







习题3–1:
1.关于map的查询操作
实现的功能:确保从file中读出来的map没有set里有的值,比如set={a,the},文件中"the boy is a student"。去掉后变成map={{boy,1},{is,1},{student,1}}。
我的方法:
if (find(exclude_set.begin(), exclude_set.end(),
content) != exclude_set.end())
//!=即找不到
word_count[content]++;
content是从file读出的单词,每读出一个content就和set中元素一一比对,如果不是set里的单词,就放进map。
参考答案:
if (exclude_set.count(content))
continue;//如果返回不是0,说明已经存在,则跳过
word_count[content]++;
//创建一个key,并且+1,防止默认值为0,误以为不存在
收获:如果知道是一个容器,用容器共通操作可以降低代码量。
习题3–2、写一个Function Object:
实现:根据字符串长度来进行排序。
首先,sort(首地址,尾地址,比对方法),比对方法是sort在处理时采用的方法,该Function Object必须返回bool值
class size_LessThan
{public:
bool operator()(const string& s1, const string& s2)
{return s1.size() < s2.size();}
};
class greater_LessThan
{public:
bool operator()(const string& s1, const string& s2)
{return s1.size() > s2.size();}
};
调用方法sort(m_words.begin(), m_words.end(), size_LessThan());
如果把第三个参数换成函数会出现这样的提示:
//class greater_LessThan
//{
//public:
bool greater_LessThan(const string& s1, const string& s2)
{
return s1.size() > s2.size();
}
//};

但写成函数显然不实际,但是排序是针对所有元素的,指定某两个string就显得不实际了。
所以对于Function Object,我的理解是:给函数实现特定功能的工具,函数会调用这个Function Object,至于sort如何使用,对我们来说是不知道的,但知道他是为了实现排序功能。
习题3.3:
对于具有如下格式的txt.文件
Zhang San Liang Sanfeng Xueliang
Liu Xiang Yifei
Liang Jiahui Jingru
每一行的第一个单词为"姓",后面的单词都是“名”。读出全部内容,用map进行记录。
1、定义方法
map<string,vector<string>> name;
2、读文件的方法
2.1、按行读取
while (getline(namefile, textline))
{}
按一定条件读取文件,第三参数默认为换行。
这样第一次循环为:Zhang San Liang Sanfeng Xueliang
第一次循环为:Liu Xiang Yifei
…
2.2、读取单词的方法
用两个指针,一个在右pos,一个在左pre_pos。pos找到这一行下一个空格的位置,比如“Zhang San Liang Sanfeng Xueliang”,
第一次循环pre_pos=0,pos=5。则可以知道第一个单词长度为5,读出这五个字符。读出来后pos=5+1,pre_pos=pos。下一个循环。
第二次循环pre_pos=6,pos=9。则可以知道第二个单词长度为9-6=3,读出这3个字符。。。
必要的函数:1.textline.find_first_of(' ', possition),找到从possition为起点的第一个空格的地址,由于起点可能是空格,所以上面的循环中,读出字符后,要pos++,不然一直停在原地。
2.textline.substr(prev_possition, len_ofstr)把textline中从prev_pos开始,长度为 len_ofstr的string提出来
2.3、含有vector的map的数据查询
需要至少两个指针才能更加清晰:
第一个指针:map<string, vector>::const_iterator it = families.begin();
即指向这个map首地址的指针。
第二个指针:vector ::const_iterator vit = it->second.begin();
即指向map首地址的value的指针。
这样遍历"姓"可以通过以下代码
while(it!=families.end())
{
cout<<*(it->first);
it++;
}
遍历某一个"姓"下的名
while(vit!= (it->second.end())
{
cout<<*vit;
vit++;
}
贴个图吧
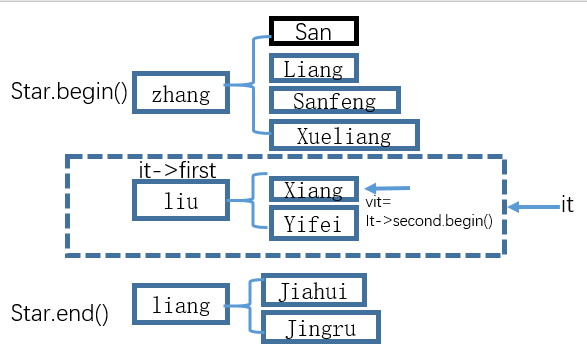
1.vit是不知道总共有多少个名字的,因此需要vit!= (it->second.end()确保其在有效范围内。
2.不管是姓还是名的尾地址都可以通过it知道。it->first即当前it位置的姓,it->second.begin()即当前it位置的名首地址。为了避免过长的指向关系,因此用vit=it->second.begin()















 1643
1643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









