







Task1 赛前准备
使用天池实验室进行比赛的数据分析
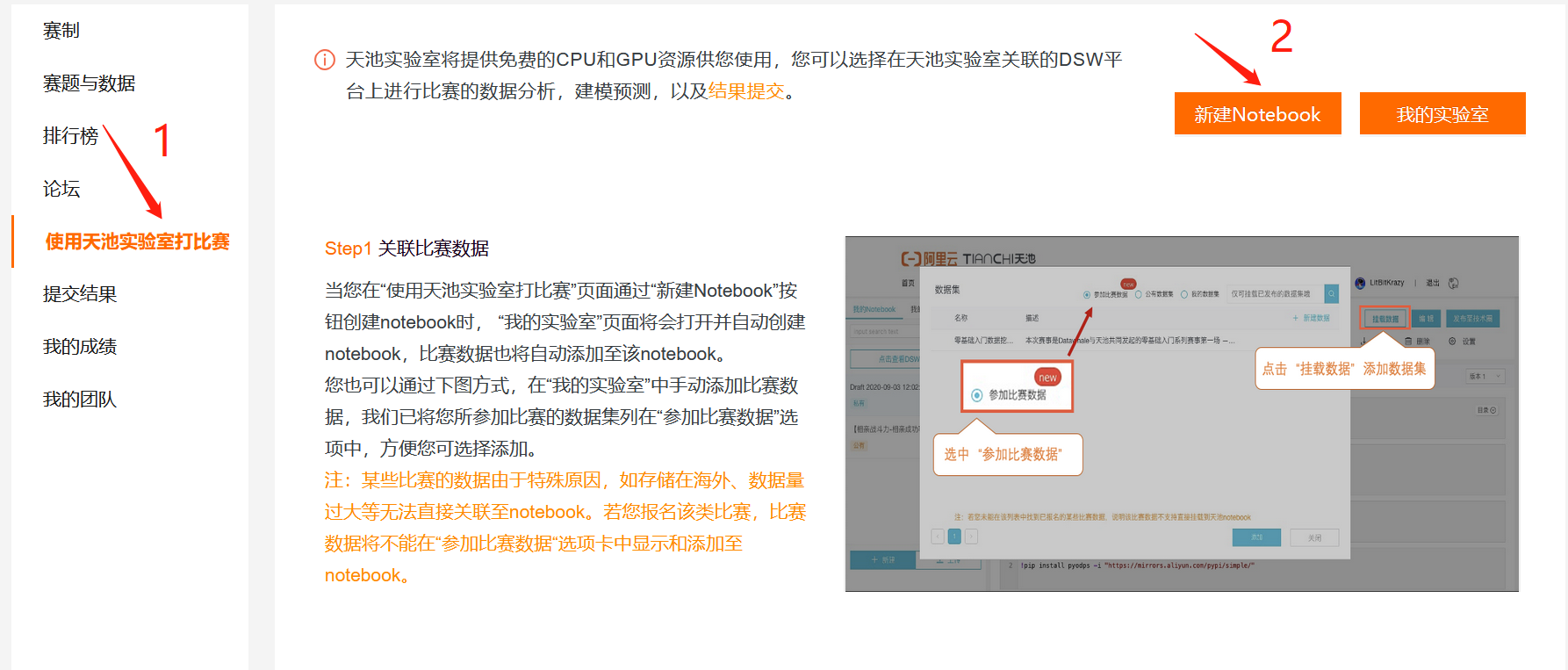
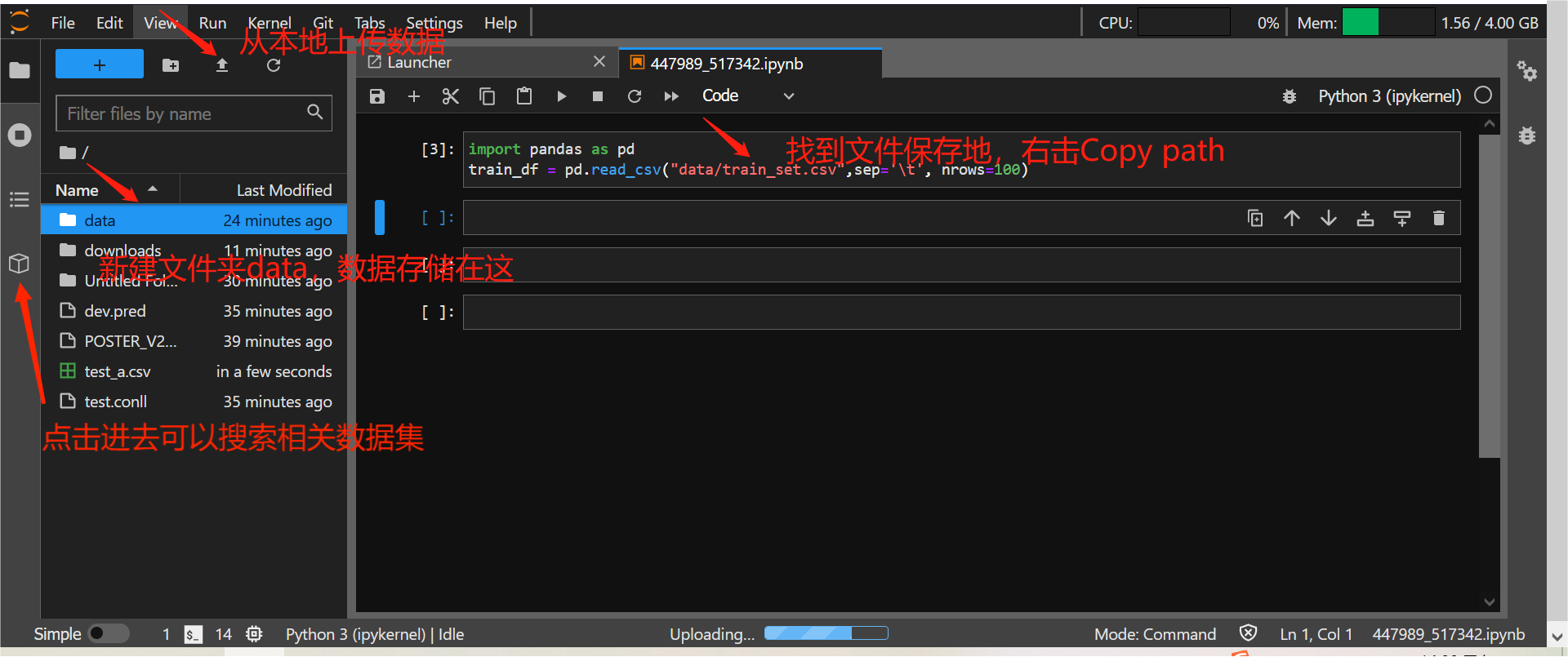
进入天池实验室,,用上图官方给出的挂载数据虽然提示添加成功但没有找到储存在哪,故下载到本地之后再次上传存储到data(失败了),从左侧第四个图标直接下载,直接用Pandas完成数据读取的操作。
Task2 数据读取与数据分析
Datawhale零基础入门NLP赛事 - Task2 数据读取与数据分析
一. 数据读取
import pandas as pd
train_df = pd.read_csv("data/train_set.csv",sep='\t', nrows=100)sep:每列的分割字符
nrows:表示读取的行数,这里表示先读取100行,正式训练时去掉即可
二. 数据分析
句子长度分析
#自动加载numpy和matplotlib库
%pylab inline
#获取每行句子的长度定义为新的一列'text_len'。每行句子的字符用空格分隔开,直接统计单词的个数来得到句子长度
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())apply(func,*args,**kwargs):对'text'这一列的每行文本进行括号内的函数处理,最后将所有结果组合成一个Series数据结构
lambda:匿名函数,对dataframe的一列进行特别操作
train_df['text']:根据列名text,并以Series(行索引+数值)的形式返回列。
describe():对于一维数组,会返回一系列参数,count,mean,std,min,25%,50%,75%,max。
#将句子长度绘制了直方图
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count")plt.hist():将一个大区间划分为等间隔的小区间,并统计每个区间上样本出现的频数之和。bins指定区间长度
新闻类别分布
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category").value_counts():返回一个Series数组,显示原数组中每类值出现的次数,bar表示柱状图
字符分布统计
统计每个字符出现的次数
#Counter可以支持方便、快速的计数,将元素数量统计,然后计数并返回一个字典,键为元素,值为元素个数
from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count))
print(word_count[0])
print(word_count[-1])sorted():降序(reverse = True),key=lambda x: x[i]:key自定义规则排序,按照x[i]进行排序;
word_count.items():返回字典键值对的元祖集合;
Counter可以支持方便、快速的计数,将元素数量统计,然后计数并返回一个字典,键为元素,值为元素个数。
统计了不同字符在句子中出现的次数
from collections import Counter
#以空格为分隔提取每个单词后存取set去重再转为list操作,得到去重后的text_unique列。
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0])
print(word_count[1])
print(word_count[2])
Q1:
import re
all_lines=' '.join(list(train_df['text']))
lines_count = len(re.split('[3750 900 648]',all_lines))
print(lines_count/train_df.shape[0])
print(lines_count)re.split(pattern, string[, maxsplit=0, flags=0])
pattern:匹配的字符串
string:需要切分的字符串
maxsplit:分隔次数,默认为0(即不限次数)
flags:标志位,用于控制正则表达式的匹配方式,比如:是否区分大小写















 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









