






最近学习时序数据的处理,但现实的时序数据存在某些日期数值的缺失,要根据其前后几天的数值进行插值
原始数据
给出原始的数据形式11.csv文件格式如下,要对dura进行填充
seniorID,date,dura
145116054891300800,2018-03-20,1
145116054891300800,2018-03-16,0
145116054891300800,2018-03-17,3
145116054891300800,2018-03-20,3
145116054891300800,2018-03-24,3
代码实现
# 字符串转为日期
def string_to_date(str):
return datetime.datetime.strptime(str, "%Y-%m-%d")
# 对11.csv进行插值
def date_insert():
# 读取csv
df1 = pd.read_csv('11.csv', encoding='utf-8')
# 这里是为了将df1的date列的str格式转为年月日时分秒的形式
date0 = []
for dt in df1['date']:
date0.append(string_to_date(dt))
# df1['date'] = 2019-1-1 00:00:00
df1['date'] = date0
# 生成包含df1所有日期的辅助dataframe:df2
# df2['date']格式为2019-1-1 00:00:00
df2 = pd.DataFrame({'date': pd.date_range(df1['date'].min(), df1['date'].max())})
# 合并df1,df2,on表示在date列上合并,how表示同时保留df1、df2并且对缺失值填充为NaN,并且按照日期排序好
df = pd.merge(df1, df2, on='date', how='outer').sort_values('date')
# 对dura的缺失值进行线性插值
df['dura'] = df['dura'].interpolate(method='linear')
return df
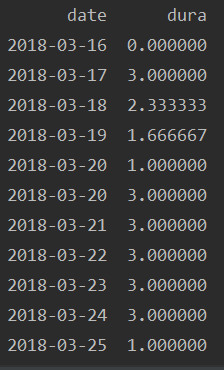
填充后















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









