









HttpRunner框架
一、什么是HttpRunner
1.它是面向http协议的测试框架,只需要去维护一份yaml或json文件就可以使用自动化测试。结合locust做性能测试、线上性能监控、持续集成等多种需求。
优点:业务导向,快速落地,提高投入产出比:自动化回归测试、性能脚本复用、持续集成、线上监控、辅助手工测试,自定义生成特定业务数据。

快速学习指南:点我
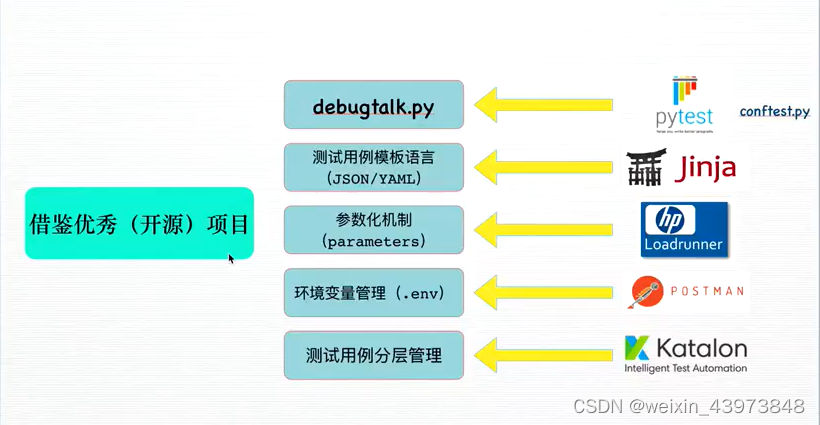
二、设计思想和理念
充分复用优秀的开源项目;约定大于配置(提升测试脚本的可维护性);配置文件组织测试用例;一次投入,多处复用;高度可扩展性
三、安装使用
环境安装
pip install httprunner
pip install har2case
验证安装环境:
hrun -V
har2case -V
五个命令:
-
httprunner :主命令
-
hrun: httprunner的别名,用于运行yaml/json/pytest测试用例
- 运行单个文件:hrun xxx.yml
- 运行多个文件:hrun xx1.yml xx2.yml
- 运行整个项目(用例集):hrun folder_path\xxx.yml
-
hmake :httprunner make 的别名,将yaml/json转换成pytest文件
-
har2case:httprunner har2case别名,用于将har文件转化成yaml/json文件:har2case xxx.har -2y
-
locust:用于性能测试
默认会运行指定用例中的所有用例并统计测试结果。若出现一个失败,其他的都会失败,停止执行。
若想要遇到失败时不再继续执行其他用例,可以添加failfast实现:hrun xxx.yml --failfast
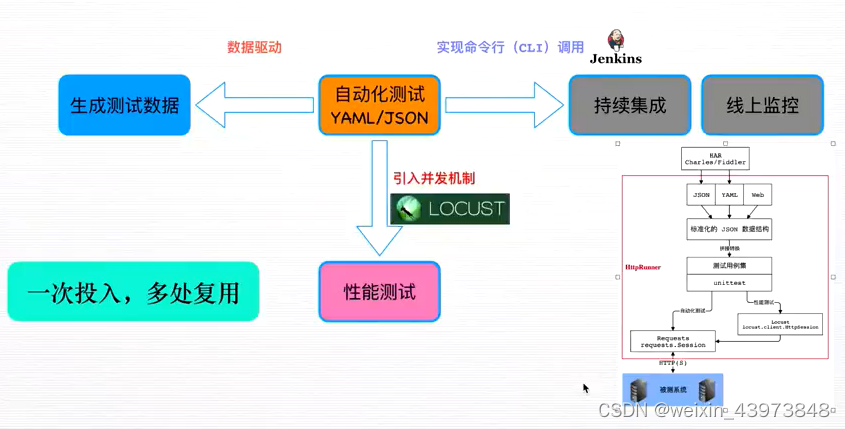
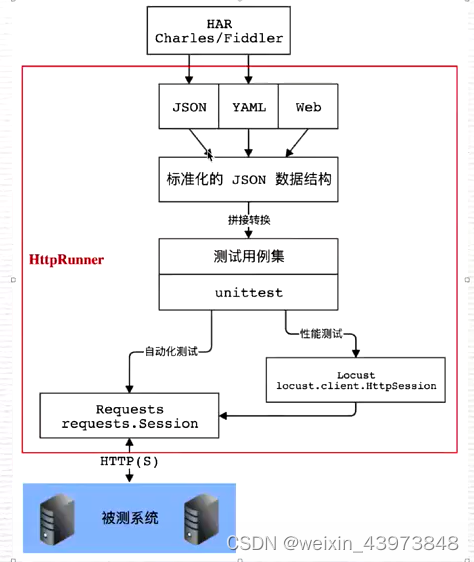
工作流程
脚手架
了解一个简单项目的项目结构。创建一个脚手架:hrun --startproject demo
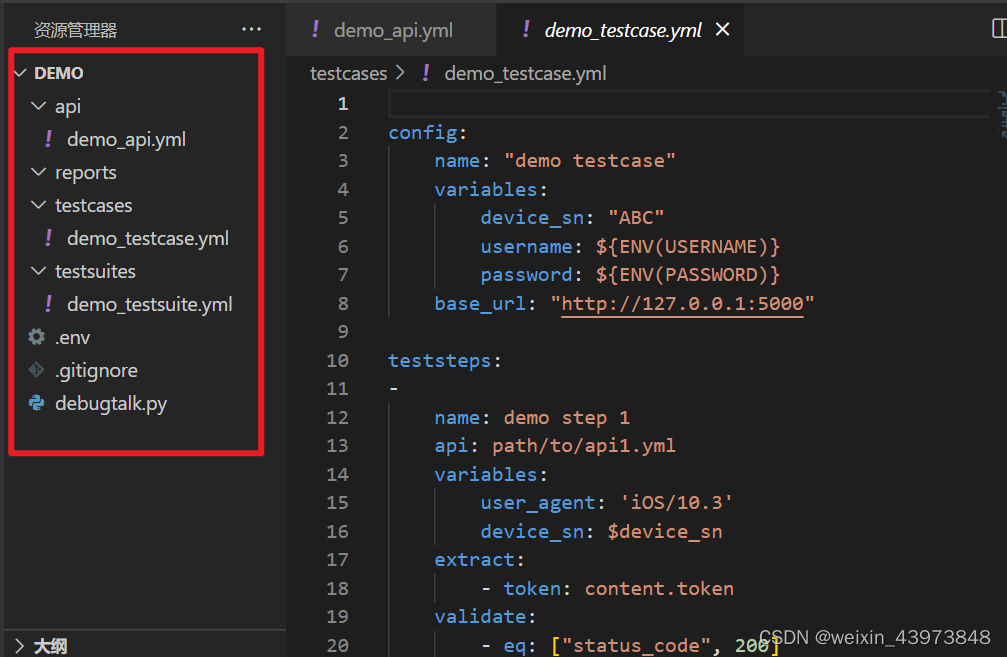
config文件内容结构:


脚本录制生成
1、抓包(以fiddler为例)
- 配置代理
- 配置证书
- 筛选接口内容(比如去除一些图片请求等)
- 保存抓包内容到xxx.har文件(fiddler选择export session—>all session—>选择文件类型为HTTPArchive V1.1保存)
2、生成用例(以tavern为例):tavern会自动将har文件内容生成一个个yaml文件,一个文件就是一个用例,通过httprunner可以自动执行。
- ①pip install har2tavern(pytest\tavern\requests\har2tavern)
- ②har2tavern转换yaml文件:har2case xx.har -2y
-2y表示yaml格式
3、执行文件并生成报告:hrun xxx.yml
由于一般接口之间会存在关联,依赖,因此我们需要进行脚本调试,具体调试内容如下:
脚本调试:
- 调整校验器
- 参数关联
- base_url
- 变量的声明和引用
- 抽取公共变量
- 实现动态运算逻辑
- 使用环境变量存储私有变量
- 测试用例分层机制
- 参数化数据驱动
- 抓包查看脚本运行情况
4、调试完成,运行脚本并查看测试报告
变量的声明、引用
变量的声明:有多种方式,如:在config的variable里声明,或环境变量在.env下声明;
变量引用:$a 或者${a},函数的引用:是${fun()}
自定义校验器
validate:
- len_eq: [content.data,32]
获取环境变量:
1.首先在.env下定义对应变量
2.再去用例的config下调用
config:
name: xxx
variables:
phone: ${ENV(phone)}
password: ${ENV(password)}
接口关联变量的提取
当接口与接口之间存在参数关联,那么上一接口的响应数据,需要先extract出来,给后续的接口使用。
响应是html类型,获取数据,声明变量
extract:
memberId: "memberId:'{.*}'"
响应是json类型,获取数据,声明变量
extract:
memberId: content.memberId
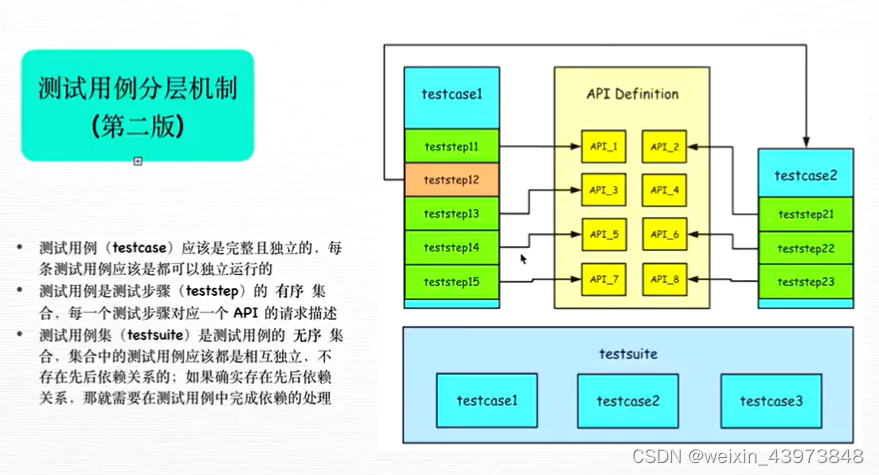
用例分层管理
API层
在api层定义的接口是最先执行的,并且提取出来的变量可以当作全局变量用,在其他位置调用该接口后,直接就可以取到变量值。
api层一个文件就是一个接口,使用独立的文件对接口描述进行存储。
testcases层
1、引用接口定义,每个单接口分离出来放在testcase文件的teststeps中。
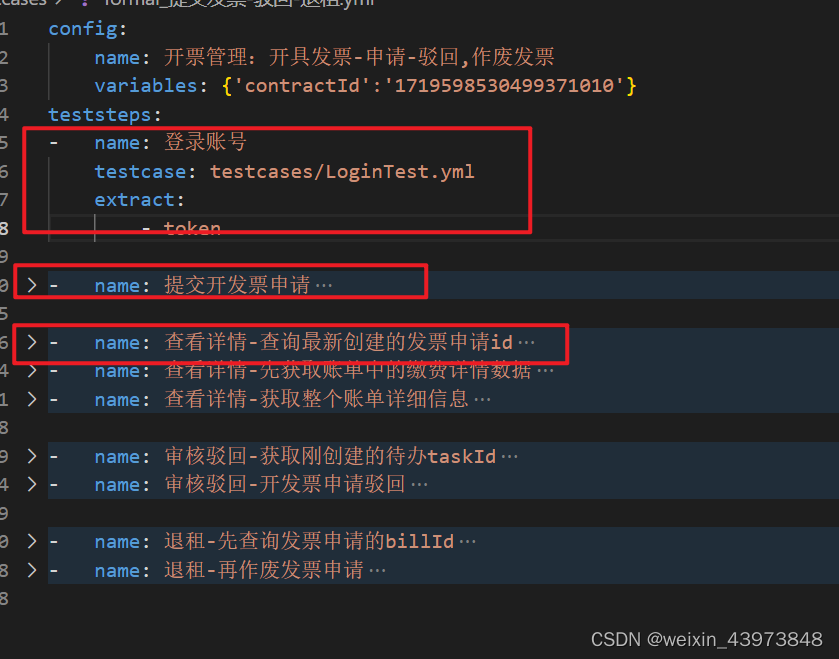
2、在其他的单接口中需要现有登录态或刚创建数据的关联,这时候在新的接口中添加一个先执行的登录接口或创建的接口。
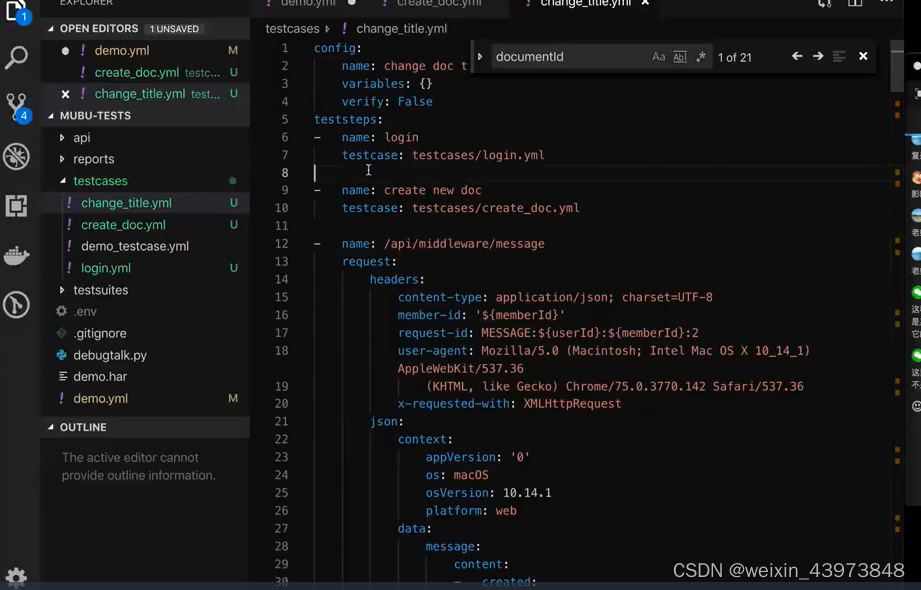
接口之间多数据关联
1、将上一接口的数据提取出来放置在全局变量中,export出来。
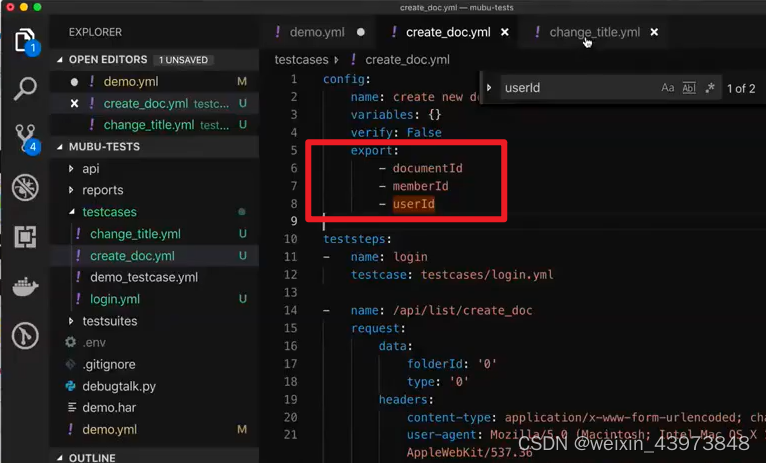
2、下一个接口在执行之前,先提取出上一接口的变量,再进行调用。
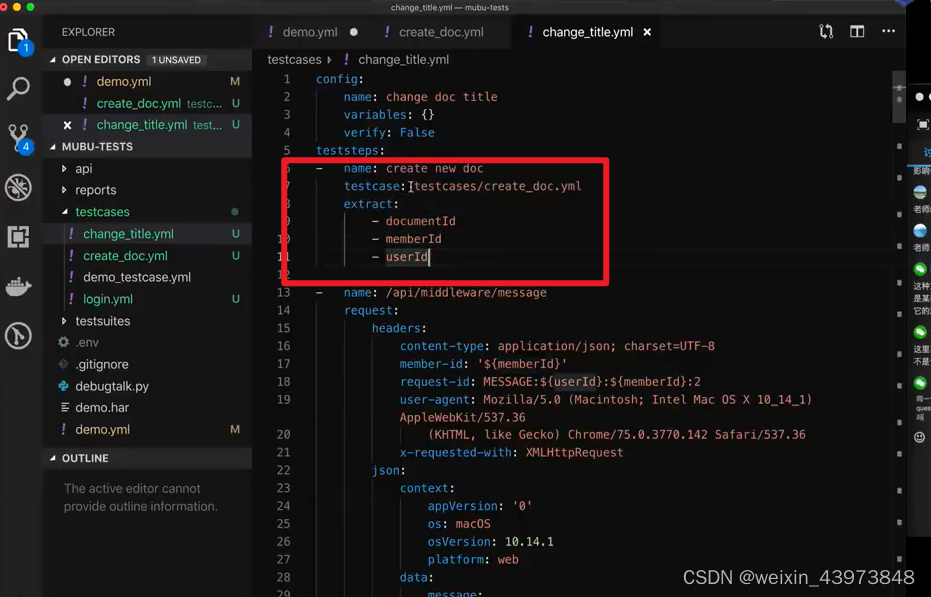
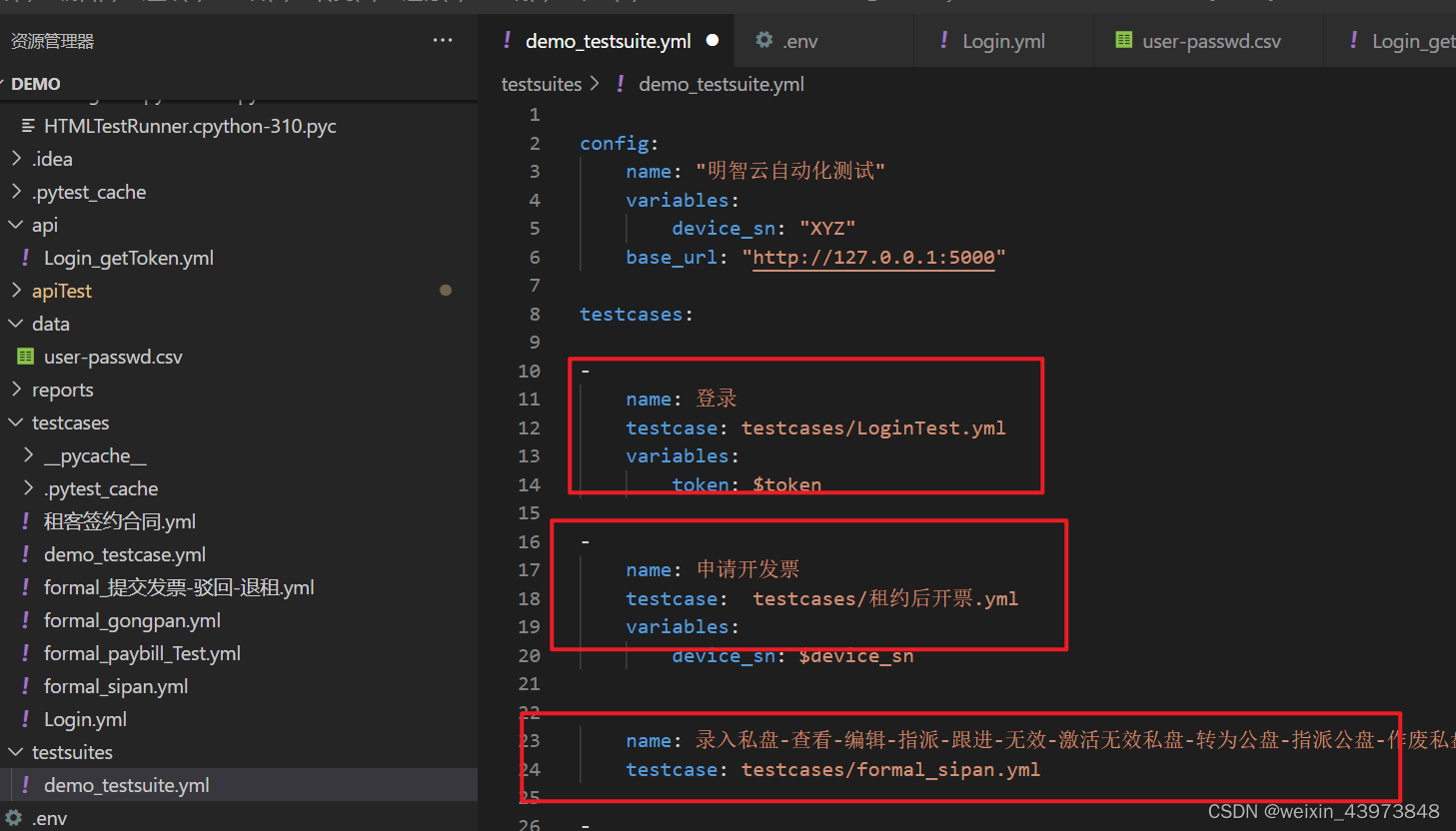
testsuits层
方便多数量用例管理。每个文件中包含多个testcase文件,是一个测试集,可以同时执行多个场景,需要注意:每个场景的执行顺序是无序的,也无法设置固定顺序执行!
数据驱动
读取csv文件中的内容,动态执行不同参数的测试结果。
由于testsuites中包含的是testcase,testcases中包含api,因此做参数化也要遵循这种包含关系来使用。
一共有三种数据驱动参数化的形式:
- 列表参数:在testsuite中的文件中直接定义。
parameters:
user-passwd:
- [ "13603084097", "" ]
- [ "13603084097", "222222" ]
- [ "", "1234qwer" ]
- [ "13603084097", "1234qwer" ]
- 在debugtalk中定义函数动态生成参数列表,然后调用。
def get_userid():
num=[]
for i in range(100):
num.append({"user_id":i})
return num
- 通过内置的parameterrize函数动态读取csv中的参数,适用于大数据场景。
注意:参数名称必须与csv文件中的第一行参数名称一致,顺序阔以不一致,个数也可以不一致。
parameters:
- casename-user-passwd: ${P(data/user-passwd.csv)}
如下:
1.读取并定义csv文件的参数
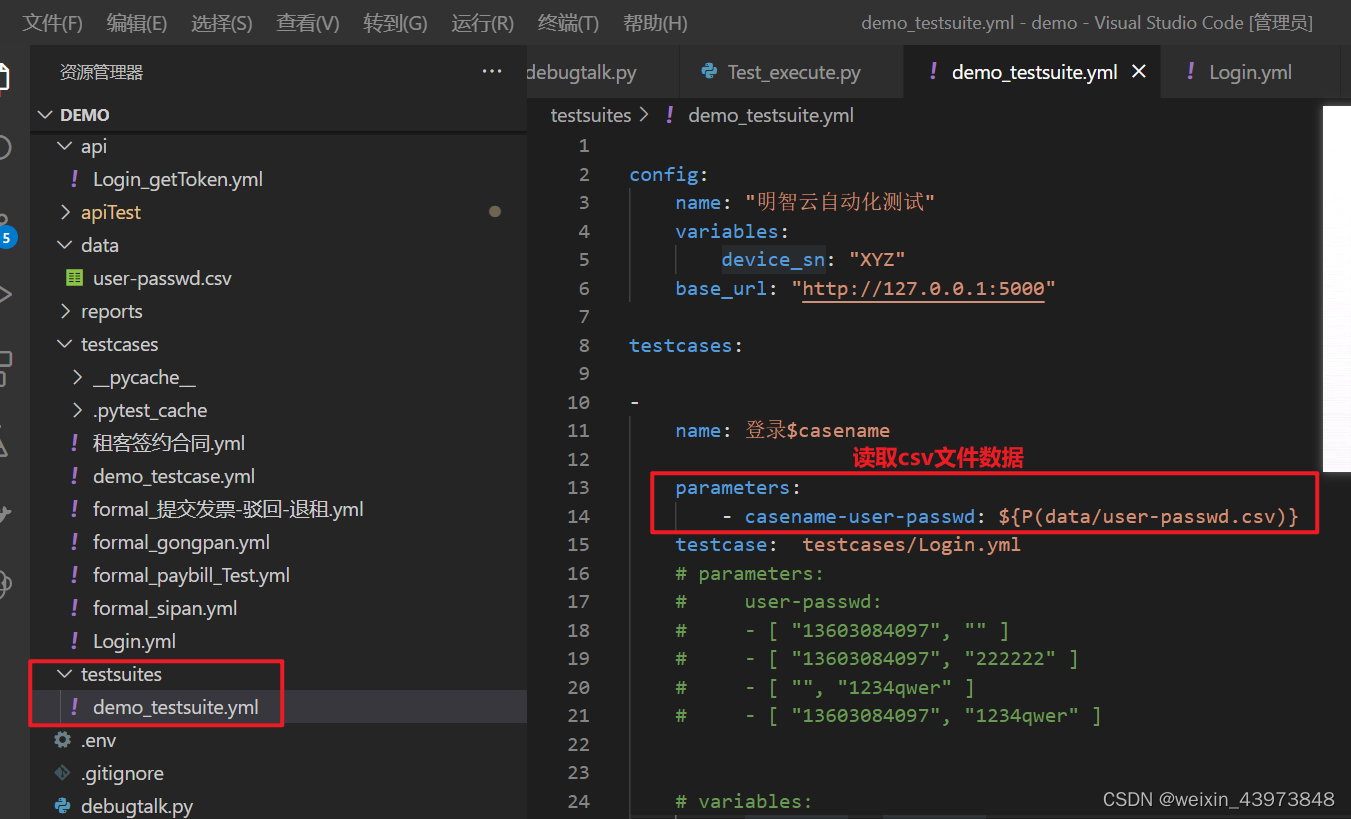
2.testsuite调用testcase中的接口,然后testcase又去调用api中的登录接口
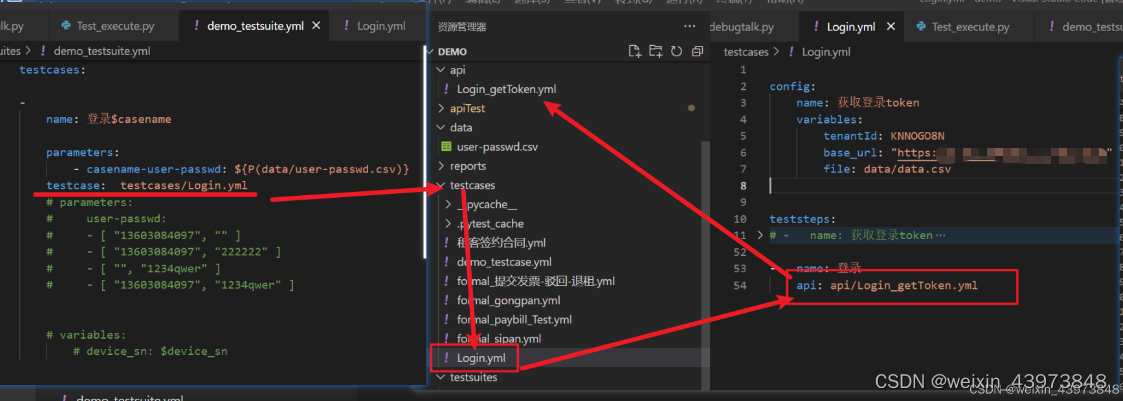
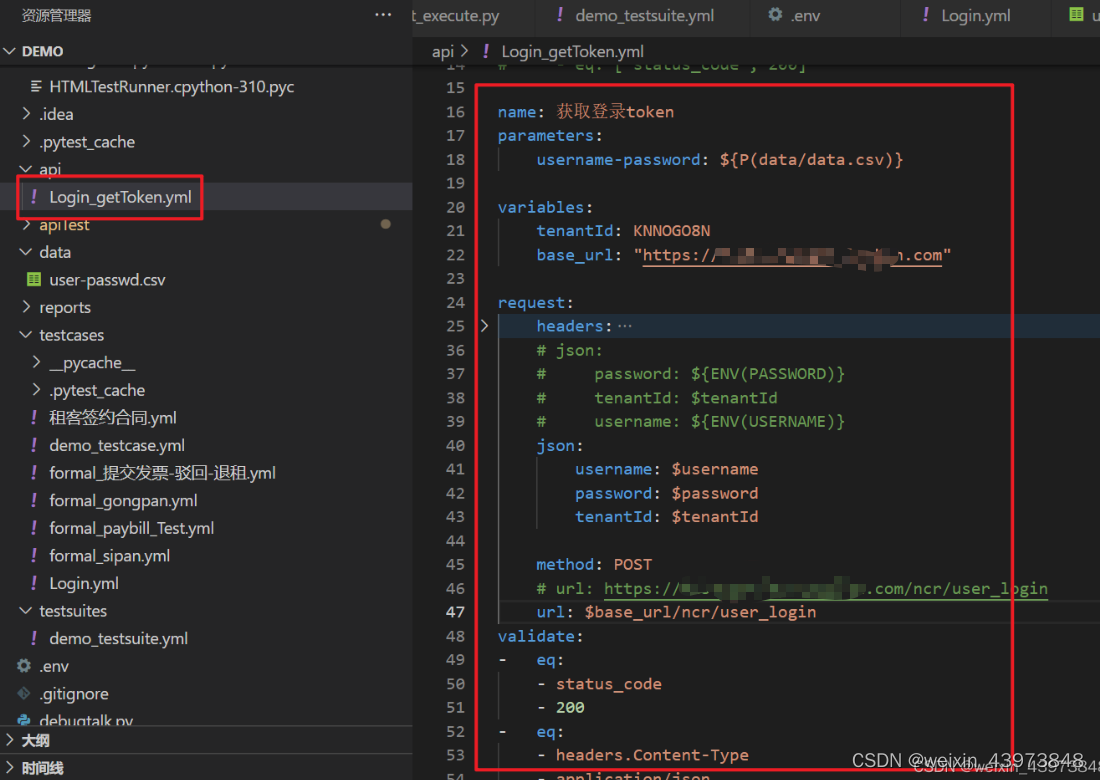
3.登录接口中的参数可以调用testsuite中读取出来的参数
name: 获取登录token
variables:
tenantId: KNNOGO8N
base_url: "https://xxx.com"
request:
headers:
Authorization: Bearer null
Content-Type: application/json
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-site
User-Agent: Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/118.0.0.0 Mobile Safari/537.36 Edg/118.0.2088.61
sec-ch-ua: '"Chromium";v="118", "Microsoft Edge";v="118", "Not=A?Brand";v="99"'
sec-ch-ua-mobile: ?1
sec-ch-ua-platform: '"Android"'
json:
username: $user
password: $passwd
tenantId: $tenantId
method: POST
url: $base_url/ncr/user_login
validate:
- eq:
- status_code
- 200
- eq:
- headers.Content-Type
- application/json
- eq:
- content.code
- '200'
- eq:
- content.msg
- success
extract:
token: content.data.token
环境变量的参数(一般放置环境参数,如url)
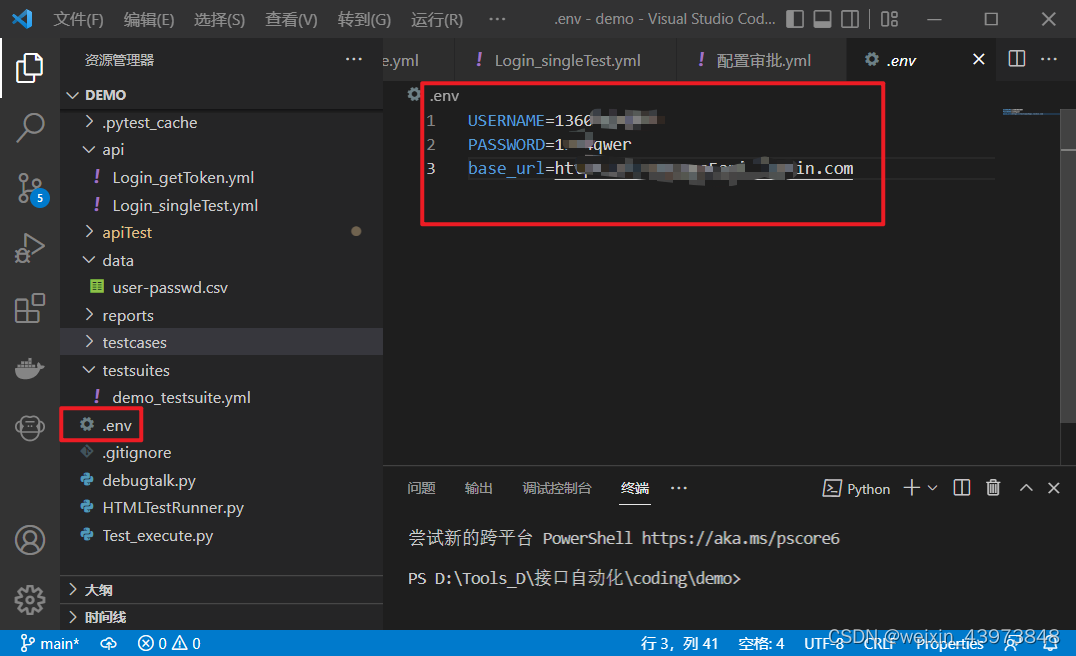
debugtalk文件的配置
写公共函数的逻辑实现,然后再对应得case中去调用需要的函数
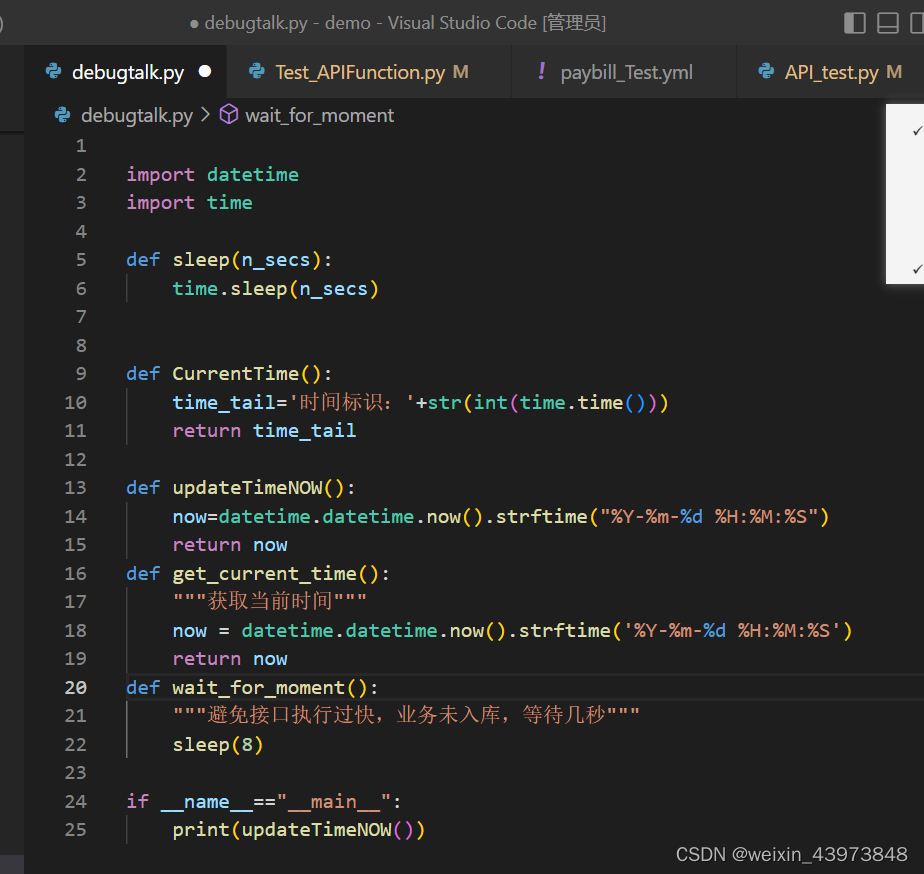
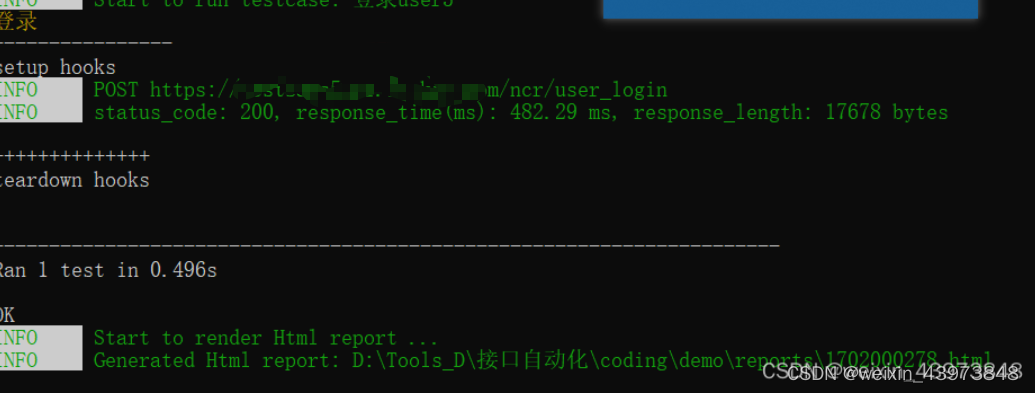
setup_hooks 和teardown_hooks
setup_hooks 和teardown_hooks主要用来辅助实现前后置操作。hook机制用于在测试步骤的开始或结束执行特定的操作,常用于进行辅助日志以及资源申请于回收等。
一次可以指定一个或多个hook函数对应的字符串列表。
首先,在debugtalk文件中定义好函数,然后再在case中调用。
config:
name: 获取登录token
variables:
tenantId: KNNOGO8N
# base_url: "https://xxxx.com"
file: data/data.csv
teststeps:
- name: 登录
setup_hooks:
- ${setup_hooksfun()}
- ${fun11()}
api: api/Login_singleTest.yml
teardown_hooks:
- ${teardown_hooksfun()}
日志等级配置
hrun D:\Tools_D\接口自动化\coding\demo\testcases\Test.yml --log-level debug
结果校验validation
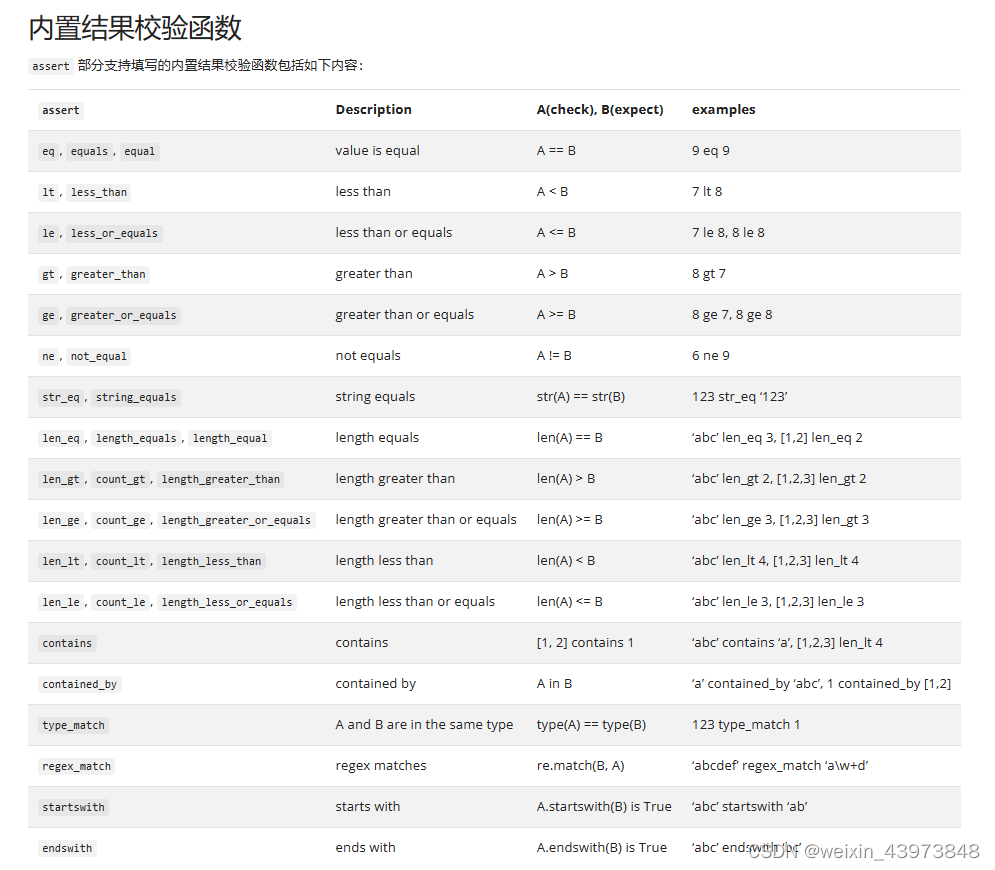
结果校验内容包含了 4 个字段,分别是字段提取表达式、断言函数、预期结果以及提示信息:
- 字段提取表达式:用于提取目标字段用作断言函数的输入,支持 jmespath 表达式和正则表达式(regex)两种提取方式,填写方式请参考参数提取(extract)章节
- 断言函数:顾名思义,就是用于对目标字段与预期结果是否满足相等、大小、包含、被包含等关系进行断言的函数,目前支持内置函数,不支持自定义拓展
- 预期结果:指定断言的预期结果,用作断言函数的另一个输入
- 提示信息:当前断言操作对应的提示信息,该字段为选填
示例 :
config:
name: validation demo
teststeps:
- name: get httpbin
request:
method: GET
url: https://www.httpbin.org
validate:
- check: status_code # target field, support both jmespath and regex
assert: eq # assertion method, you can use builtin method or custom defined function
expect: 200 # expected value, supposed to match target field
message: check status code # note message, optional
四、案例
通过列表下标取数据的准确性
在实际项目中,需要根据项目情况处理数据。特别是一些无法指定唯一的数据,需要一步一步确认验证,或在一个没有数据的环境跑一下。
如下案例:
问题:
在做某一个接口测试时,发现接口处理了分页,导致通过列表的下标-1获取的值并不是整个列表的最后一个值,而是第一页的最后一个值。
解决方案:
先通过list接口获取数据的总数量total,然后通过在debugtalk中处理,拿到的是最后一页准确数字,然后再传入接口参数中。
def get_lastPage(talentedNum):
#默认列表按照15条/页展示,并且做了规避奇,偶数条数据出现异常的处理
if talentedNum%15==0:
lastPage=talentedNum/15
else:
lastPage=int(talentedNum/15)+1
return lastPage















 1856
1856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









