







对比模型CLIP(AIGC起源模型)
论文名称

什么是对比学习?
既然是对比学习,那我们首先要对对比学习有个概念。
对比学习的数据大部分为两种,一种为正样本对,一种为负样本对。模型需要做的就是分清楚输入的数据是是否为正样本对。
示例:
- 动物-牛 为正样本对
- 动物-人 为负样本对
一般对于对比学习的优化,研究者采用了很多方法,比如让正样本产生的特征向量比较接近而让负样本对产生的特征向量更远。
CLIP
既然理解了对比学习,那我们讲讲CLIP是什么吧。他的模型结构十分简单。
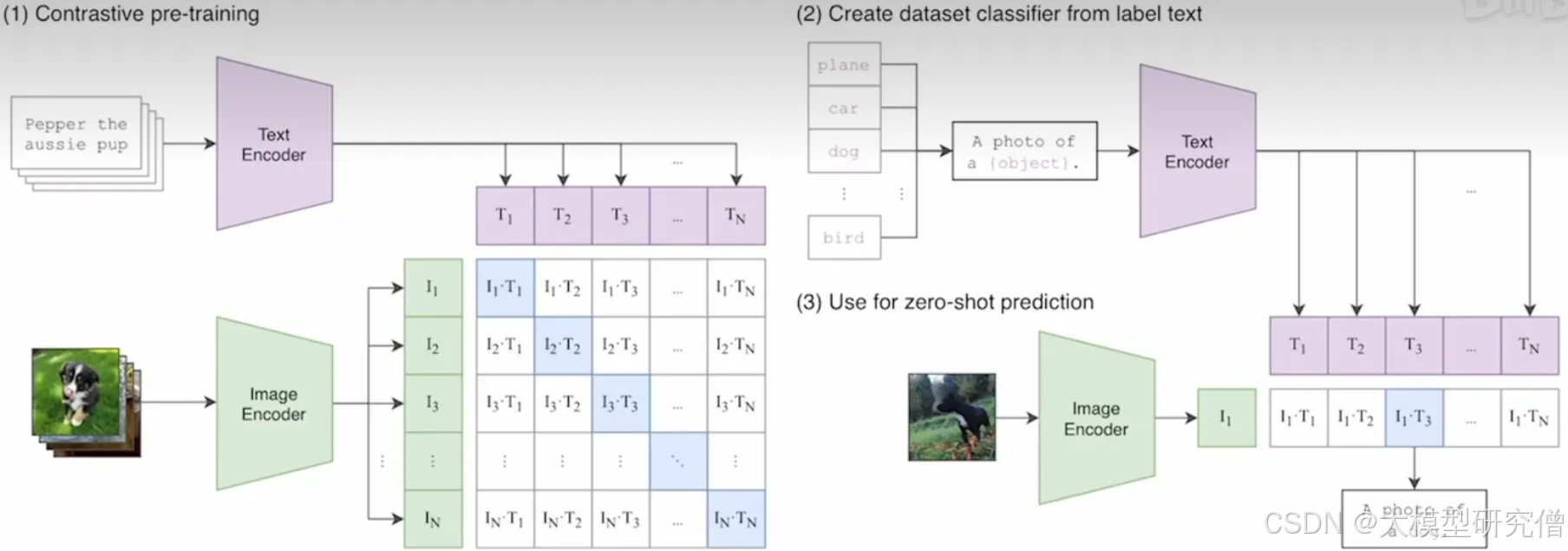
从左侧可以看到模型的输入为一对数据。
- image
- text
然后各自经过编解码网络,抽象出各自的特征,其中,沿着对角线的就是正样本 其他的为负样本,用对比学习的方式训练整个模型。
Clip如何做零样本训练?
模型只需要判断这个图像和文字是不是一对 训练也就变得简单了,相比于之前的对分类进行预测,使用对比学习方法无疑大大减少了训练量。
经过预训练,模型充其量最多也就是拿到一些特征,由于没有分类头,也没有办法分类.作者想了个很好的方案,也就是将类别组成一些特征,比如imagenet中1000个类别弄出来1000个句子,然后抽取图像特征去计算相似性,直到找到最相似的句子就把它挑出来.这种方式就让他具备了扩展性,比如不只有1000个类别还有别的一样可以弄成句子,彻底摆脱了类别标签的限制.
伪代码

首先两个输入,文本和图像的输入,通过编码器得到对应的特征
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)这一步骤的核心思想是将图像的特征向量转换到一个共同的嵌入空间,并确保这些向量的长度为1(即单位向量)。这样做的目的是为了能够使用余弦相似度来比较不同模态(如图像和文本)之间的相似性。l2_normalize(..., axis=1)则是对这些初步的嵌入表示进行L2归一化。L2归一化是指将向量除以它的L2范数(欧几里得长度),从而确保每个向量的长度为1。归一化之后,两个向量之间的夹角就等价于它们之间的余弦相似度,而余弦相似度是一个衡量方向而非大小的度量,不受向量长度的影响,因此更适合用来比较不同模态的数据。
查看伪代码,可以看到CLip又简单效果又好。
细节部分
首先两个输入,文本和图像的输入,通过编码器得到对应的特征
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)这一步骤的核心思想是将图像的特征向量转换到一个共同的嵌入空间,并确保这些向量的长度为1(即单位向量)。这样做的目的是为了能够使用余弦相似度来比较不同模态(如图像和文本)之间的相似性。
l2_normalize(..., axis=1) 则是对这些初步的嵌入表示进行L2归一化。L2归一化是指将向量除以它的L2范数(欧几里得长度),从而确保每个向量的长度为1。归一化之后,两个向量之间的夹角就等价于它们之间的余弦相似度,而余弦相似度是一个衡量方向而非大小的度量,不受向量长度的影响,因此更适合用来比较不同模态的数据。
核心思想(细节部分)
当模型训练好后,我们就有一个text encoder 和一个image encoder,图像输入模型的时候,能够通过image encoder得到一个图像特征向量,那么文本端的输入应该是什么呢?文本的输入就是你感兴趣的标签是哪些,比如飞机 汽车 狗 鸟等,比如这四个关键字就会变成四个句子(这是一个飞机的照片 这是一个汽车的照片…) 当你有了四个句子 将其通过文本编码器就能得到四个特征,然后拿着这四个特征与图像的特征计算欧式距离就可以得到相似度,然后通过一层softmax得到一个概率分布,所以句子中的物体应该就是图像中的物体了.
通过这种方式将图像与文本对建立关联
最后作者还设计了一个提示词
Prompt englneering and ensemblin这是一种在微调或者做推理的时候使用的一种方法
为什么会需要使用提示工程?
-
歧义性
只使用一个单词 词义会有歧义
-
做推理的时候进来的通常都是一个句子而非一个单词,如果不管可能抽出来的特征不是很好.
这个效果就很好了,而且尤其是你知道更多信息的时候,比如你知道一个数据集是动物的 你的提示词就可以是a **photo of a {}, a type of pet**
作者使用了80个prompt模板,加了一些修饰匹配各种情况
基于Clip拓展工作
DALL E2
Open AI提出的AIGC模型
模型的工作流程:
工作流程:
- 给定一个文本
- clip生成一个文本的特征
- prior(根据文本特征生成一个图像特征)
- 解码器生成最后的图像
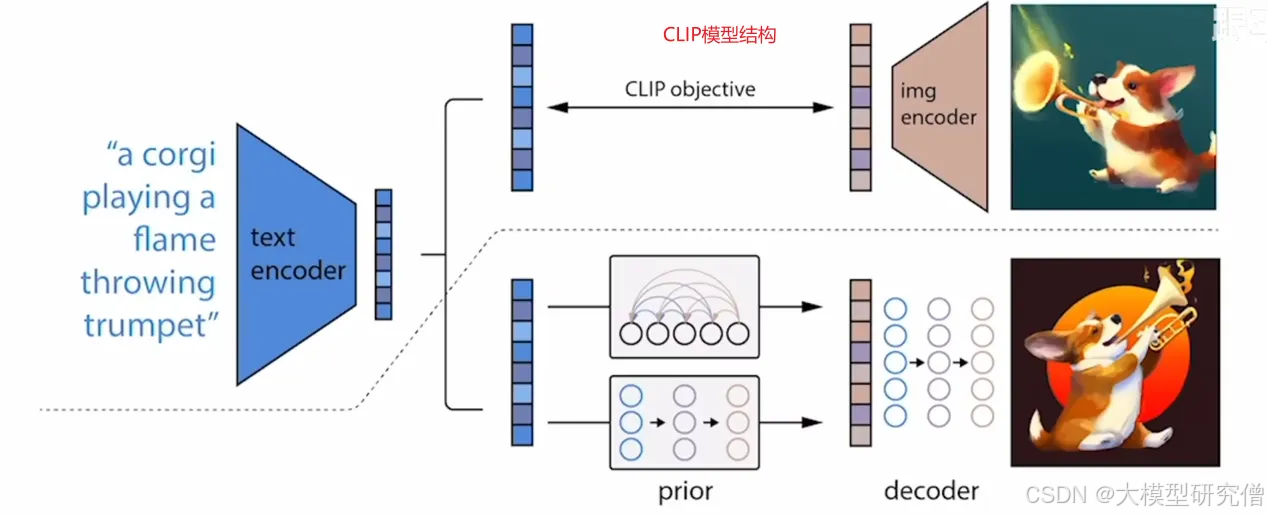
文本通过编码器生成文本向量 对应的图像通过图像编码器生成图像向量 对应的图像和文本为一个正对,其他的为负样本.模型一旦训练好就锁住了。
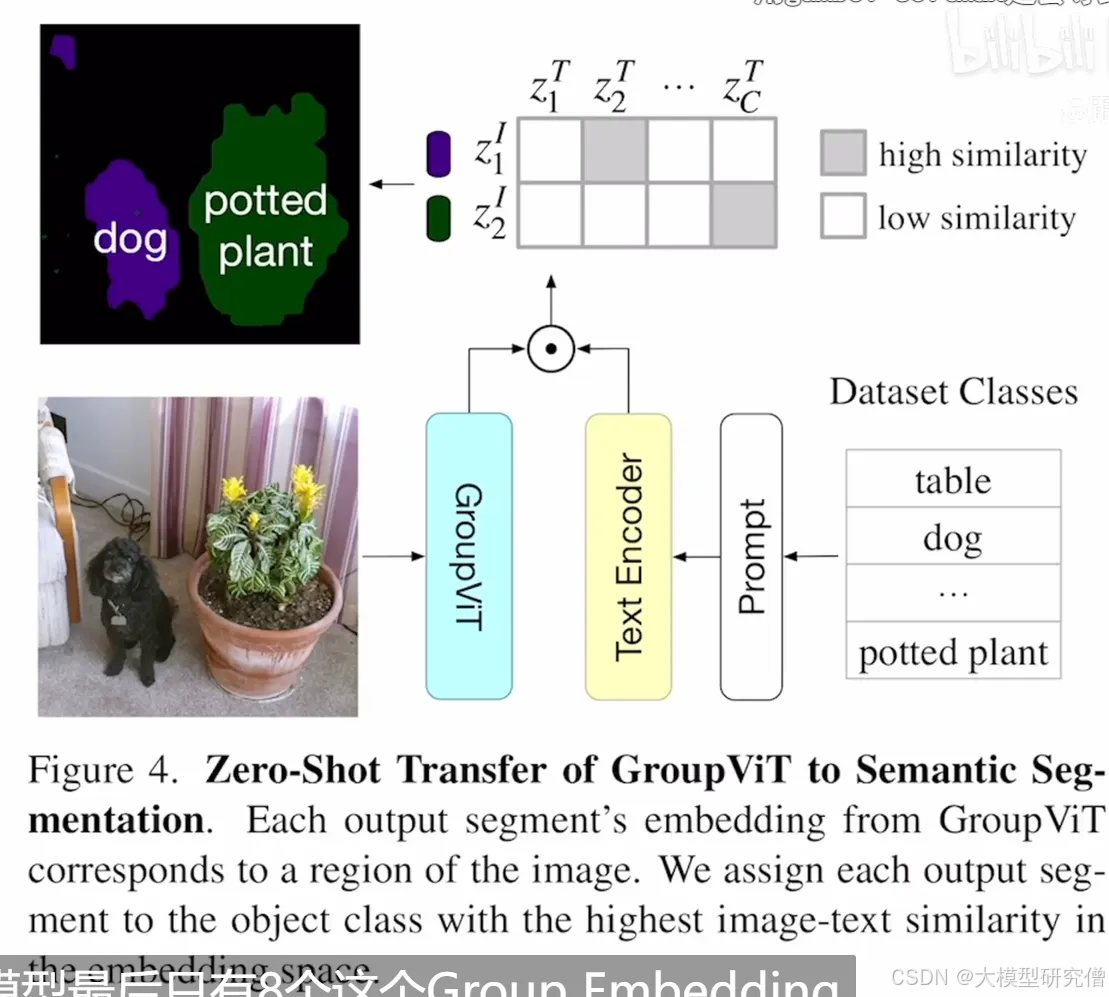
GroupVit
利用Vision Transformer和Clip,提出了可学习tokens和group block。
使用类似的自注意力机制先计算一个相似度矩阵,利用相似度矩阵去帮助原来的image token做一些矩阵中心的分配,从而将输出从196384降维到64384
作者是如何训练的?整体逻辑是:
将图像切块输入transformer中,然后给一些64乘384的可学习token 这个可学习token充当的是聚类中心的作用 也就是有64个聚类中心,希望将模型映射到64个中心 然后经过这两层之后,模型再次给出了8乘384的可学习token 也就是八个聚类中心 在经过两层,可以认为模型已经提取到了足够的信息,但是这里会存在一个问题.传统的clip是一个图片对应一个文本对,作者这里拿到的是8个,他使用了最简单的方法,使用平均池化将特征平均一下然后使用mlp,利用拿到的group特征和文本向量特征去计算损失,当然缺点也就显示出来了,图像中最多只能有8个类别.

总结
CLip就是一个利用对比学习将图像和文本对对应起来的技术,模型简单效果缺出奇的好。利用对比学习的方式训练模型,使模型具备足够优秀。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









