







一、数据类型设计
原则:
1.更小通常更好,如能用tinyint就不用int
2.避免使用null,如账号密码字段设置非空
3.简单就好,如日期字段,不要使用varchar
1.整形
可以使用的几种整数类型:TINYINT,SMALLINT,MEDIUMINT,INT,BIGINT分别使用8,16,24,32,64位存储空间。
| 类型 | TINYINT | SMALLINT | MEDIUMINT | INT |
|---|---|---|---|---|
| 字节数 | 8 | 16 | 32 | 64 |
尽量使用满足需求的最小数据类型
2.字符和字符串类型
| 类型 | varchar | char | text | blob |
|---|---|---|---|---|
| 占用字节数 | 255字节的整数倍+(length>255?2:1),varchar(5)与varchar(255)占用相同的储存空间 | 255字节 | 可变 | 可变 |
| 储存数据格式 | 字节 | 字节 | 字节 | 二进制 |
| 最大值 | 可指定,65535字节 | 255字节 | 65535字节 | 65535字节 |
| 读写效率(性能) | 中等,长度超过500时与text相差无几 | 快 | 慢 | 慢 |
| 使用场景 | 1.长度波动大的字段 2.更新频率低的字段 3.适合多字节符号,如汉字。 | 1.长度固定的字段,如md5摘要 2.更新频繁的字段 | 1.长度比较大的文本 | 1.二进制文件,比较少用,一般用第三方文件系统代替。 |
3.时间类型
| 类型 | datetime | timestamp | date |
|---|---|---|---|
| 精确程度 | 毫秒 | 秒 | 天 |
| 范围 | 无限制 | 时间范围:1970-01-01到2038-01-19 | 无限制 |
4.枚举代替字符串
例子:
create table enum_test(e enum(‘fish’,‘apple’,‘dog’) not null);
字段e表面上储存的是’fish’,‘apple’,‘dog’,实际上储存的是0,1,2
证明:
insert into enum_test(e) values(‘fish’),(‘dog’),(‘apple’);
select e+0 from enum_test;

5.数值类型代替字符串类型
ip在存入时是可以用函数转化为数值类型,取出时再用函数转化回字符串
案例:
select inet_aton(‘1.1.1.1’)
select inet_ntoa(16843009)
二、范式的选择
| 范式 | 反范式 | |
|---|---|---|
| 优点 | 避免数据冗余(空间优先) | 避免关联表,降低查询IO次数(时间优先) |
| 缺点 | 多表关联时,效率可能会极低 | 可能造成大量数据冗余 |
范式的目的是为了避免数据冗余。
一般企业没有规定一定要遵循范式或反范式,合理平衡空间与时间才是关键。
反范式如用户表储存了姓名和地址,订单表也可以储存姓名和地址,可以避免多表关联以提高性能。
三、主键的选择
| 主键类型 | 代理主键,如uuid,雪花算法id | 自然主键,如自增id |
|---|---|---|
| 维护难易度 | 低,容易维护与迁移 | 高,数据库自己维护 |
| 占用空间 | 多点 | 少点 |
推荐使用代理id,在分库分表的场景下比较容易维护
四、字符集的选择
一般使用utf8mb4
略
五、存储引擎的选择
| MYISAM | INNODB | |
|---|---|---|
| 支持事务 | 否 | 是 |
| 支持行锁 | 否 | 是 |
| 支持表锁 | 是 | 是 |
| 支持外键 | 否 | 是 |
| 查询性能 | 相对较高 | 相对较低 |
| 更新性能(增删改) | 相对较低 | 相对较高 |
| 是否聚簇(就是索引和数据是否放一块) | 否 | 是 |
六、适当的拆分
如一张文章表储存了几个小字段(作者,发布时间等)和一个大字段(文章内容)。可以把大字段拆分到另外一张表,用主键关联。
七、索引
1.索引的优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机io变成顺序io
2.索引的用处
- 快速查找匹配WHERE(和order by,group by)子句的行
- 如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的min或max值
- 如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
3.索引的分类
- 主键索引
- 唯一索引
- 普通索引
- 全文索引(较少使用)
- 组合索引(就是以上索引组合使用)
4.索引的原理
这里只讨论B+树索引,不讨论哈希表索引,因为哈希表索引使用场景太少了
原理图:
其实索引原理就是B+树
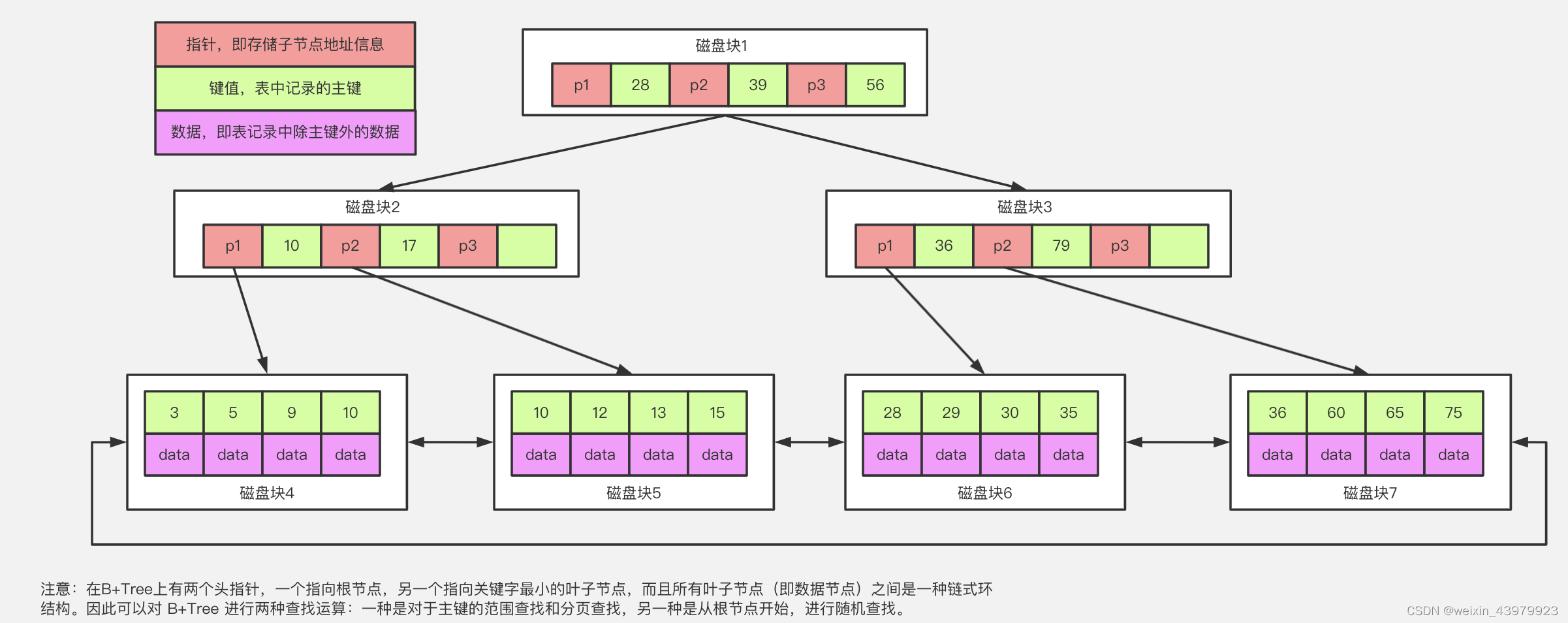
索引进化流程(从上往下进化)
| 模型 | 优点 | 缺点 | 时间复杂度 |
|---|---|---|---|
| 哈希表 | 结构简单,效率高 | 不支持范围查询 | O(1) |
| 二叉树 | 支持范围查找 | 顺序插入时,容易变成链表,复杂度升级为O(n),跟没有一样 | O(log(N)),最差O(n) |
| 平衡二叉树(AVL树,红黑树) | 支持范围查找了,复杂度也不会升级 | 高度太高了,复杂度O(log(N))还是太高了,而且频繁旋转也消耗性能 | O(log(N)) |
| B树 | 其实就是平衡多叉树,高度不高,复杂度也低 | 数据时以块储存的,节点如果分开储存不适合储存大量数据 | O(H)) |
| B+树(B树升级版) | 数据只放到子节点中,中间节点只存放索引本身数据,大量节省空间,且子节点相连更容易范围查找 | 已经相对完美了,但回表时依然会产生随机IO | O(H),H一般是3或4 |
| B*树(B+树升级版) | 同上,其实就是B+树的中间节点也前后相连 | 同上 | O(H),H一般是3或4 |
5.面试高频名词
指走非主键索引时,叶子节点只储存了列值和主键id,需要再通过主键id回到表中再走一次主键索引才能找到需要的列值
例如:
emp中有普通索引列(name)
select * from emp where name = “张三”
虽然走了普通索引,但是普通索引的叶子只储存了name=“张三”,id=3,mysql需要通过id再回到表中查一遍才能获取所有列
指不需要回表。依然是以上例子,如果查询的列就是叶子节点的数据,那就不需要通过id回到表中查了。
例如:
emp中有普通索引列(name)
select id,name from emp where name = “张三”
如果查多一个列就需要回表了
指组合索引的匹配规则,只能按照索引的顺序匹配
匹配规则:
如组合索引(a,b,c)
情况1:abc全是等值匹配。如where a=x and b=x and c=x,可完全利用索引a,b,c
情况2:ab全是等值匹配,如where a=x and b=x,可不完全利用索引a,b(用不到c)
情况3:ac全是等值匹配,如where a=x and c=x,只能利用索引a(用不到bc,因为跳过了b)
情况4:a是非等值匹配,bc等值匹配,如where a>x and b=x and c=x,只能利用索引a(用不到bc,因为遇到非等值a匹配后索引匹配就停止了)
情况5:a是等值匹配,bc非等值匹配,如where a=x and b>x and c>x,只能利用索引a,b(用不到c,因为遇到非等值b匹配后索引匹配就停止了)
指索引判断规则从server层下推到存储引擎层,不需要把数据判断放到server层缓存。
例子:组合索引(a,b,c)
where a=x and b=x时,其实mysql有2种选择:
1.先把a=x的数据全部拿出来缓存,然后再过滤b=x(有一次缓存的步骤)
伪代码:
var result = list(a=x)
result = filter(b=x)
2.在判断a=x时就同时判断了b=x
伪代码:
var result = list(a=x && b=x)
页分裂:从索引的原理图可知,叶子节点的数据是凑一块的,比如一个4k的磁盘块满负荷可以储存100条数据。但这些数据的id是不连续的,比如1,3,4,5,6…,少了2。此时我插入一条id=2的数据会发生什么?4k的磁盘块装不下了,只能分裂为2个4k块,每个4k块的储存空间>=2k(未充分利用空间)。
页合并:上面例子反过来想,如果我把id=2又删了,甚至删了更多的数据,又会发生什么?mysql会判断2个(或多个)磁盘块是否能合并成一个4k磁盘块。
6.索引匹配方式
- 全值匹配
- 匹配最左前缀(上面已说)
- 匹配列前缀(模糊匹配只能匹配开头的%)
- 匹配范围值
- 精确匹配某一列并范围匹配另外一列(同最左匹配,上面已说)
- 只访问索引的查询(就是覆盖索引)
7.索引使用的注意事项
- 不要过早建立索引。 原因:
1.可能数据量没想象中的大,不建立索引查询性能依然不低。建立索引反而浪费了储存空间。
2.过早建立索引可能会导致频繁页分裂,既浪费空间,又浪费了性能(页分裂也会消耗性能)














 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









