







正则表达式
简单来说,正则表达式就是描述字符串的一套规则。比如,我们想找出一个网页中的所有URL链接,其他的信息需要过滤掉。那么此时,我们可以观察链接的格式,然后写一个正则表达式来表示所有的电子邮件。随后,我们可以利用该表达式从网页中提取出所有满足该规则的URL链接。正则表达式的功能非常强大,在爬虫的实际项目中,对于处理特定格式的信息,经常需要用到正则表达式。
在Python中,可以使用re模块来实现Python正则表达式。
一、正则表达式基础知识
正则表达式学习其实非常简单,就是有较多的需要记的字符、字符功能。为了能够有一个系统的i思维去把握正则,我将会从原子、元字符、模式修正符与懒惰模式等方面介绍。
-
原子
原子——正则表达式中最基本的单位(普通字符、非打印字符、通用字符、原子表)普通字符
数字、大小写字母、下划线等都可作为原子使用。非打印字符
符号 含义 \n 用于匹配一个换行符 \t 用于匹配一个制表符 通用字符
符号 含义 \w 匹配任意一个字母、数字或下划线 \W 匹配除字母、数字或下划线以外的任意一个字符 \d 匹配任意一个十进制数 \D 匹配除十进制数以外的任意一个字符 \s 匹配任意一个空白字符 \S 匹配除空白字符以外的任意一个字符 原子表
可以定义一组地位平等的原子,然后匹配的时候会取该原子表中的任意一个原子进行匹配。在Python中,原子表由[]来表示,如[xyz]就是一个原子表,定义了三个原子,三个原子地位平等。(另注:^xyz表示除原子表以外的任意字符)
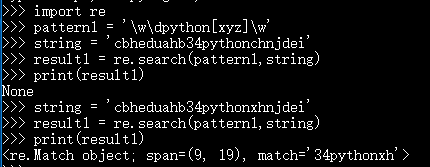
-
元字符
以上是常见原子的使用,一般需要结合元字符才能发挥正则表达式的强大功能。
元字符,在正则表达式中即具有特殊含义的字符。(另注:| 模式选择符)符号 含义 . 匹配除换行符以外的任意字符 ^ 匹配字符串的开始位置 $ 匹配字符串的结束位置 * 匹配0次、1次或多次前面的原子 + 匹配1次或多次前面的原子 {n} 前面的原子恰好出现n次 {n,} 前面的原子至少出现n次 {n,m} 前面的原子至少出现n次,至多出现m次 () 模式单元符 -
模式修正符
所谓模式修正符,即在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实现一些匹配结果的调整功能。
| 符号 | 含义 |
|---|---|
| I | 匹配时忽略大小写(Ignore的首字母) |
| M | 多行匹配(Multiple的首字母) |
| L | 做本地化识别匹配 |
| U | 根据Unicode字符及解析字符 |
| S | 让.匹配包括换行符,可以匹配任意字符 |
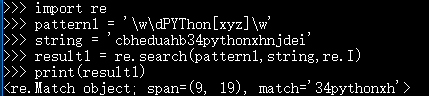
-
贪婪模式与懒惰模式
贪婪模式核心:尽可能的多匹配,懒惰模式核心:匹配成功一次就不再匹配。
贪婪模式在第一次匹配成功后,不会停止,一直到整个待匹配内容的最后。
懒惰模式在第一次匹配成功后就会停止,就近原则。

二、正则表达式常用函数
常见的正则表达式函数有 re,match()、re,search()、全局匹配函数、re,sub()。
re.match()——源字符串的开头进行匹配,要求第一个字符就匹配成功
re.search()——全文进行检索匹配,与match()最大不同是,在全文在进行检索并匹配
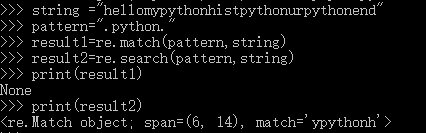
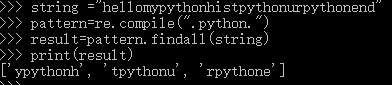
全局匹配函数(re.findall)
需先对正则表达式进行预编译,pattern=re.compile(".python."),返回的是list集合
re.sub()函数
re.sub(pattern,rep,string,max)——rep:要替换成的字符串,max:可选项,最多替换次数
三、正则表达式实例
对于正则表达式的学习,实战是最好的方法。当然也需要不断地积累,做到熟能生巧。
- 匹配.com或.cn后缀的URL网址
实例目的:将一串字符里面的以.com或.cn为域名的URL网址匹配出来。

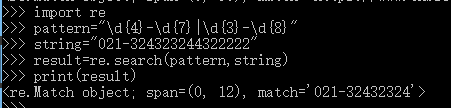
- 匹配电话号码
实例目的:将一串字符里出现的电话号码信息提取出来。
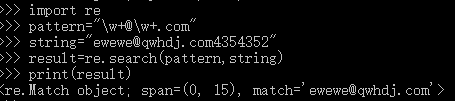
- 匹配电子邮件
实例目的:将一串字符里面出现的电子邮件信息提取出来。
四、结束语
最后,祝大家都能学有所成!!!
















 2097
2097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











