






简介
KNN,监督学习模型,支持分类与回归任务,通过定义距离方式,找到距离目标点最近的K个邻居,取它们的target均值或众数作为目标点target的预测值;
距离
-
欧式距离(L2范数):
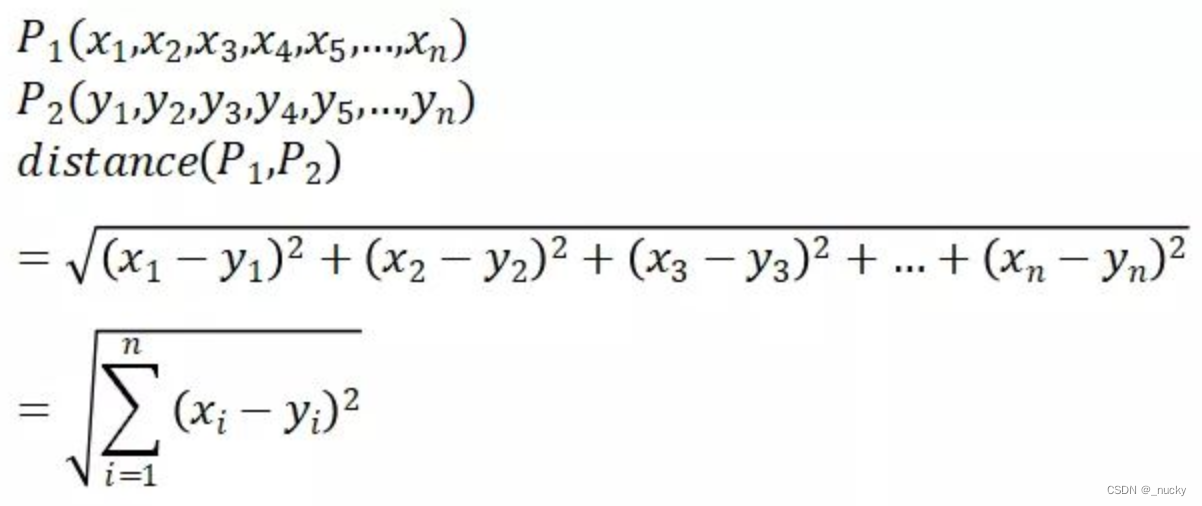
-
曼哈顿距离(L1范数):
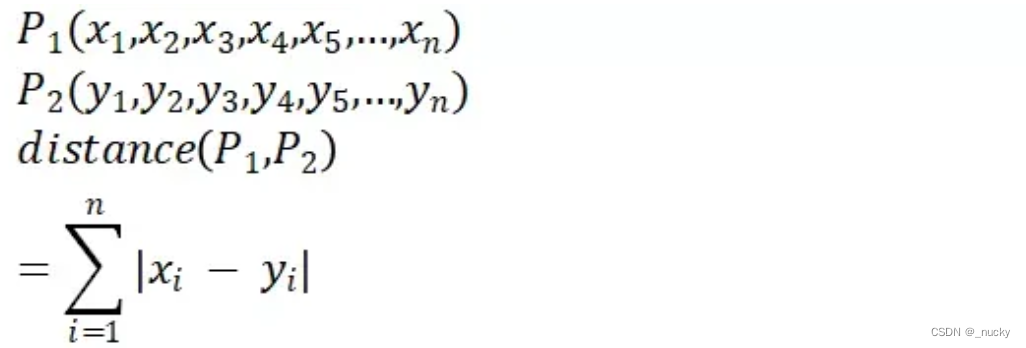
-
切比雪夫距离:
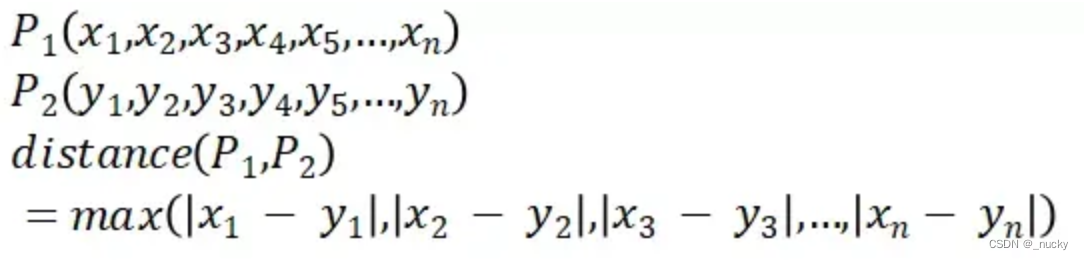
-
闵可夫斯基距离:
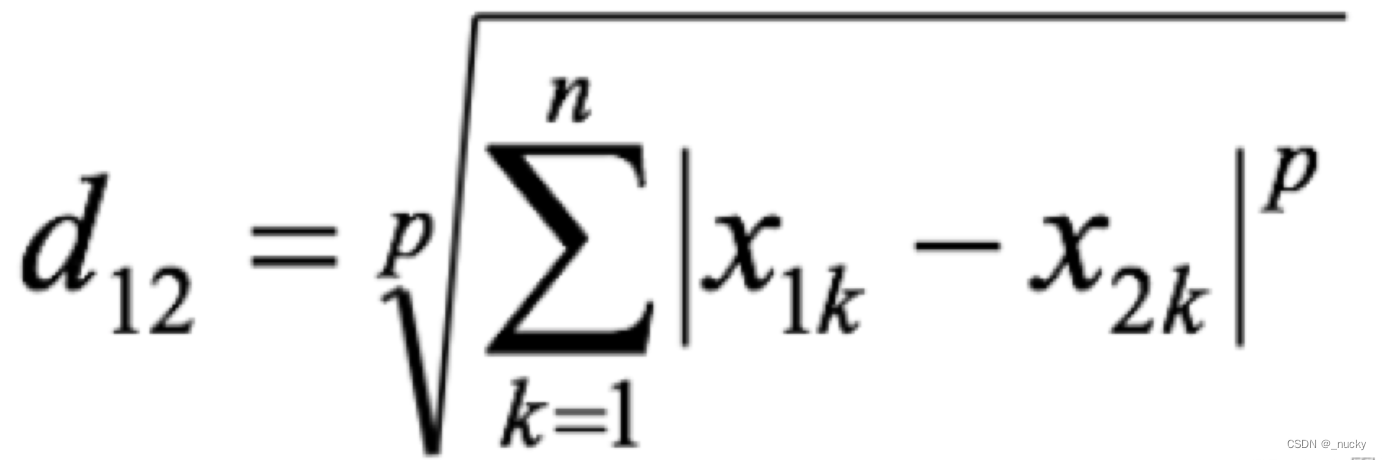
-
其他:余弦距离、汉明文本距离、杰卡德距离、马氏距离等;
K值选取
一般通过kfold交叉验证去选择一个表现最好且稳定的K;
sklearn实战
重要参数
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1):
# n_neighbors 最近邻样本数量 默认为5;
# weights 最近邻样本权重 "uniform"均权, "distance"权重与距离成反比;
# metric 距离计算方式 默认闵可夫斯基距离;
# p 距离计算方式 1为曼哈顿距离,2为欧式距离,趋近无穷大则为切比雪夫距离;
# n_jobs 并行处理任务数 -1则所有cpu参与计算;
class sklearn.neighbors.KNeighborsRegressor(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=1):
# 同上;
分类与回归任务
# 分类任务
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# 威斯康星-乳腺癌数据
data = datasets.load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data["data"], data["target"], test_size=0.3, random_state=41)
# KNN分类
model = KNeighborsClassifier()
model.fit(X_train, y_train)
print("train acc: ", model.score(X_train, y_train))
print("test acc: ", model.score(X_test, y_test))
# 回归任务
from sklearn import datasets
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split
# 糖尿病数据
data = datasets.load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(data["data"], data["target"], test_size=0.3, random_state=42)
# KNN回归
model = KNeighborsRegressor()
model.fit(X_train, y_train)
print("train loss: ", model.score(X_train, y_train))
print("test loss: ", model.score(X_test, y_test))
优缺点
- 优点:算法简单,对分类回归任务均可支持,对异常值不敏感;
- 缺点:距离计算空间复杂度高、分类任务容易受到不均衡样本集影响;
参考
https://blog.csdn.net/itcast_cn/article/details/125186202
https://blog.csdn.net/qq_25990967/article/details/122748881
https://blog.csdn.net/weixin_39345735/article/details/105014581
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









