







Python数值分析:那些好像会的基础(一)
我的python学得非常随意,基本上没学,就是直接来用,所以python经常给我一种熟悉的陌生人的感觉。你时不时会见到他,打个招呼,但是一问他家在几楼呀,他吃不吃香菜啊,喜不喜欢刘诗诗啊,就懵住了。就是有点“解释性深度错觉”的意思。
所以复盘一点点近期用到的基础。
Pandas追加写入
L2_78=[[1,1,1,1,1,1,1],[1,1,1,2,2,2,2],[1,2,2,1,1,2,2],[1,2,2,2,2,1,1],[2,1,2,1,2,1,2],[2,1,2,2,1,2,1],[2,2,1,1,2,2,1],[2,2,1,2,1,1,2]]
df4 = pd.DataFrame(data = L2_78)
with pd.ExcelWriter("hw.xlsx",engine="openpyxl",mode='a') as writer:
df4.to_excel(writer,sheet_name="L2_78")
注意写入xlsx文件,要指定engine为openpyxl
参考二
行追加(startrow)或列追加写入同一个sheet
writer = pd.ExcelWriter(filepath)
data = pd.read_excel(writer, index_col=None, header=None)
data.to_excel(writer, startrow=0, index=None, header=None, sheet_name='Sheet1')
df.to_excel(writer, startrow=data.shape[0], index=None, header=None, sheet_name='Sheet1', encoding='utf-8')
writer.save()
df_all = pd.DataFrame(data=None) # 创建空的 dataframe
df = pd.read_excel(file_path, header=0, sheet_name='Sheet1')
df_all = pd.concat([df_all, df], ignore_index=True) # concat 合并有相同字段名的dataframe
data_list = df_all.drop_duplicates(keep='first') # 避免字段名重复写入,去重处理
df_all.to_excel(out_path, index=False, encoding='utf-8')
关于作图
matplotlib的作图参考
感觉大概知道基操,别的用的时候查就可以了。
plt.figure()是创建一个画布,ax是图形,也就是作的图。可以通过设置num=1, num=2…来标识画布,没有设置则默认创建一个新的画布,num递增。
fig,ax= plt.subplots(), 返回的ax是一个二维数组。例如fig,ax = plt.subplots(1,2),创建一行两列的图形。可以flatten,也可以ax[0,1]…
fig4 = plt.figure()
ax= fig4.add_subplot(121)
ax.plot(xvalues,yvalues,'bo')
ax.set_title('before interpolation')
ax = fig4.add_subplot(122)
ax.plot(xx,yy)
ax.set_title("after interpolation")
plt.show()
fig5,ax = plt.subplots(1,2)
axes = ax.flatten()
axes[0].plot(xvalues, yvalues, 'bo')
axes[0].set_title("before")
axes[1].plot(xx, yy)
axes[1].set_title("after")
plt.show()
numpy
可以通过numpy.array()函数传递序列对象创建数组
astype可对数组的元素类型进行转换
python 的is比较内存地址。 用astype进行转换时不改变原始数组。
mport numpy as np
nums = [1,2,3]
num_array = np.array(nums)
num_array1 = np.array(nums, dtype=np.int64)
num_array2 = np.array(nums, dtype=np.int32)
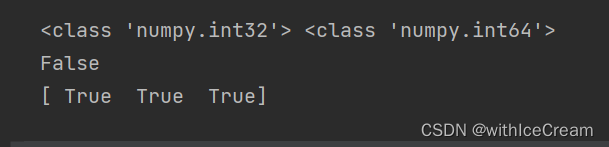
print(num_array.dtype, num_array.dtype.type, type(nums), num_array1.dtype.type, num_array2.dtype)
num_array3 = num_array2.astype(np.int64)
print(num_array2.dtype.type, num_array3.dtype.type)
print(num_array2 is num_array3)
print(num_array2 == num_array3)
um_array4 = num_array3
num_array5 = num_array3.copy()
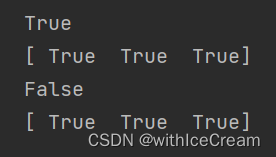
print(num_array3 is num_array4)
print(num_array3 == num_array4)
print(num_array3 is num_array5)
print(num_array3 == num_array5)
numpy的数值对象运算速度比python中内置类型的运算速度快。timeit可以测试代码的运行速度
from timeit import timeit
num1 = 2.89
num2 = np.float64(num1)
def func1(x):
return x*x
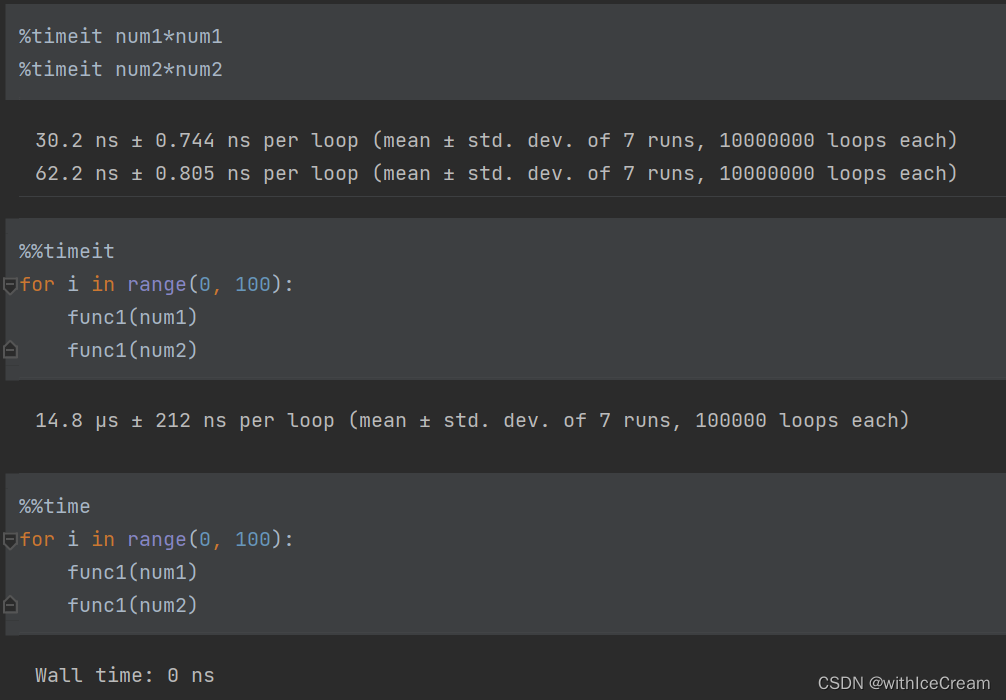
print(timeit("func1(num1)",'from __main__ import func1, num1, num2', number=100000))
print(timeit("func1(num2)", 'from __main__ import func1, num1, num2',number=100000))
%timeit调用timeit模块对当行语句执行多次,%%timeit测试整个单元的执行时间,%time命令只执行一次。
关于性能分析,IPython有很多魔法命令,先到这里了,以后再看。
线性代数
主要是numpy和scipy的linalg库
先不写了。。。。
















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









