







交叉验证
交叉验证的概念
交叉验证是一种通过估计模型的泛化误差,从而进行模型选择的方法。基本思想是将训练集分为两大部分,一部分数据用来模型的训练,另一部分数据用于测试模型的误差,称为验证集。
K折交叉验证需要将数据集分为n等份,其中每一份都要分别作为验证集来进行训练。举个例子,将训练集分为4份,那么这四份中的每一份都要分别作为验证集进行计算,如下图

第一个模型中把第一份作为验证集,用其他三份作为训练集计算得出准确率。第二个模型把第二份作为验证集,用其他三份作为训练集计算得出准确率。以此类推。由于四个模型不同,那么得到的准确率必然不同,那么应该选取哪一个值作为最后的结果呢?取四个模型的平均值。以上就是4折交叉验证的原理。
K的取值
既然K值需要确定,那么到底应该取多少呢?
实际情况中,交叉的折数(fold)受很多因素的影响,当k较大时,经过更多次数的平均可以学习得到更符合真实数据分布份模型,bias就较小了,但是这样一来模型就更加拟合训练数据集,再去测试集上预测的时候,预测误差的期望值就变大了,从而variance就大了;反之,k较小时模型不会过度拟合训练数据,从而bias较大,但是正因为没有过度拟合训练数据,variance也较小。
所以k值的选取没有标准的答案,需根据实际情况来确定。一般要选取个位数和十位数。
为什么要用K折交叉验证
- 数据量小,单一的把数据都用来做训练模型,容易导致过拟合。(如果数据足够多,可以不使用交叉验证。)较小的k值会导致可用于建模的数据量太小,所以小数据集的交叉验证结果需要格外注意,建议选择较大的k值。
- 降低模型方差。在理想情况下,我们认为k折交叉验证可以降低模型方差,从而提高模型的泛化能力。但实际上,由于所得到的k折数据之间并非独立而是存在相关性,k折交叉验证到底能降低多少方差还不确定,同时可能会带来偏差上升。
Sklearn交叉验证API
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None, pre_dispatch='2*n_jobs', error_score=nan)
超参数搜索
超参数的概念
超参数也是一个参数,是一个未知变量,但是它不同于在训练过程中的参数,它是可以对训练得到的参数有影响的参数,需要训练者人工输入,并作出调整,以便优化训练模型的效果。
简单的说,机器学习中有很多参数是需要手动指定的(如k近邻算法中的K值),这样的值就叫超参数。
超参数搜索的概念
在调整超参数的过程中,手动过程繁杂,我们需要不断的尝试。比如在K近邻算法中,我们需要分别比较K=1,2,3,4……的效果,极大的降低了运算效率。所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
超参数搜索的原理
超参数搜索和暴力搜索很相似,在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果。
举个例子
在K近邻算法中有一个超参数即K值,假如我们给K值指定了3,5,7,设定K折交叉验证为10,在三个值中寻找最优的值。

那么超参数搜索会自动寻找K=3,5,7时最优的模型。例如K=3时,通过10折交叉验证得出一个准确率,K=5时,通过10折交叉验证得出一个准确率,K=7时,通过10折交叉验证得出一个准确率。哪一个准确率最高则认为哪一个K值为最优。超参数搜索完毕。
K近邻算法中只有一个超参数,那么如果有两个超参数呢?比如有a=[1,2,3,4],b=[5,6,7]。
这时就需要两两组合进行寻优。
Sklearn超参数搜索API
sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None,
fit_params=None, n_jobs=None, iid=’warn’, refit=True, cv=’warn’,
verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise-deprecating’, return_train_score=’warn’)
其中一些重要的参数如下:
estimator:模型估计器,例如knn。
param_grid:估计器参数,值为字典或者列表,比如knn中的参数为k,那么可以输入{“n_neighbors”:[1,3,5]}
cv:指定几折交叉验证
GridSearchCV的方法
fit():输入训练数据score():准确率best_score_():在交叉验证中验证的最好结果best_estimator_():最好的参数模型cv_results_():每次交叉验证后的测试集准确率结果和训练集准确率结果
实例
在之前的knn实战项目预测入住位置的基础上加上超参数搜索。
1、调库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
2、数据处理部分
data = pd.read_csv("train.csv")
# 处理数据
data = data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
time_value = pd.to_datetime(data['time'],unit='s')
time_value = pd.DatetimeIndex(time_value)
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
data = data.drop(['time'],axis=1)
data = data.drop(['row_id'],axis=1)
place_count = data.groupby('place_id').count()#以place_id为目标,统计每个place_id的数目
tf = place_count[place_count.x > 3] #只保存place_id数目大于3的,这里用place_count.x,place_count.y……都一样
tf = tf.reset_index()#pd.reset_index()可以把索引重置,上面的索引是place_id,重置之后就是0,1,2,3……
data = data[data['place_id'].isin(tf['place_id'])]#筛选出data中符合要求的place_id的数据
#取出特征值和目标值
y = data['place_id'] #目标值
x = data.drop(['place_id'],axis=1)
#进行数据的分割:训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.25)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)#这里直接调用transform就行,不用重新fit一次
3、超参数搜索
knn = KNeighborsClassifier()
#构造一些参数的值进行搜索,为字典格式
param = {"n_neighbors":[3,5,10]}#选择k值分别为3,5,10,在其中寻优
#超参数搜索
gc = GridSearchCV(knn,param_grid=param,cv=3)#cv一般选择10,为了结果好分析,这里选择3
gc.fit(x_train,y_train)
#预测准确率
print("在测试集上的准确率:",gc.score(x_test,y_test))
print("在交叉验证中最好的结果:",gc.best_score_)
print("选择最好的模型是:",gc.best_estimator_)
print("每个超参数每次交叉验证的结果:",gc.cv_results_)
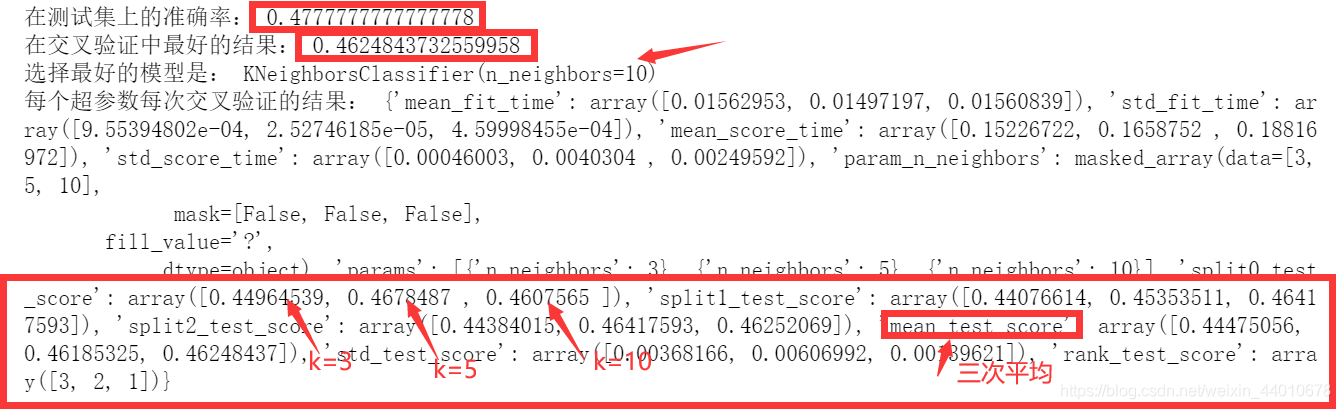
可得出最后的准确率为47.77%,交叉验证中的准确率为46.24%。














 750
750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









