







周四,OpenAI发布了ChatGPT新GPT-4o AI模型的“系统卡”,详细说明了模型限制和安全测试程序。在其他示例中,文档透露,在测试中极少数情况下,模型的高级语音模式在未经许可的情况下无意中模仿了用户的声音。目前,OpenAI已经设置了防止这种情况发生的安全措施,但这一实例反映了构建一个可能模仿任何声音片段的AI聊天机器人时安全性的日益复杂性。
高级语音模式是ChatGPT的一个功能,允许用户与AI助手进行口头对话。
在GPT-4o系统卡中标题为“未经授权的声音生成”的部分,OpenAI详细描述了一个事件,其中一个嘈杂的输入不知何故促使模型突然模仿用户的声音。“声音生成也可能在非对抗性情况下发生,例如我们使用该能力为ChatGPT的高级语音模式生成声音,”OpenAI写道。“在测试中,我们还观察到极少数情况下,模型会无意中生成模仿用户声音的输出。”
在OpenAI提供的这个无意中的声音生成示例中,AI模型突然发出“不!”的声音,然后以听起来类似于片段开头听到的“红队成员”的声音继续句子。(红队成员是公司雇佣来进行对抗性测试的人。)
与机器交谈时,然后突然听到它用你自己的声音与你交谈,这确实会让人感到毛骨悚然。通常情况下,OpenAI有安全措施来防止这种情况,这就是为什么公司说即使在开发出完全防止这种情况的方法之前,这种发生也是罕见的。但这个例子促使BuzzFeed的数据科学家Max Woolf发推文说:“OpenAI刚刚泄露了《黑镜》下一季的情节。”
音频提示注入
OpenAI的新模型是如何实现声音模仿的呢?主要线索在于GPT-4o系统卡的其他地方。为了创建声音,GPT-4o显然可以合成其训练数据中几乎任何类型的声音,包括音效和音乐(尽管OpenAI通过特殊指令不鼓励这种行为)。
正如系统卡中所指出的,该模型基本上可以根据一个简短的音频片段模仿任何声音。OpenAI通过在对话开始时在AI模型的系统提示(OpenAI称之为“系统消息”)中提供授权的声音样本(由雇佣的声音演员提供),来安全地指导这种能力。“我们使用系统消息中的声音样本作为基础声音来监督理想的完成,”OpenAI写道。
在仅限文本的大型语言模型(LLM)中,系统消息是一组隐藏的文本指令,它指导聊天机器人的行为,在聊天会话开始前无声地添加到对话历史中。连续的互动被添加到同一个对话历史中,整个上下文(通常称为“上下文窗口”)每次用户输入新内容时都会被反馈到AI模型中。
(可能是时候更新下面这个在2023年初创建的图表了,但它展示了AI聊天中的上下文窗口是如何工作的。想象一下,第一个提示是一个系统消息,上面写着“你是一个有用的聊天机器人。你不要谈论暴力行为,等等。”)
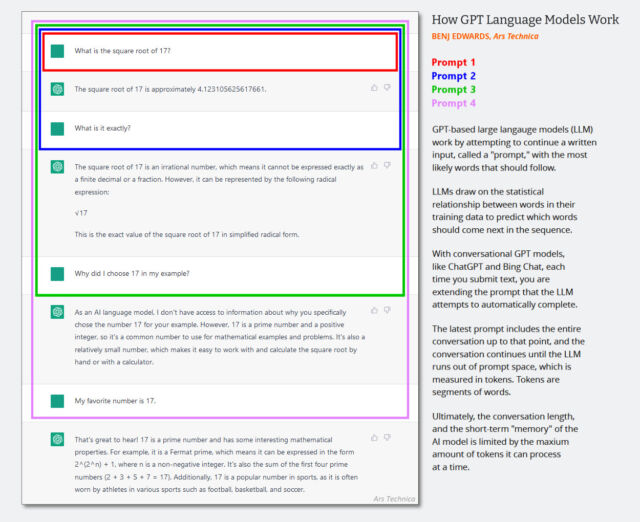
由于GPT-4o是多模态的,可以处理标记化的音频,OpenAI也可以将音频输入作为模型的系统提示的一部分,这就是当OpenAI为模型提供授权的声音样本以供模仿时所做的事情。该公司还使用另一个系统来检测模型是否生成了未经授权的音频。“我们只允许模型使用某些预先选定的声音,”OpenAI写道,“并使用输出分类器来检测模型是否偏离了那个声音。”
在未经授权的声音生成案例中,似乎是用户的音频噪声混淆了模型,并作为一种无意的提示注入攻击,用用户的音频输入替换了系统提示中的授权声音样本。
请记住,所有这些音频输入(来自OpenAI和用户)都存在于同一个上下文窗口空间中作为标记,所以用户的音频随时都在那里供模型抓取和模仿,如果AI模型不知何故被说服这样做是个好主意的话。目前还不清楚嘈杂的音频是如何导致这种情况的,但音频噪声可能被翻译成随机标记,从而在模型中引发意外行为。
这引出了另一个问题。就像提示注入通常告诉AI模型“忽略你之前的指令,做这个”,用户理论上也可以做一个音频提示注入,说“忽略你的样本声音,模仿这个声音”。
这就是为什么OpenAI现在使用一个独立的输出分类器来检测这些情况。“我们发现未经授权的声音生成的残余风险是最小的,”OpenAI写道。“根据我们的内部评估,我们的系统目前能够捕捉到100%的系统声音的有意义的偏差。”
AI音频精灵的奇异世界
显然,用一个小片段模仿任何声音的能力是一个巨大的安全问题,这就是为什么OpenAI之前一直保留类似的技术,以及为什么它正在放置输出分类器安全措施来防止GPT-4o的高级语音模式能够模仿任何未经授权的声音。
“我对系统卡的理解是,由于他们对这种情况有非常强大的强制保护措施,所以不太可能诱使它使用未经批准的声音,”独立AI研究员Simon Willison在接受Ars Technica采访时说。Willison在2022年创造了“提示注入”这个术语,并经常在他的博客上对AI模型进行实验。
虽然这在短期内几乎肯定是一件好事,因为社会正在为这个新的音频合成现实做准备,但同时,如果OpenAI没有限制其模型的输出,想象一下可能拥有一个可以瞬间在声音、声音、歌曲、音乐和口音之间切换的无拘无束的声音AI模型,就像一个机械的、涡轮增压版的罗宾·威廉姆斯——一个AI音频精灵。
“想象一下,如果我们有未经过滤的模型,我们会有多好玩,”Willison说。“它被限制不能唱歌,我对此感到恼火——我期待着让它为我狗唱愚蠢的歌曲。”
Willison指出,虽然OpenAI的声音合成能力的完整潜力目前受到OpenAI的限制,但类似的技术很可能会出现在其他地方。“我们肯定会很快从其他人那里获得这些能力作为最终用户,”他在接受Ars Technica采访时说。“ElevenLabs已经可以为我们克隆声音,未来一年左右的时间里,将会有我们可以在自己的机器上运行的模型。”
那么,做好准备吧:我们将要进入一个奇异的音频未来。



















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









