid_p,zeros)
neg_p_sub = torch.where(y_true > zeros,zeros,sigmoid_p)
per_entry_cross_ent = -alpha * (pos_p_sub ** gamma) * torch.log(torch.clamp(sigmoid_p,1e-8,1.0))-(1-alpha)*(neg_p_sub ** gamma)*torch.log(torch.clamp(1.0-sigmoid_p,1e-8,1.0))
return per_entry_cross_ent.sum()
better optimizer algorithm
learning rate
通常,为了防止灾难性遗忘,伯特模型的学习率应该更低,为了处理过拟合问题,
我们可以为每个层设置不同的学习速率。

此外,微调结构的学习率不应与其自身相同,通常要高于bert。
因为我们都知道,bert是预训练的,而我们的结构不是,预训练意味着更容易得到最佳值,
使用较小的lr是可以理解的,但是如果我们使用struts,从零开始训练,这不仅会使训练进展缓慢,
但也让微调结构与bert不同步。
batch size
not too big,not too small.
confrontation training
I have no idea about this
Regularization
dropout
label-smooth
data selection strategy
那么,对于数据选择,哪种组合是最好的,“上诉标题”加上“上诉地址”或“上诉地址”加上“上诉背景”?
我做了三个实验来选择这个。
| index | model struct | main task | Auxiliary task | best result | Hyper params [textcnn;filters;units;maxlen;batch_size;pre_train] | other information |
|---|---|---|---|---|---|---|
| bert_texcnn_Realmutil_mlps_v2(619) | Bert + textcnn + mlps | multi label classify | \ | acc=0.12 when epoch = 11 | [3,4,5];256;[256];64;256;True | monitor is val_loss |
| bert_texcnn_Realmutil_mlps_v2(612) | Bert + textcnn + mlps | multi label classify | \ | acc=0.10 when epoch = 25 | [3,4,5];128;[512,256];64;128;True | monitor is val_acc and patient to 15 epoch |
| bert_texcnn_Realmutil_mlps_v3 | Bert + textcnn + mlps | multi label classify | \ | acc=0.2988 when epoch = 1 | [3,4,5];128;[256];64;128;True | monitor is val_acc and patient to 5 epoch using by “诉求内容” and “地址” |
通过对这些实验的分析,我们发现语境和地址的结合可能比其他的结合更好。我认为信息的多样性很重要,但是,尽管使用上下文加地址可以获得
精度更高,但它会接管拟合问题,因此,我们应该通过有限的数据处理来修复它,例如在上诉上下文中删除重复模板。但是,不要做太多的数据任务,因为这不是关键点和成本。
总之,在最后,我们选择了上诉上下文和上诉地址的组合,但数据有限。
经过分析发现,几乎所有的上诉语境都有地址信息,而最有用的信息都有地址信息
在head and tail by observed.中,最后一种策略是使用将上诉上下文拆分为head and tail集合为text1和text2。
final strategy
默认策略是
- data: text1 = Appeal address, text2 =Appeal context(full) label number=215
- model struct: bert + mlp(256units)
- loss function: binary category
- hyper param: batch=64, max-len=128, learning rate:5e-4,epoch=5
- optimizer: adam
- pretrain model: chinese_roberta_wwm_ext_L-12_H-768_A-12
- early-stop:monitor is val_loss no patient
TEST STANDARD:训练5个Epoch,统计val acc和val acc的方差
| index | model_name | pretrain_model | model structs | loss strategy | hyper param | dropout | label-smooth | output layer | confrontation training | data selection | val-acc | V(val-acc) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | base line | chinese_roberta_wwm_ext_L-12_H-768_A-12 | bert + mlp(256units) | binary category | batch=64, max-len=128, learning rate:5e-4 | False | False | 11 | False | text1 = Appeal address, text2 =Appeal context(full) label number=215 | |||
| selections | / | / | chinese_roberta_wwm_ext_L-12_H-768_A-1 RoBERTa-large-pair | bert + mlp(256units) bert + mlp(512.256) + avg-pooling bert + mlp(512.256) + textcnn(3,4,5) | binary category concurrent softmax + cross category | batch=64, max-len=128, learning rate:5e-5 batch=64, max-len=128, learning rate:[5e-5,2e-4] batch=64, max-len=128, learning rate:warm-up batch=64, max-len=128, learning rate:warm-up,2e-4 | True Fasle Double | False True | 10 -4 layer pooling 1 | False True | text1 = Appeal address, text2 =Appeal context(full) label number=215 text1 = head from cleaned appeal context, text2 =tail from cleaned appeal context label number=215 | ||
| 1 | chinese_roberta_wwm_ext_L-12_H-768_A-12 | ||||||||||||
| 2 | RoBERTa-large-pair | ||||||||||||
| 3 | bert + mlp(512.256) + avg-pooling | ||||||||||||
| 4 | bert + mlp(512.256) + textcnn(3,4,5) | ||||||||||||
| 5 | concurrent softmax + cross category | ||||||||||||
| 6 | batch=64, max-len=128, learning rate:5e-5 | ||||||||||||
| 7 | batch=64, max-len=128, learning rate:[5e-5,2e-4] | ||||||||||||
| 8 | batch=64, max-len=128, learning rate:warm-up | ||||||||||||
| 9 | batch=64, max-len=128, learning rate:warm-up,2e-4 | ||||||||||||
| 10 | True | ||||||||||||
| 11 | 10 | ||||||||||||
| 12 | -4 layer pooling | ||||||||||||
| 13 | 1 | ||||||||||||
| 14 | True | ||||||||||||
| 15 | text1 = head from cleaned appeal context, text2 =tail from cleaned appeal context | label number=215 |
因此,在每个部分中选择最佳方法来构建最终模型,然后进行一点微调。
Generalization of bert model
让我们来谈谈一般化。通常,微调模型有两种不同的方法,一种是微调结构的训练,另一种是bert本身,
另一个是用冻结bert训练微调结构,我设置了4个不同的实验来测试模型的泛化性。
| index | bert freezing | best result | data Homology | other information |
|---|---|---|---|---|
| bert_texcnn_Realmutil_mlps_Gtest_v1.h5 | True | True | ||
| bert_texcnn_Realmutil_mlps_Gtest_v2.h5 | True | False | ||
| bert_texcnn_Realmutil_mlps_Gtest_v3.h5 | False | True | ||
| bert_texcnn_Realmutil_mlps_Gtest_v4.h5 | False | False |















 2196
2196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









