








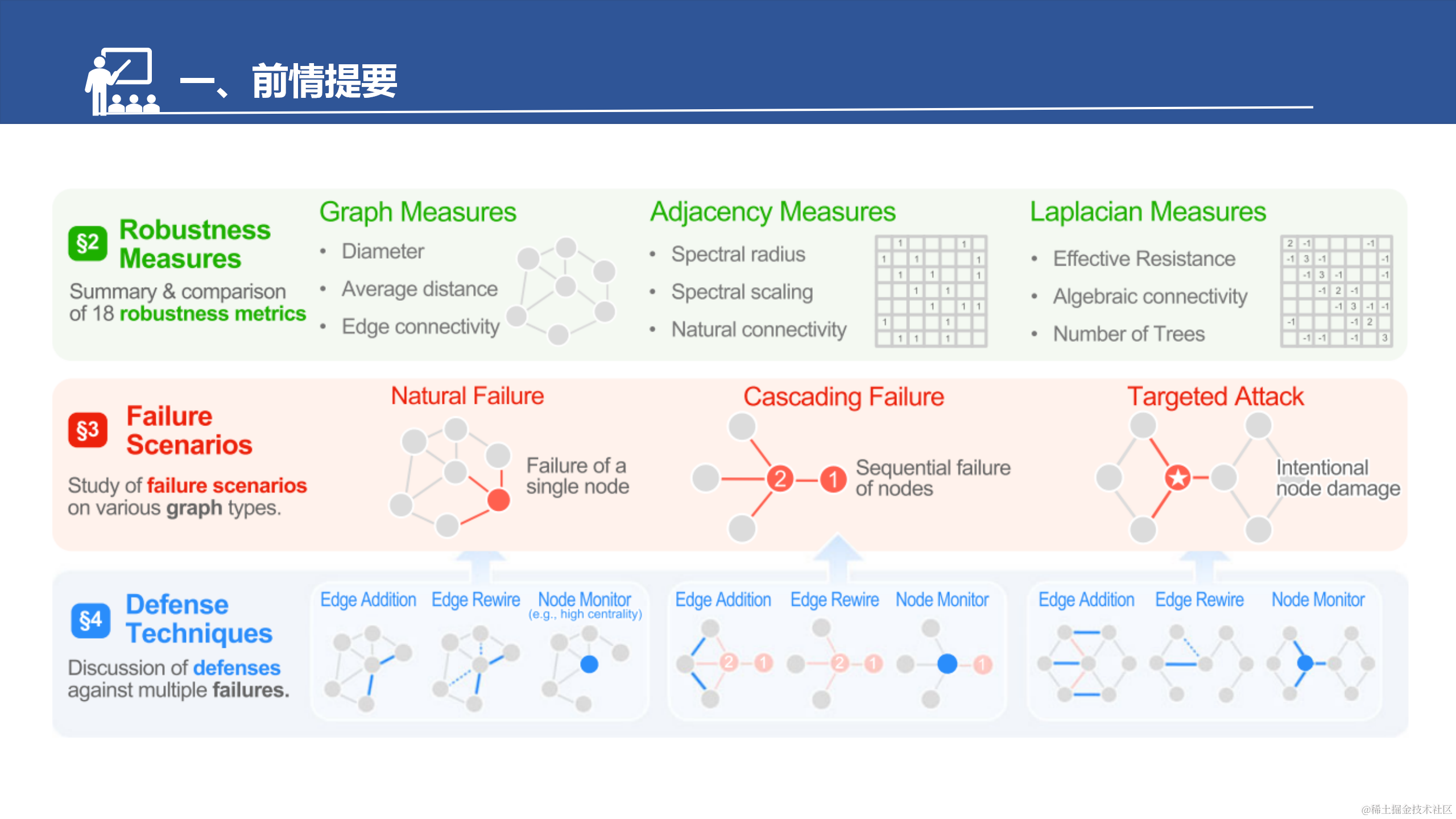
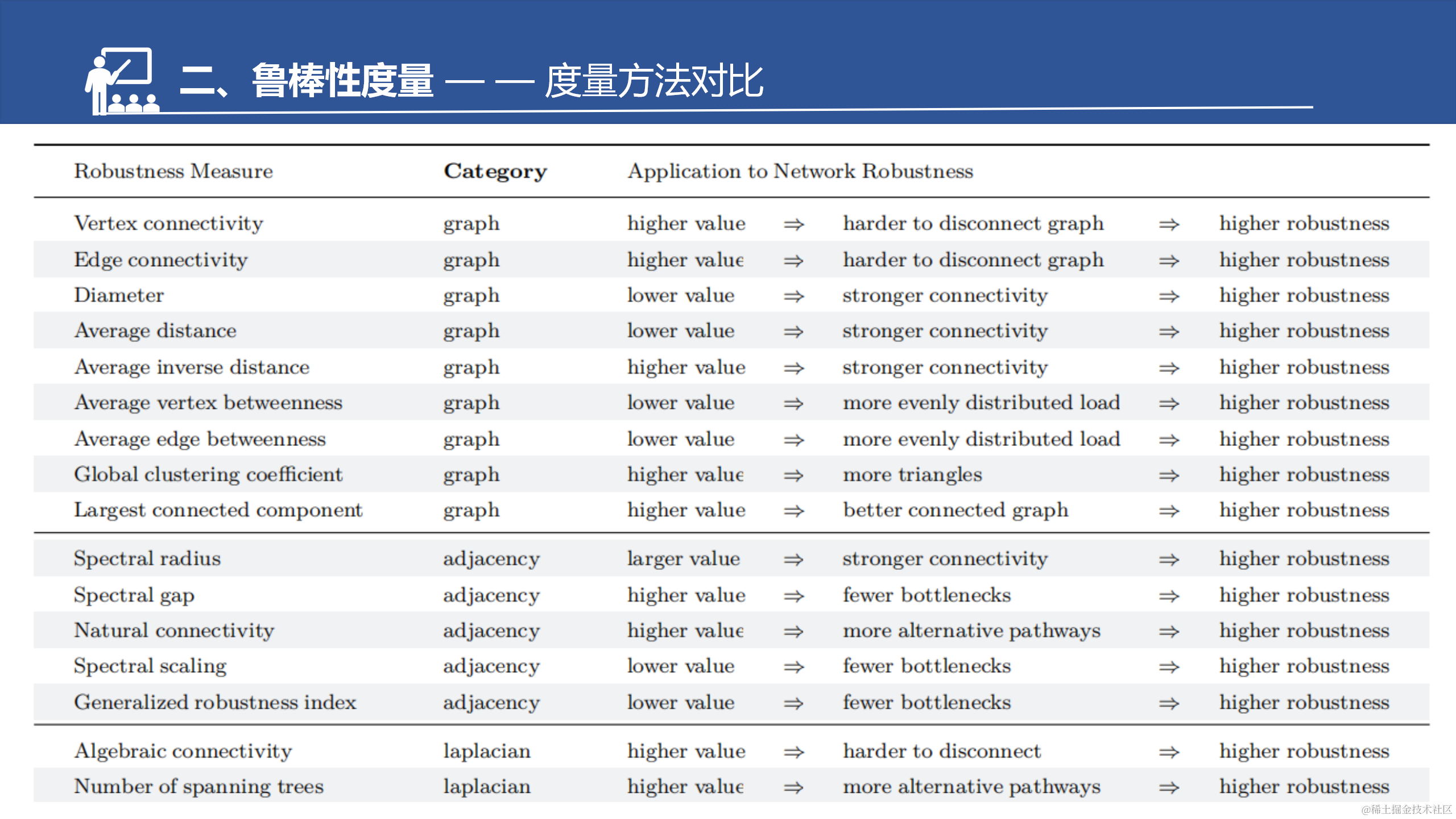
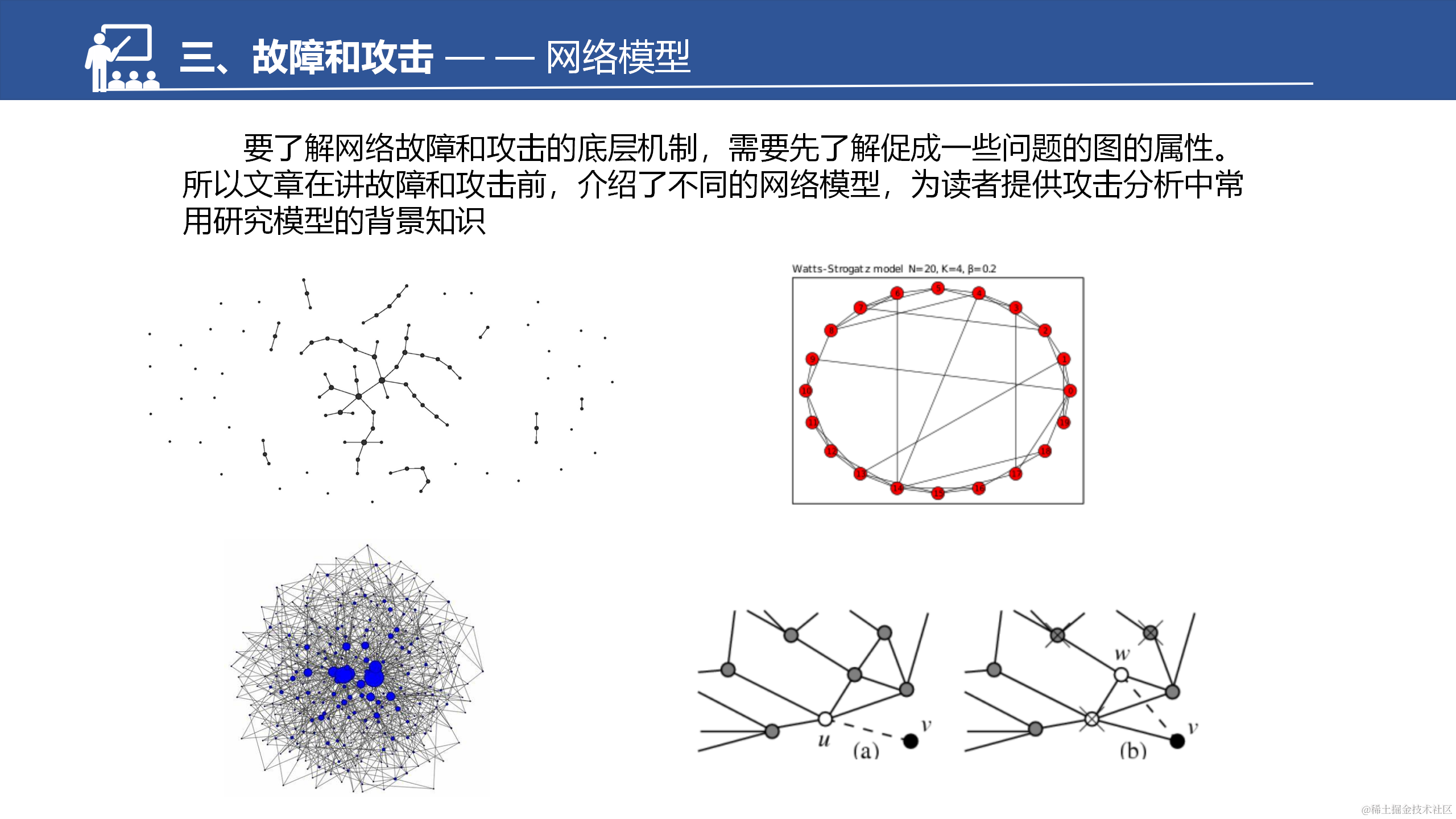
因为是综述,所以只能提供对该方向的一个宏观上的了解。对于文中的一些直接结论,我适当补充了其他参考文献中的图表和解释。若对于某些具体细节感兴趣的话,需要进一步阅读相关文献。











德尔塔是度数,代表着v有几个邻居,德尔塔 * (德尔塔-1)代表着所有邻居之间可以存在的边数


邻接矩阵定义,谱的定义



虽然第一个公式看不出来,但下面讲了推导过程,计算封闭游走,封闭游走越多,即使断开一些边,节点之间还是能连通


因为是综述,关于谱缩放和广义鲁棒性指数没有讲太具体,详细信息可以在做相关研究需要用到时再去深入了解。

A 为 G 的邻接矩阵; G 的度矩阵

行数之和为0:
拉普拉斯矩阵的行数之和为0,是因为拉普拉斯矩阵是由图的邻接矩阵和度矩阵构建而成的。度矩阵是一个对角矩阵,矩阵的每个元素对应图中对应节点的度(即与该节点相连的边的数量)。而邻接矩阵是一个二元矩阵,表示了图中节点之间的连接关系,如果两个节点之间有边相连,则对应的邻接矩阵元素为1,否则为0。由于拉普拉斯矩阵是由度矩阵和邻接矩阵相减得到的,所以拉普拉斯矩阵的某一行的元素之和就等于对应节点的度减去与该节点相连的边的数量,即为0。换句话说,对于任意一个图中的节点,它的度恰好等于与其相连的边的数量。



文章举了几个例子,这是其中一个比较直观的。
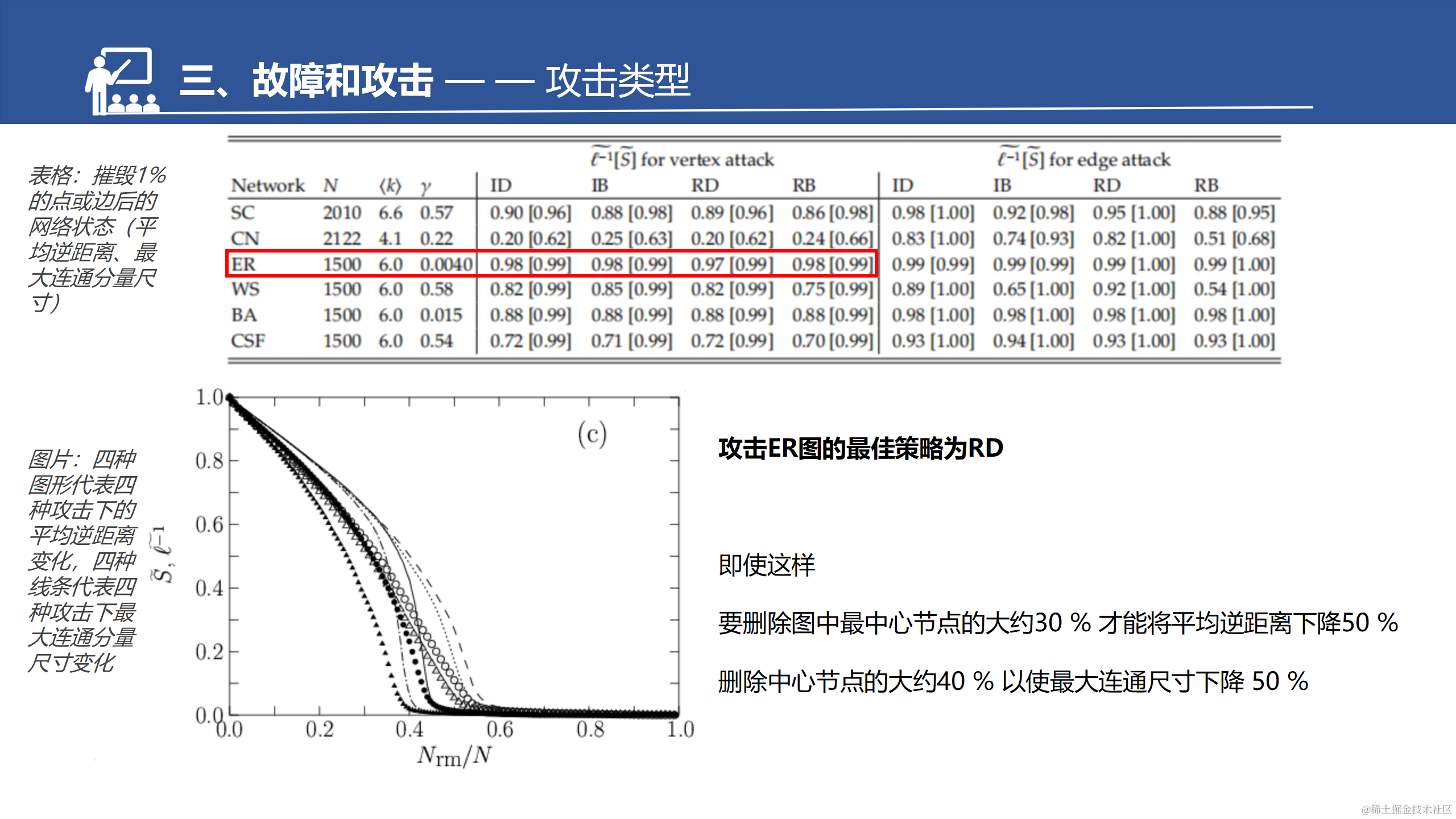
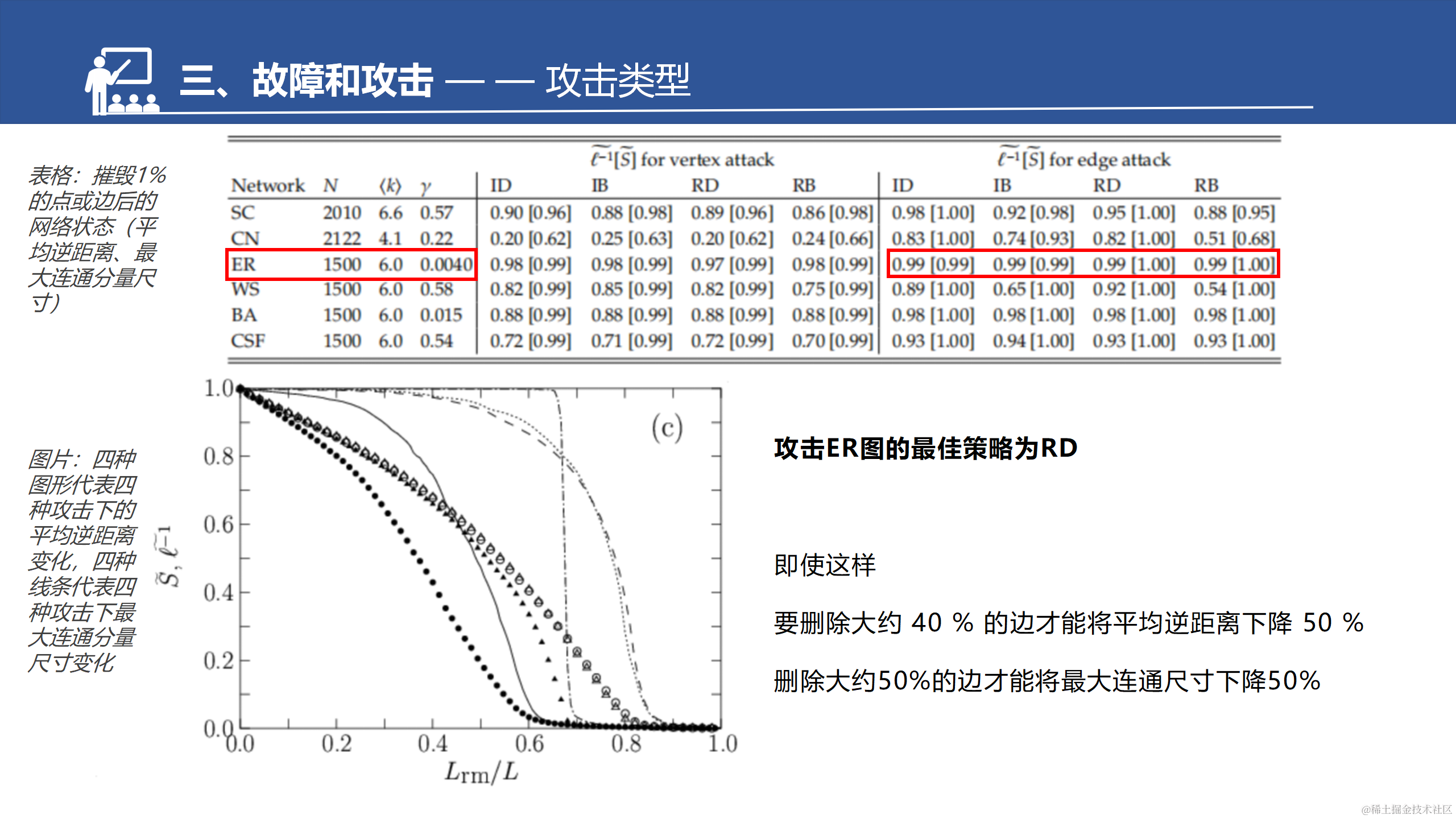
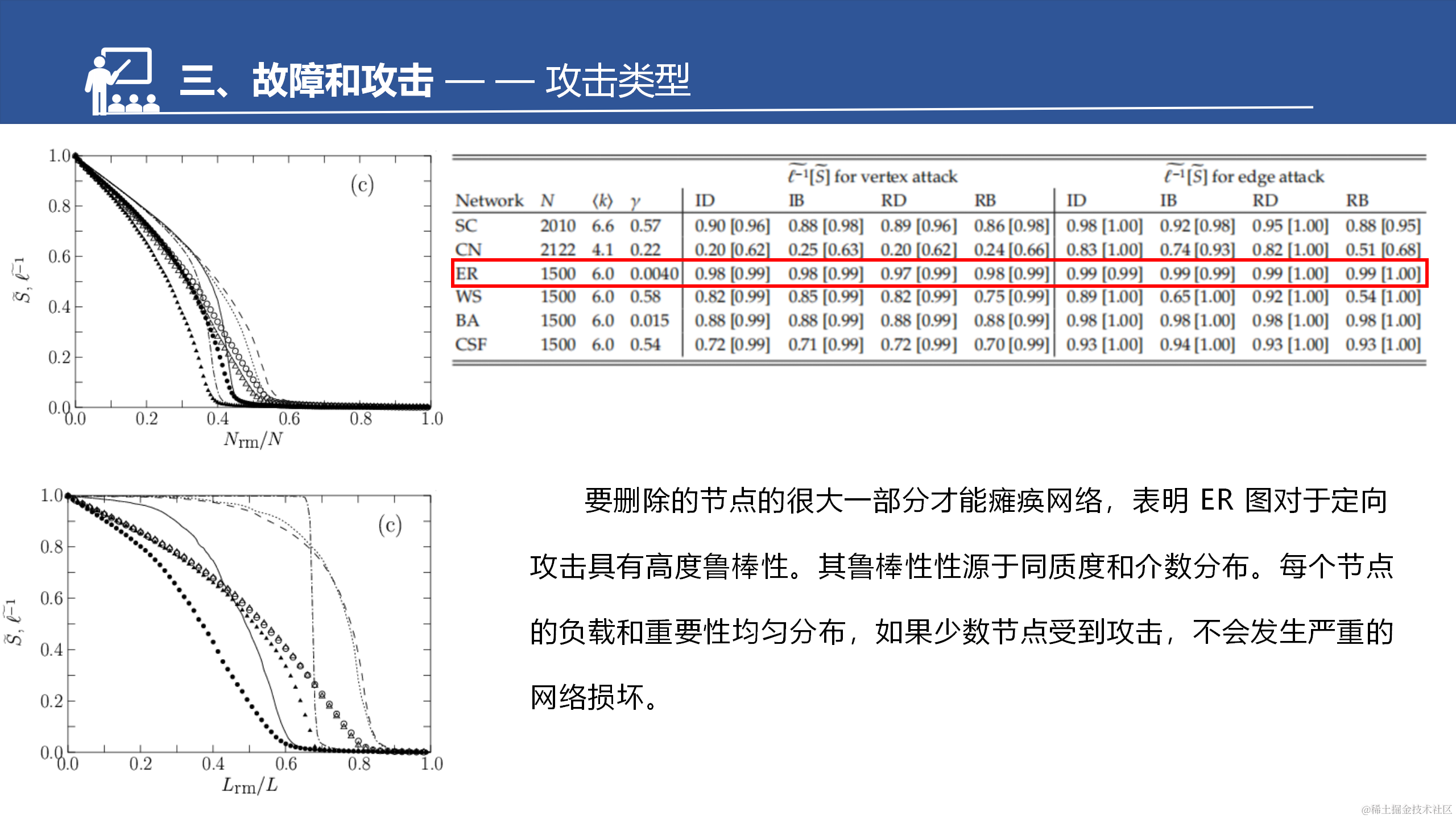
接下来是攻击和防御,都涉及到关键点识别,文章刚才介绍的一系列鲁棒性度量方法提供了关键点识别的理论基础
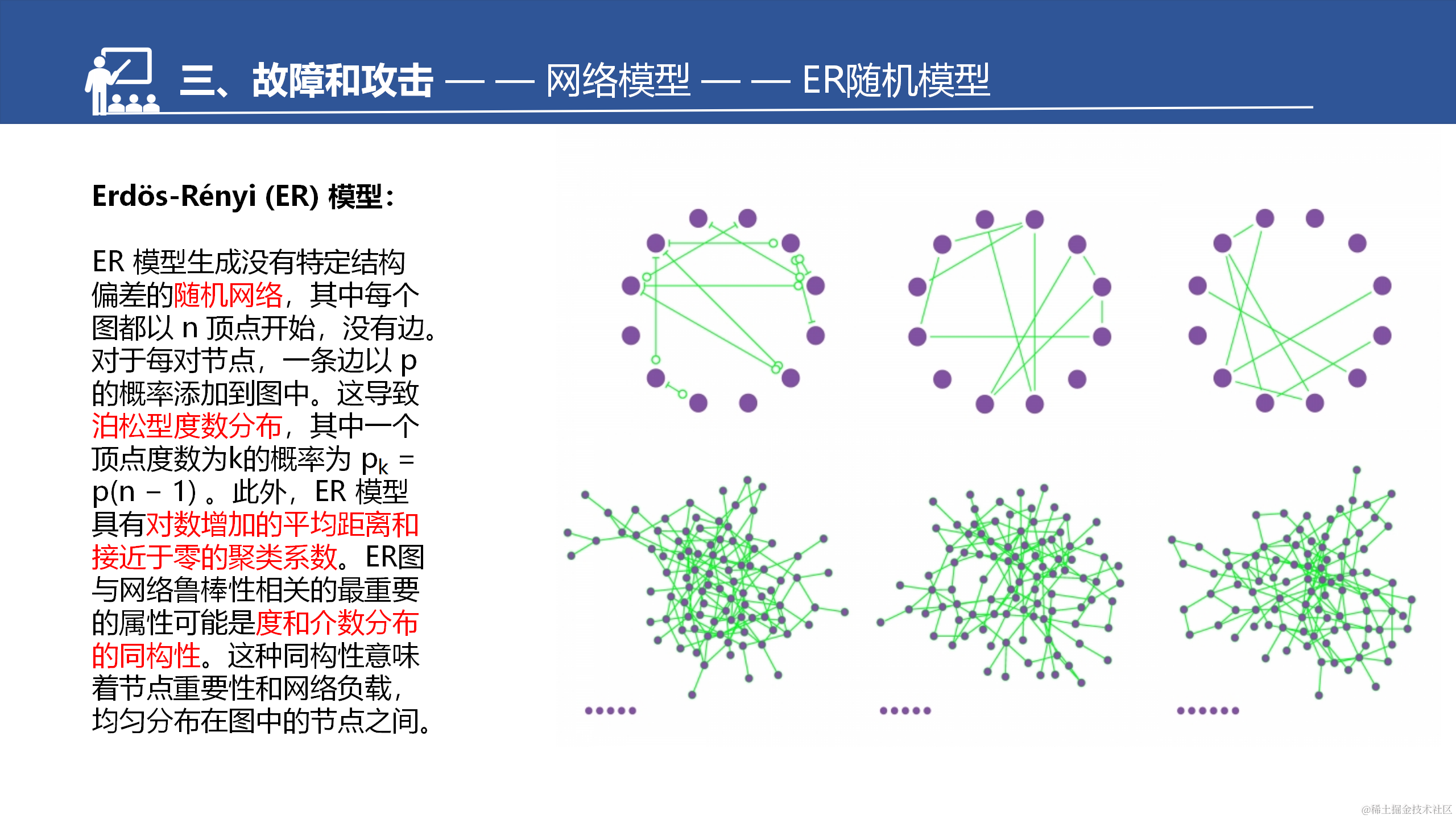
(1)
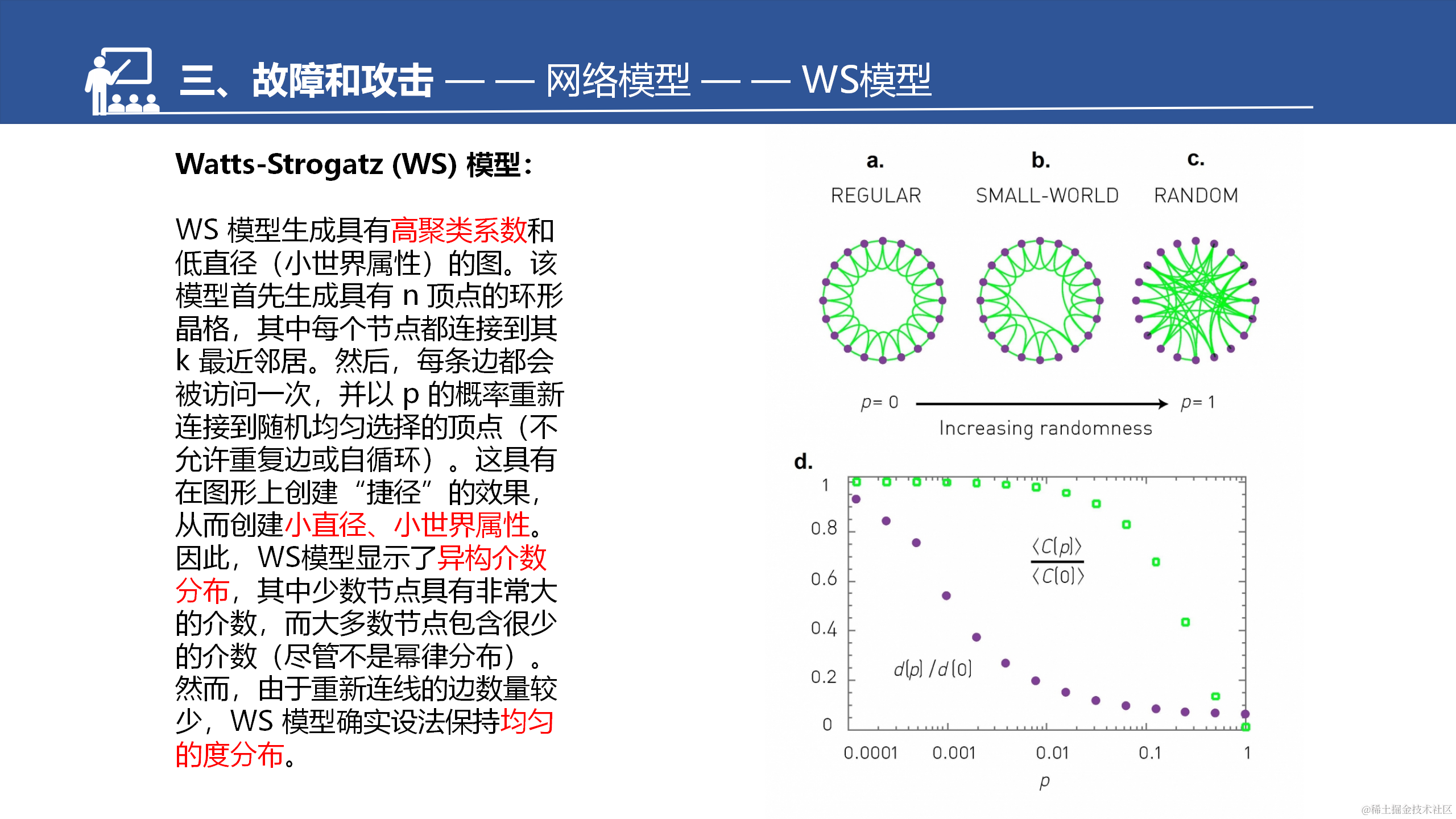
首先从节点环开始,每个节点和它的直接邻居及二阶邻居相连。因此,初始时,每个节点有C=3/4(p=0)。(2)
每条链接以概率p重连到一个随机选择的节点。当p较小时,网络仍然保持高聚集性,不过随机连接带来的“长程边”可以大大缩短节点间的距离。(3)
当p=1时,所有链接都进行了重连,网络变成了随机网络。(4)
平均路径长度d§和集聚系数〈C(p)〉 对重连参数p的依赖性。注意,d§和〈C(p)〉已经分别使用d(0)和〈C(0)〉 进行了归一化,这里的d(0)和 〈C(0)〉是从最初的规则格子网络中得出的(图a所示的p=0的情况)。d§的快速下降标志着小世界现象的发生。在d§的下降过程中,〈C(p)〉 仍然保持很高的数值。因此,在0.001<p<0.1的范围内,低直径,短平均距离,高聚集性共存。这里的所有图,都有N=1 000和 平均度=10。

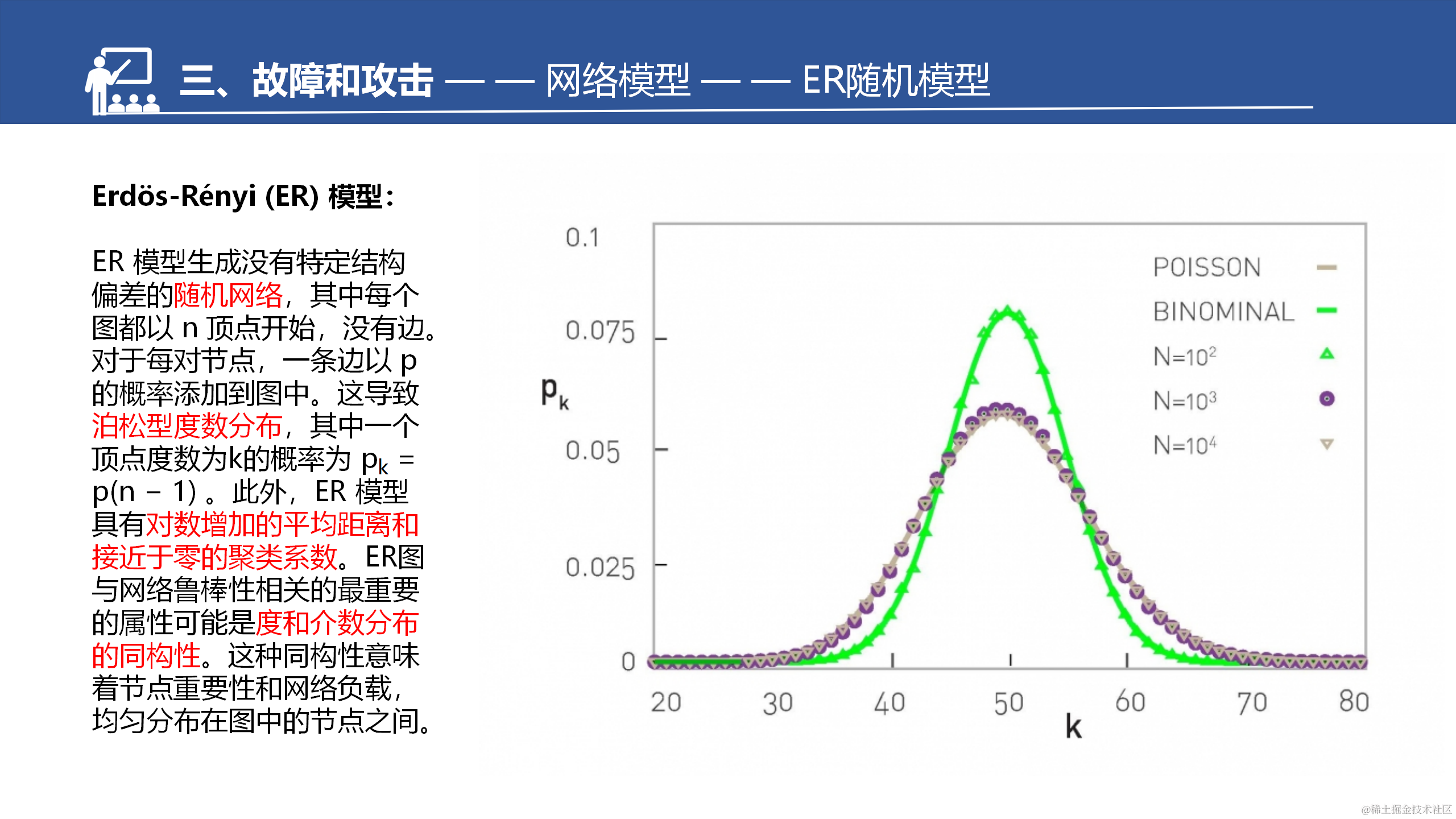
在一些真实的复杂网络中,例如社交网络、因特网和蛋白质相互作用网络等,观察到的度分布往往呈现幂律分布的特征。这意味着这些网络中存在一小部分节点具有非常高的度数,而绝大多数节点的度数相对较低。这种幂律分布表明节点连接的不均匀性和网络的无标度特性。
相比之下,泊松分布描述的是节点的度数在一个特定范围内以固定的平均值进行随机分布。泊松分布假设了节点度数之间是相互独立和随机的,而实际的复杂网络中存在许多复杂的机制和因素,如节点增长、优先连接和社区结构等,使得度分布更贴近幂律分布。


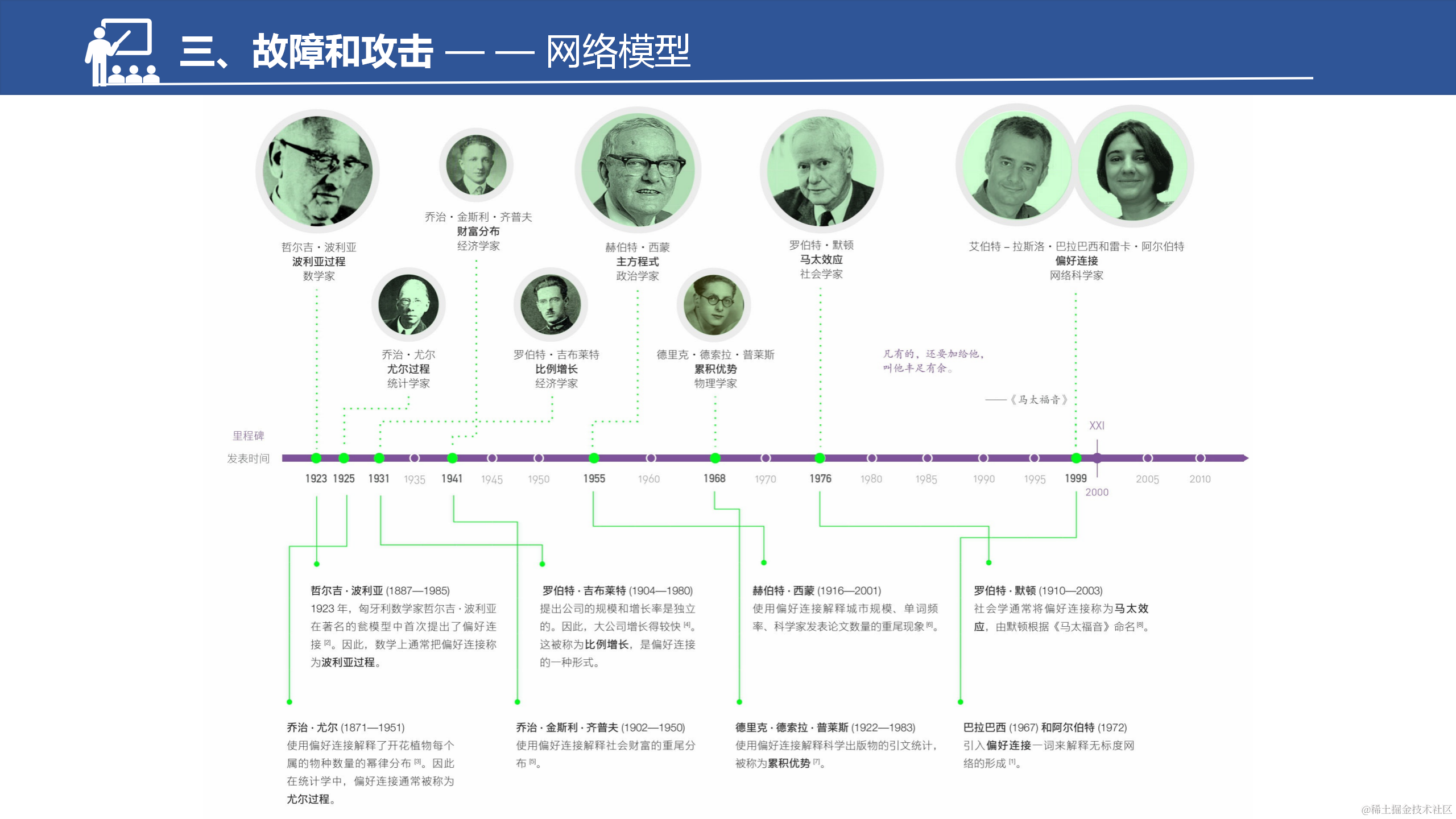
图片是偏好连接的简史,很早的时候在别的领域就有这个概念,但是1999年巴拉巴西将其引入网络科学,在认识到真实网络中生长和偏好连接的属性存在之后,提出了无标度网络。

这组图片展示了巴拉巴西-阿尔伯特模型连续9个时间步的生长情况。空心圆圈表示网络中新加入的节点,这些节点根据偏好连接机制(公式4.1)选择将它的两条链接(m=2)连向网络中存在的其他节点。
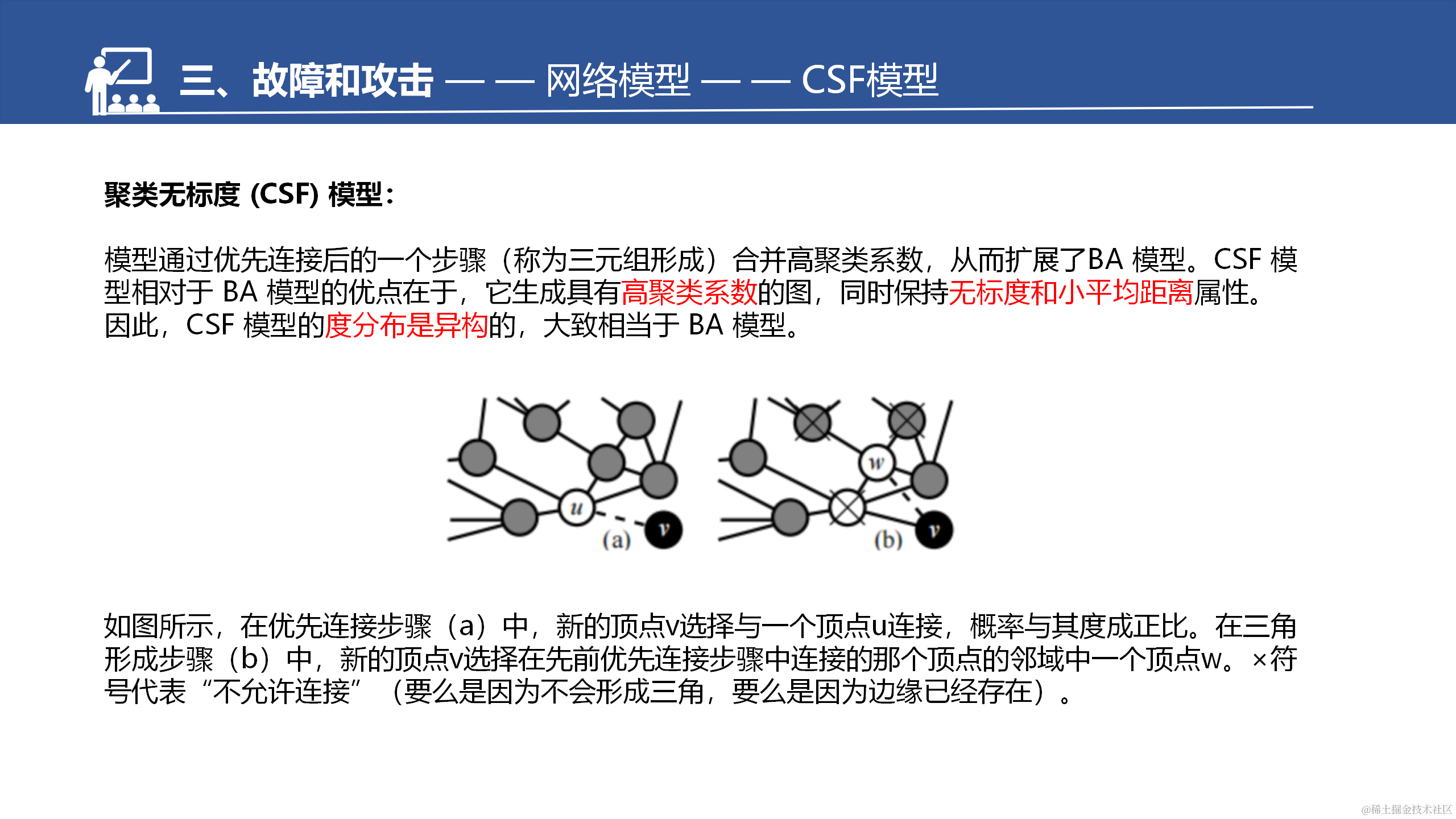



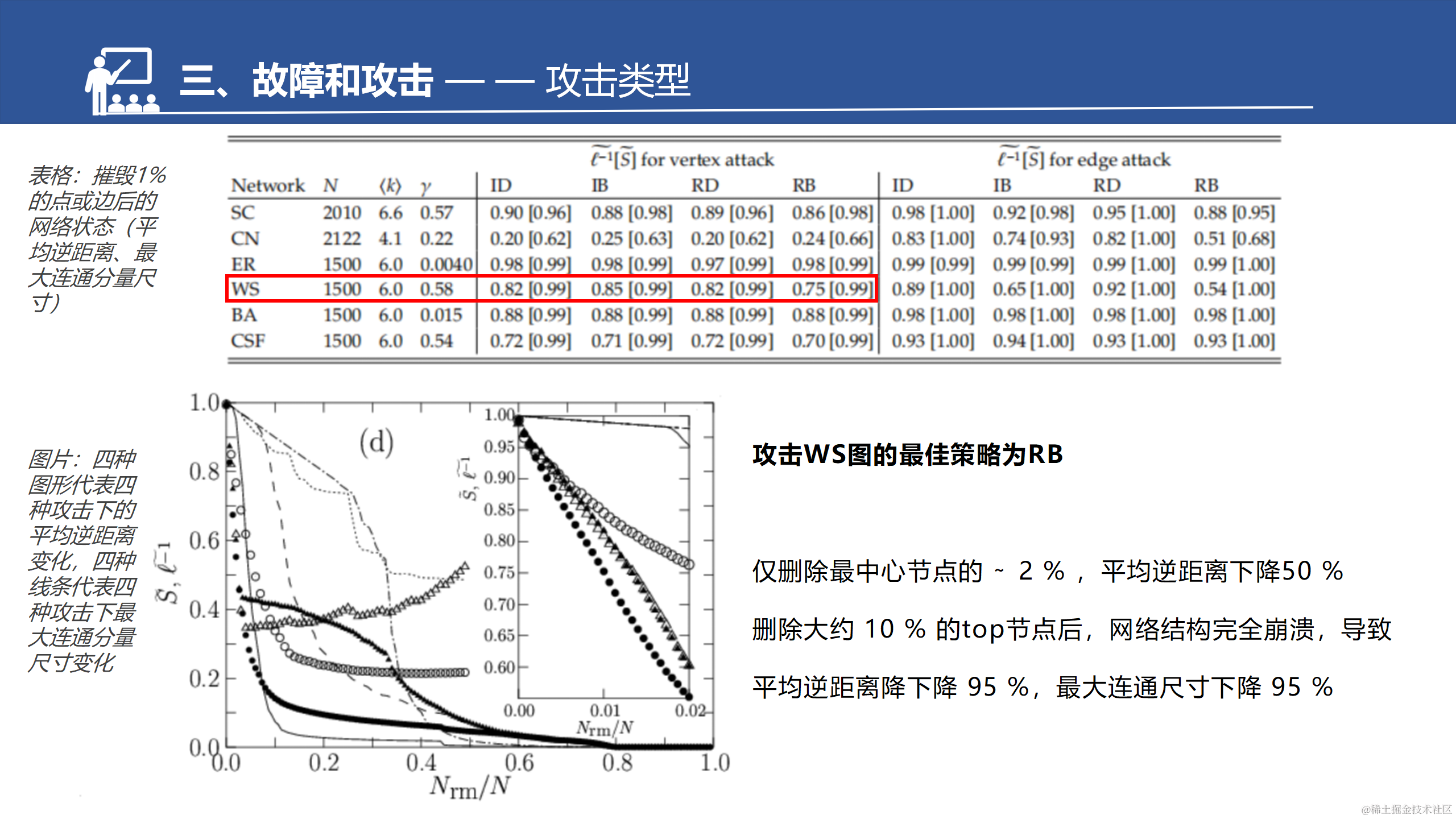

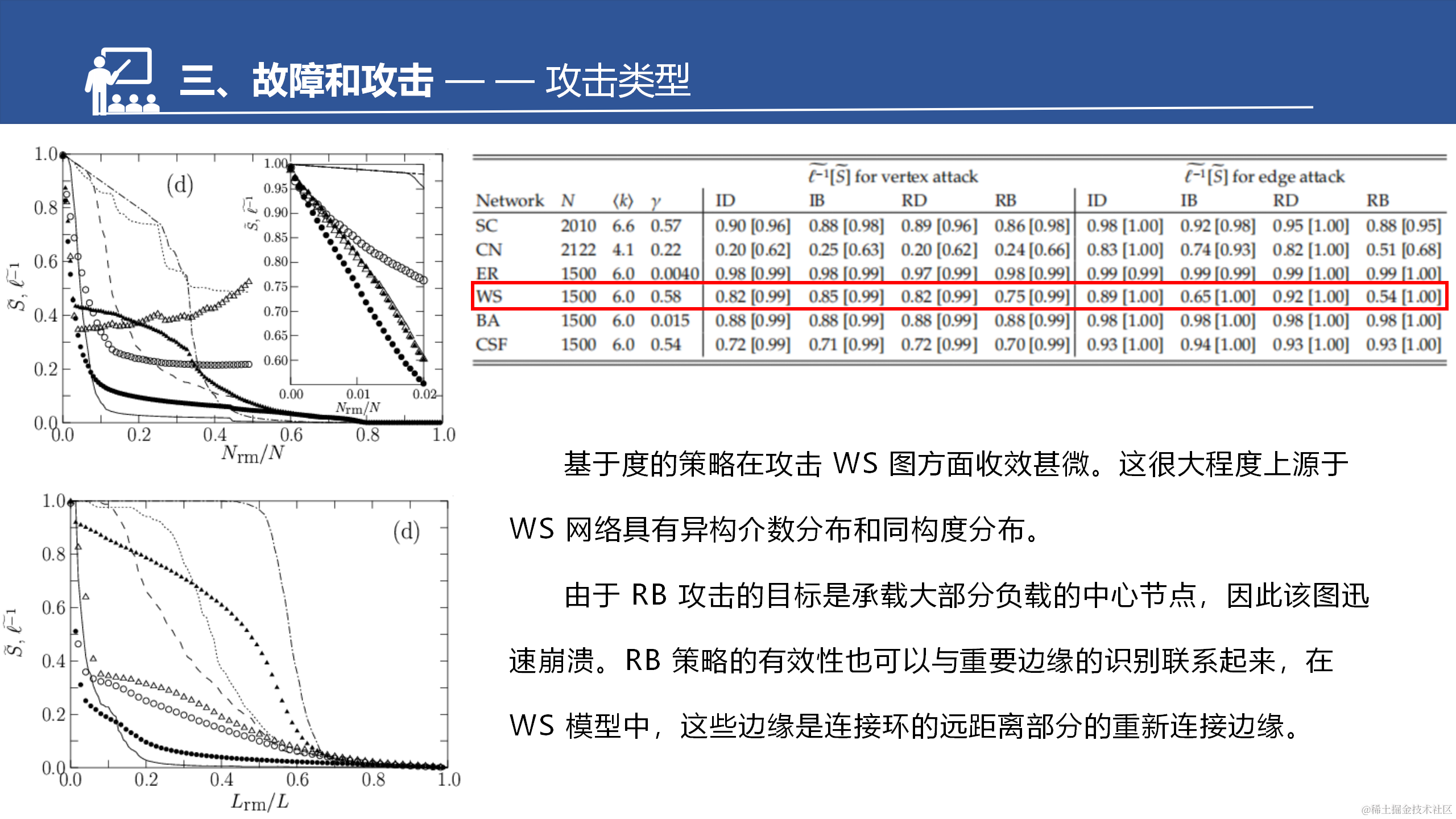
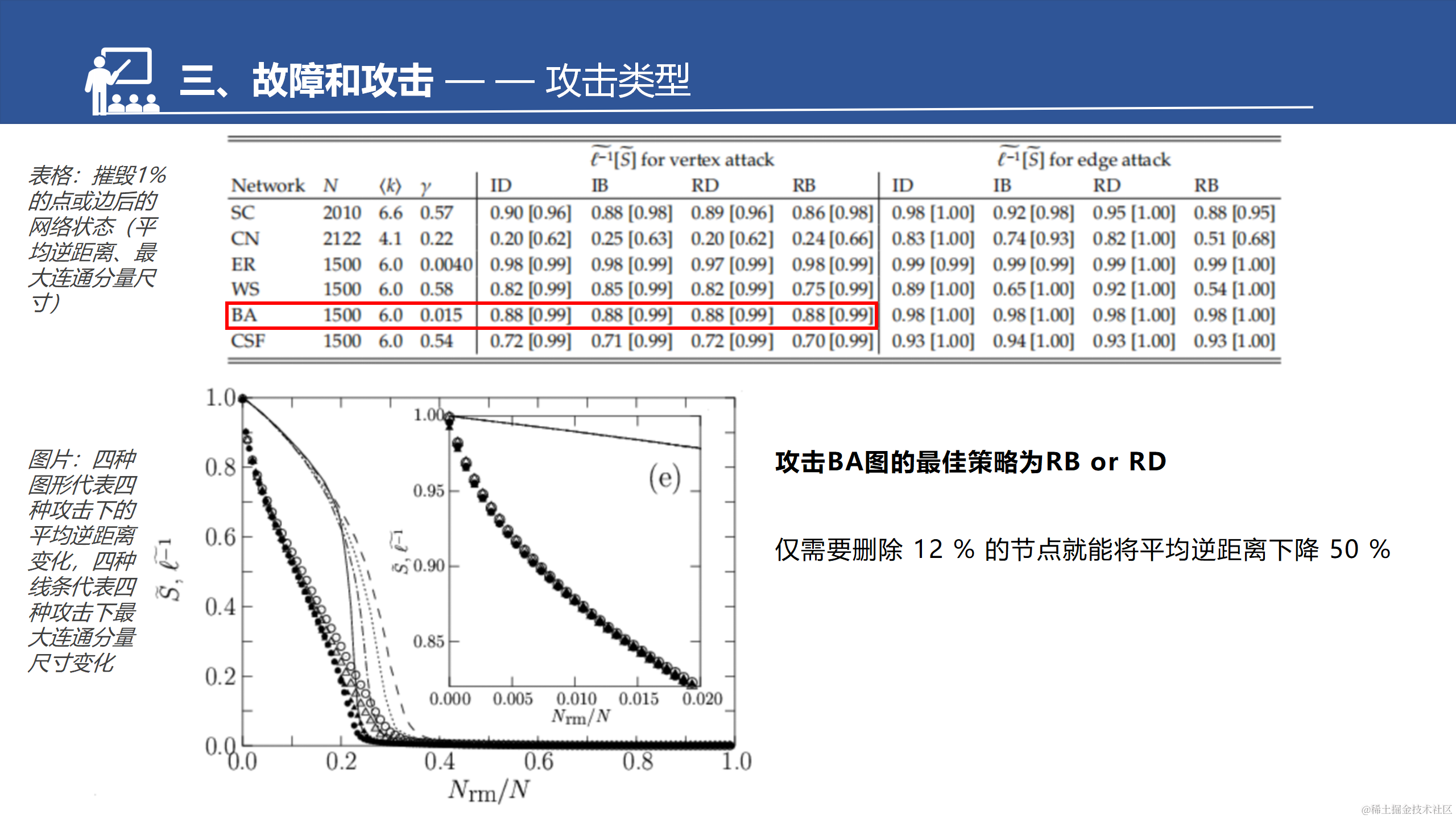
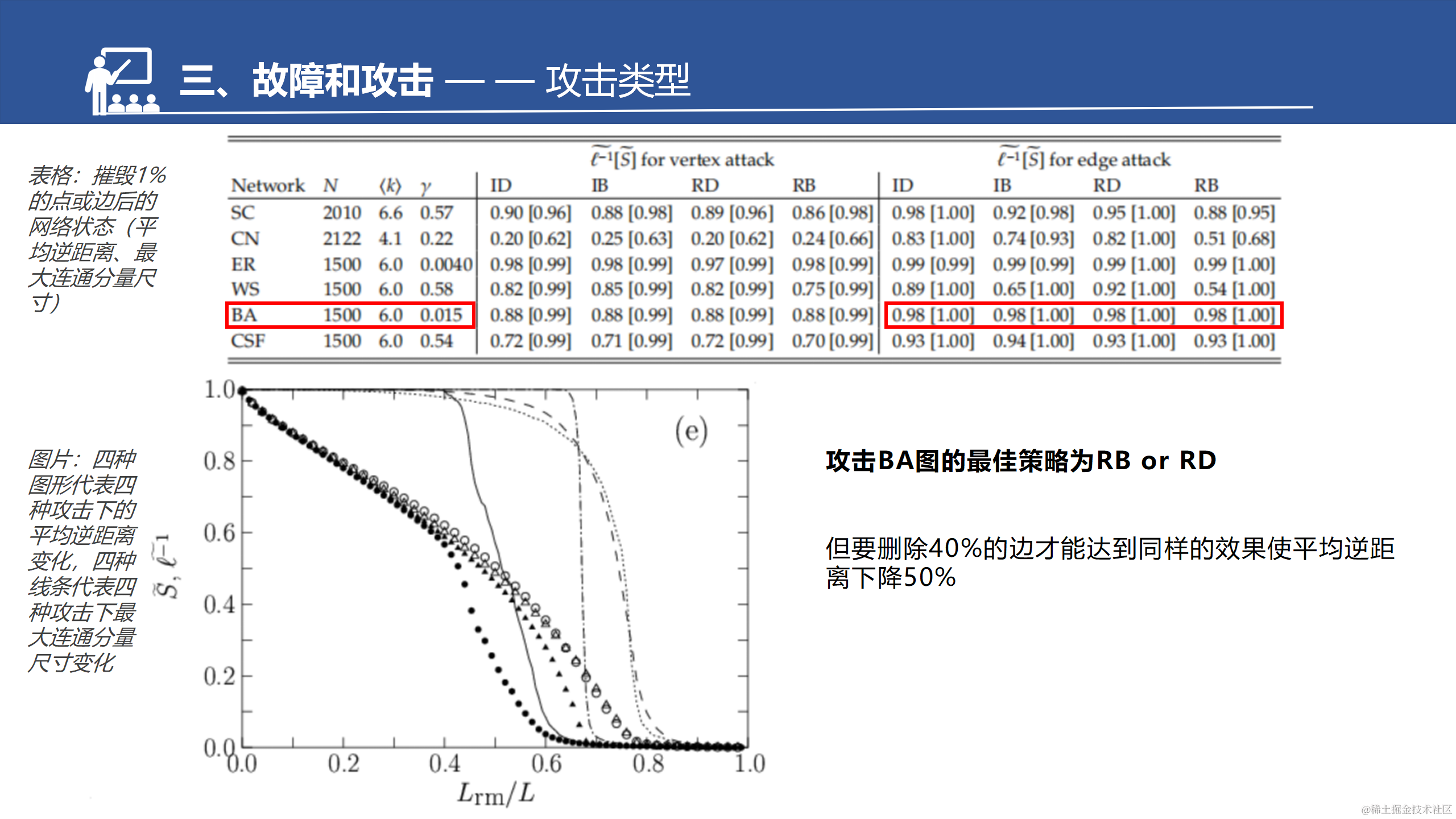
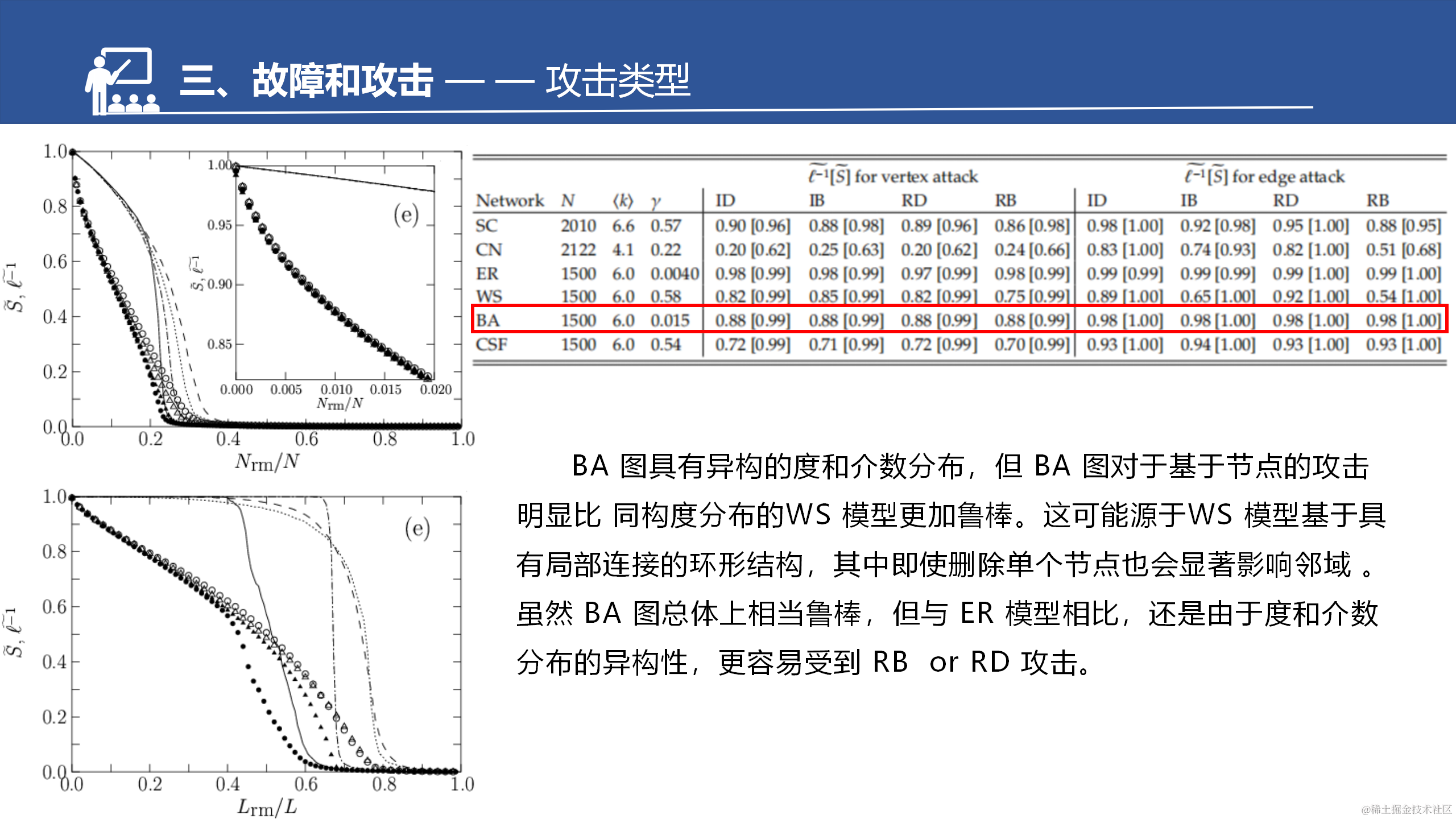
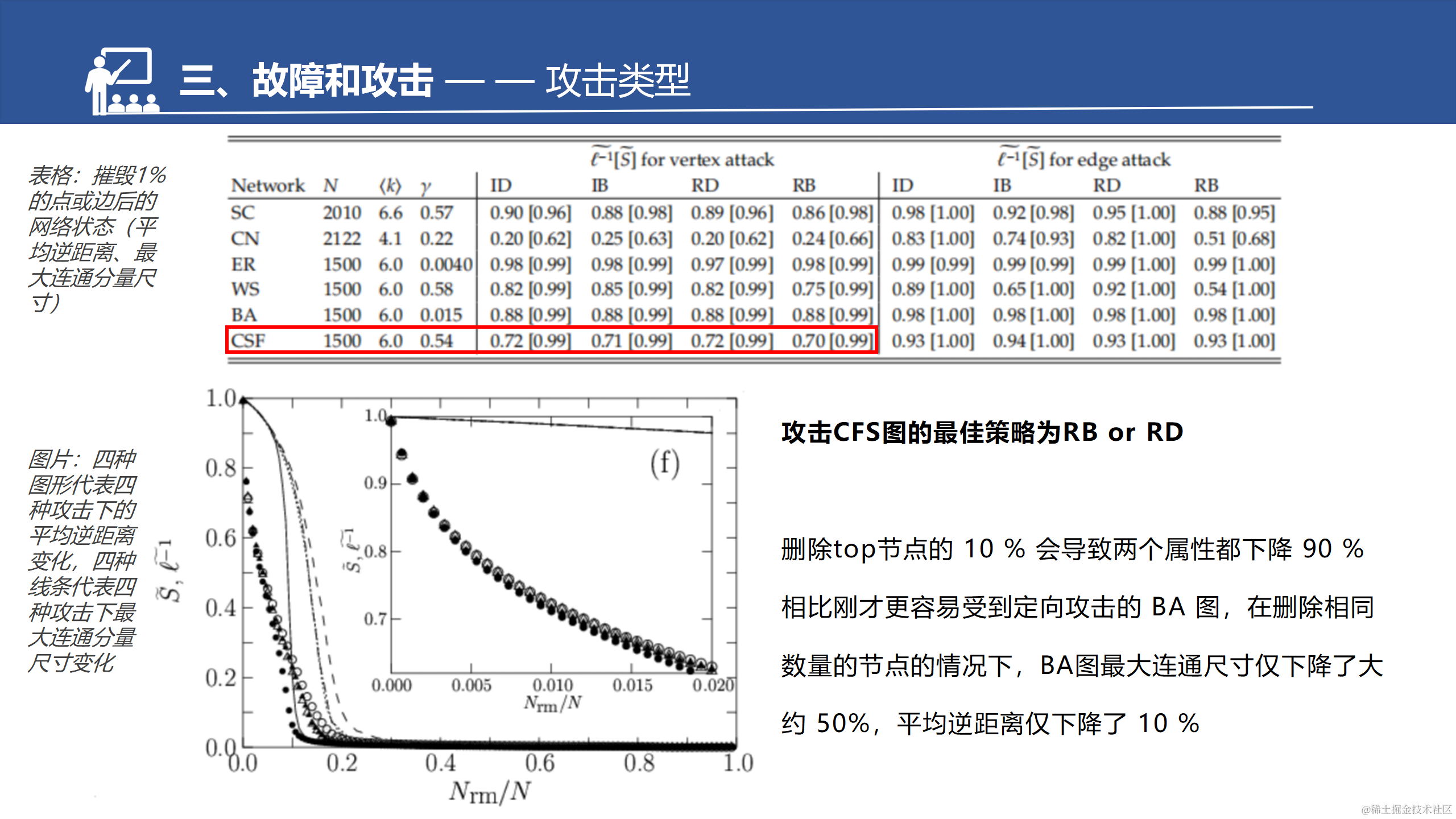
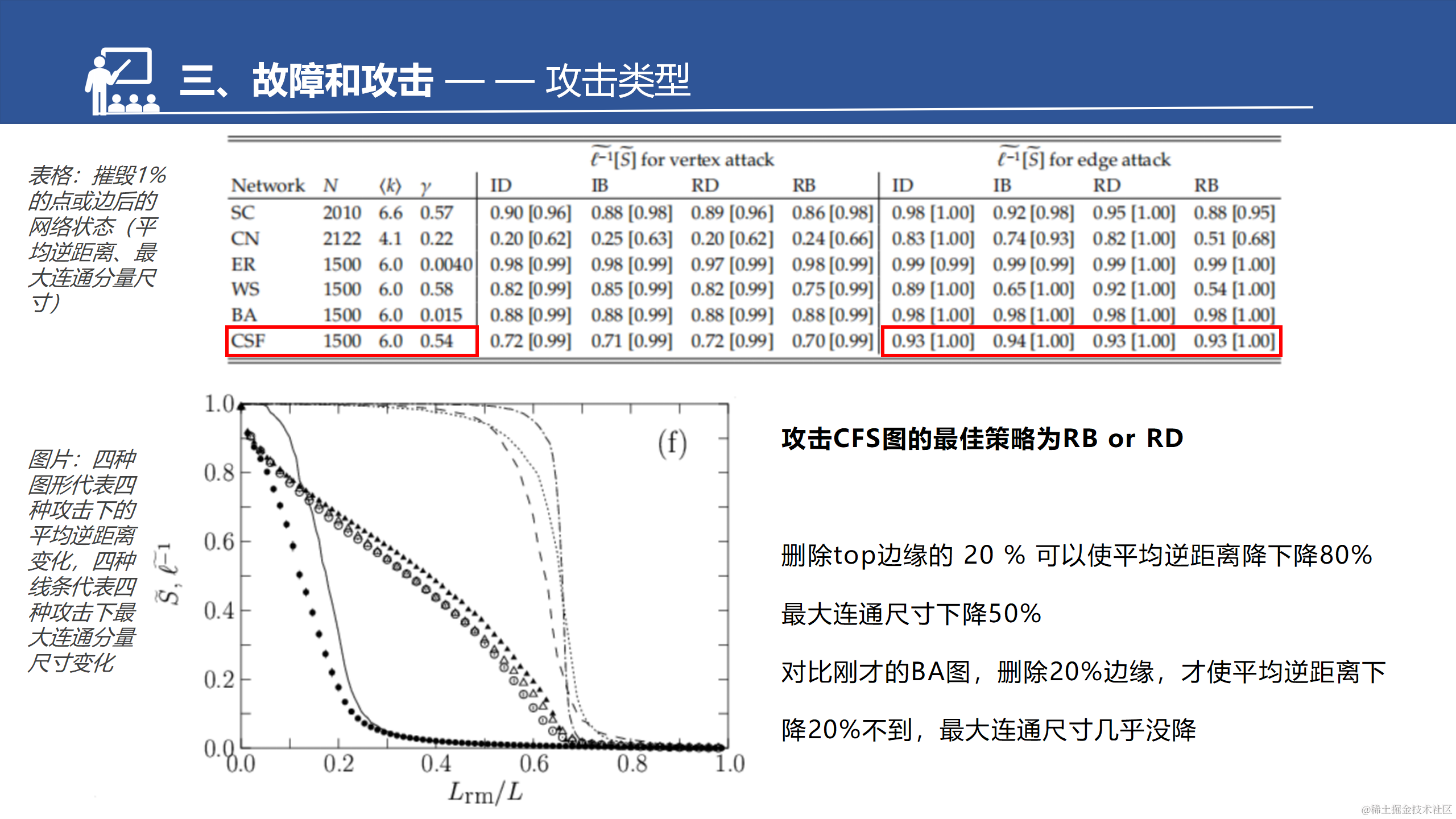
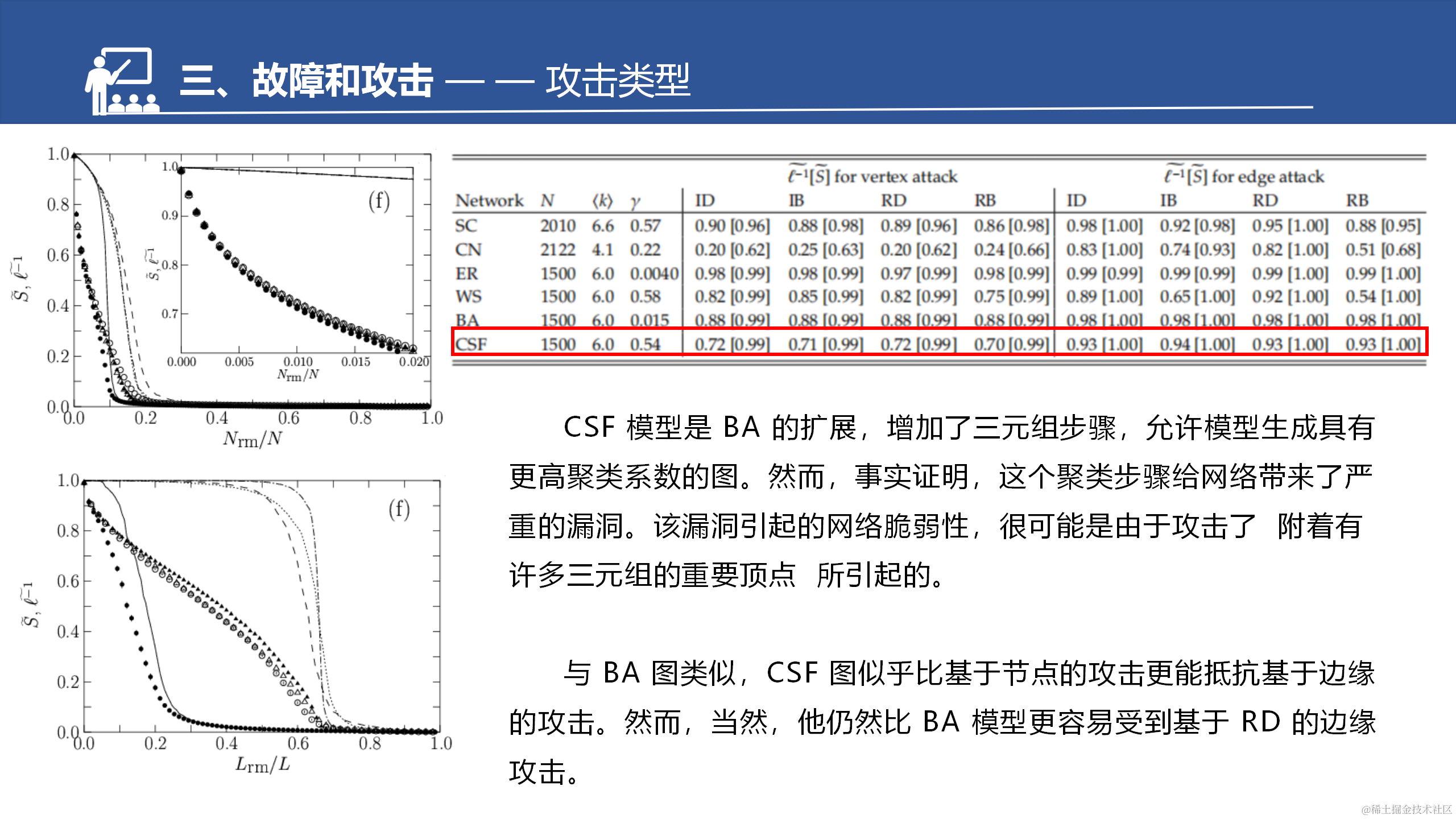
CFS是BA的拓展。增强了聚集系数,所以这边也做了一个对比
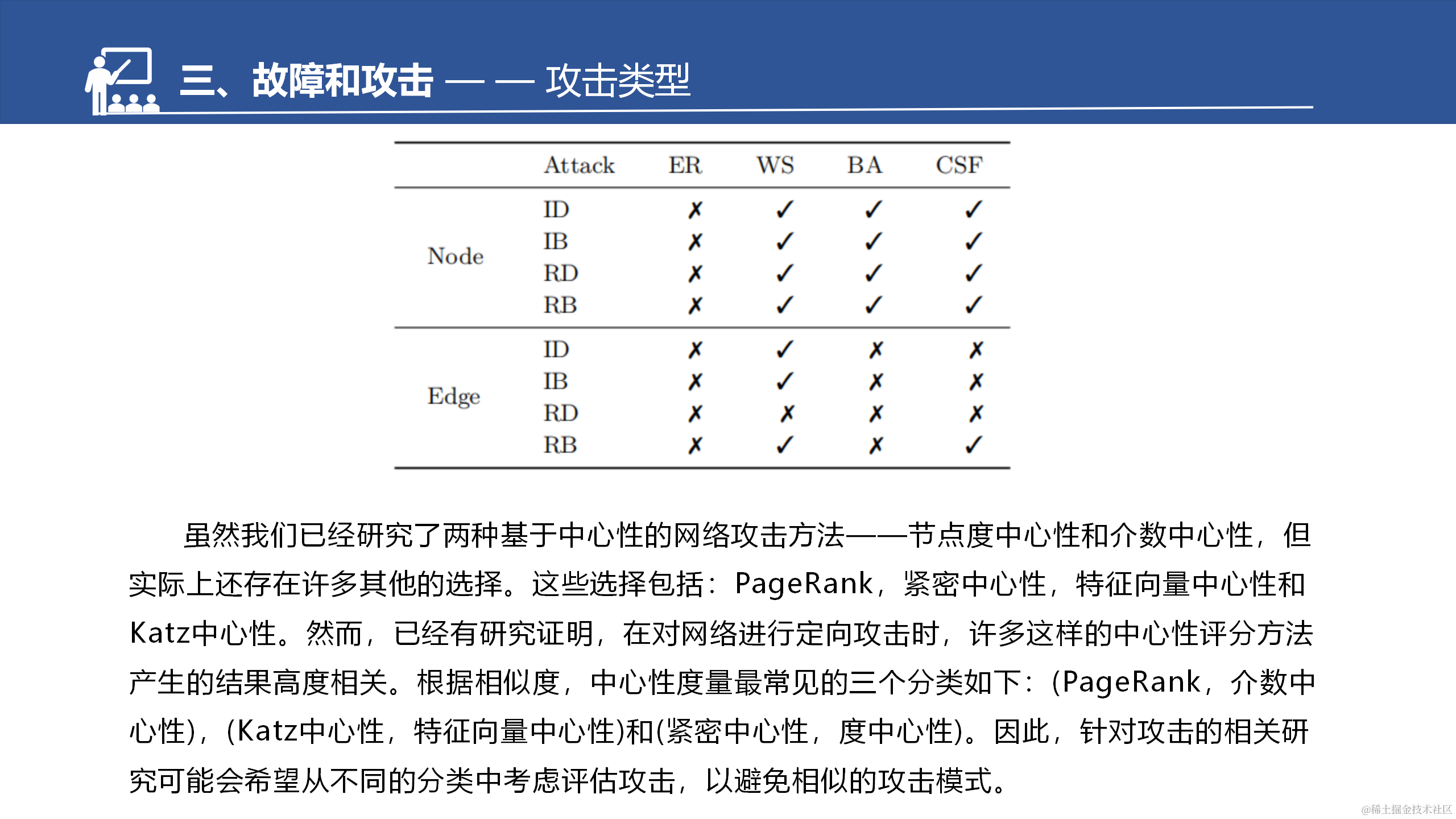
最后文章总结了有效性,并且提到了还有其他的评估指标,然后分了类,但文章只给了参考文献,没有细讲,我还没去看过。




文章只一笔带过,没有给出技术细节,只给了参考文献























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









