







持续学习&持续更新中…
守破离
【周阳-Redis】【08】Redis的Master-Slave
Redis的Master-Slave
- 行话:也就是我们所说的主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制
- Master以写为主,Slave以读为主
- 可以实现的主要功能:
- 读写分离
- 容灾恢复
单机多Redis实例搭建环境
-
拷贝多个redis.conf文件:
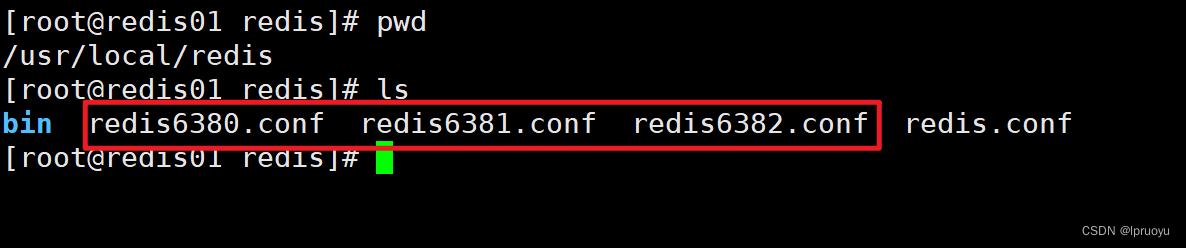
-
每个配置文件都开启
daemonize yes -
修改每个配置文件的pid文件名:
pidfile /var/run/redis6380.pid、pidfile /var/run/redis6381.pid、pidfile /var/run/redis6382.pid -
修改每个配置文件的端口:
port 6380、port 6381、port 6382 -
修改每个配置文件的log日志文件名:
logfile "/var/tmp/redis6380.log"、logfile "/var/tmp/redis6381.log"、logfile "/var/tmp/redis6382.log" -
修改每个配置文件的dump.rdb名字:
dbfilename dump6380.rdb、dbfilename dump6381.rdb、dbfilename dump6382.rdb -
根据配置文件启动redis服务、根据端口号启动redis-cli
-
启动好后,在每个redis-cli下输入
info replication会发现目前每个redis实例的角色(role)都是role:master,每个redis实例的从节点数量都为0connected_slaves:0;也就是说,每个redis服务启动后默认都是Master(主机)
怎么玩
- 配从(库)不配主(库)
- 从库配置命令:
slaveof master主机 master端口
常用三招
一主多仆
-
init:

-
一个Master两个Slave:(从机使用SLAVEOF命令)
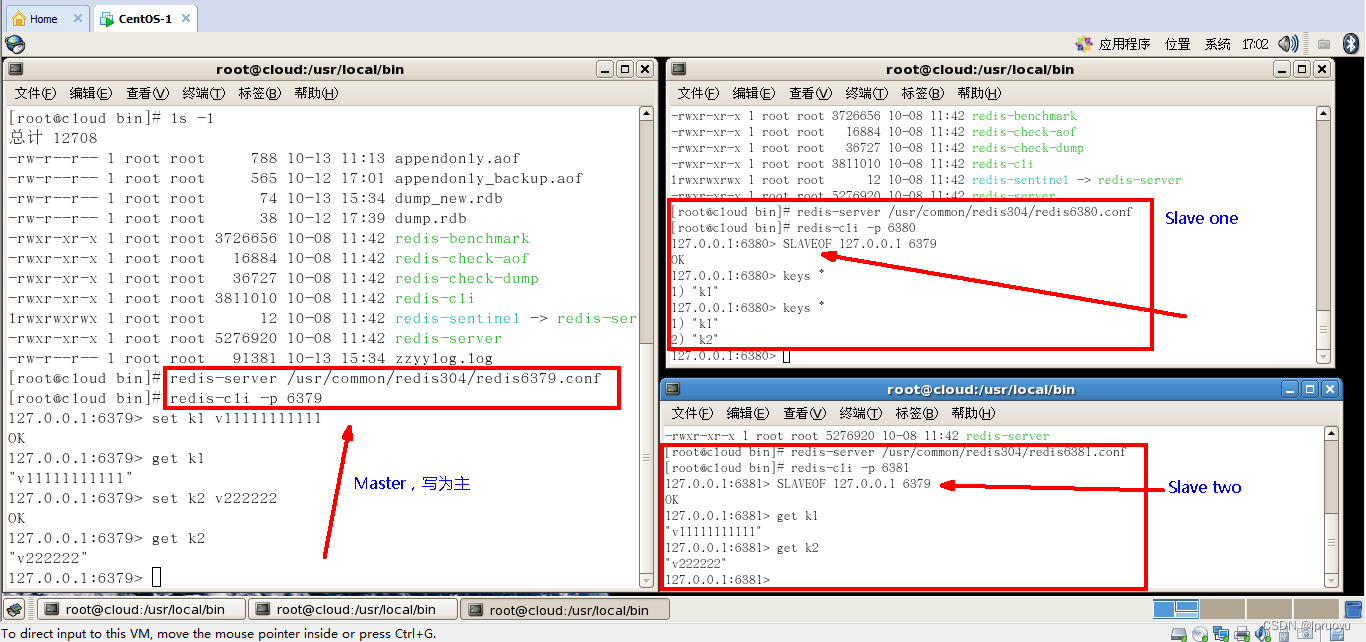
-
使用
info replication查看master-slave信息:
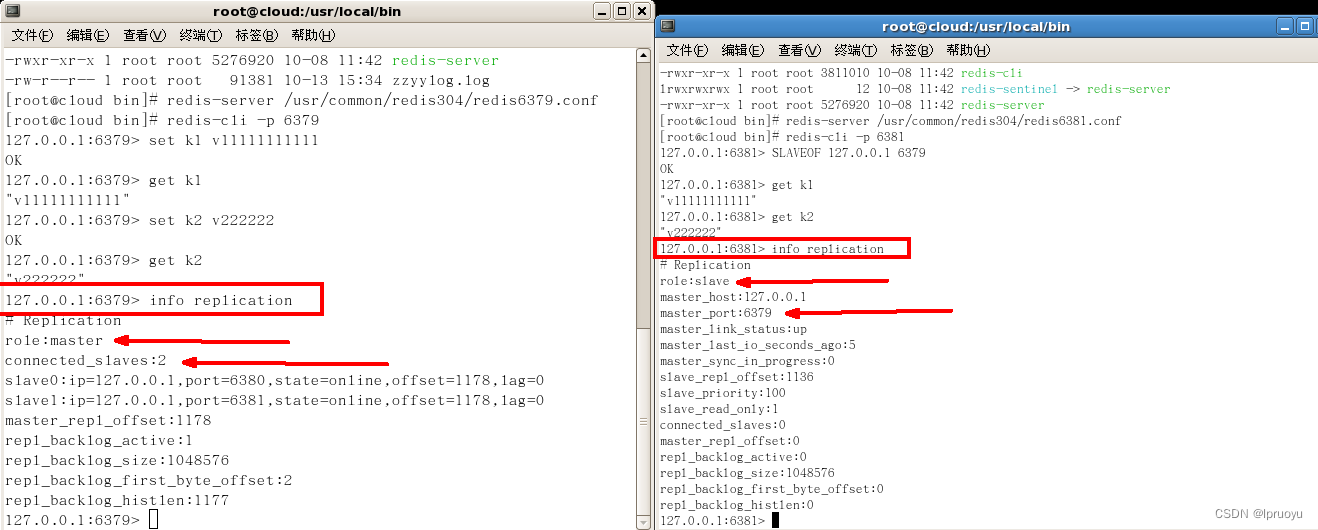
-
日志
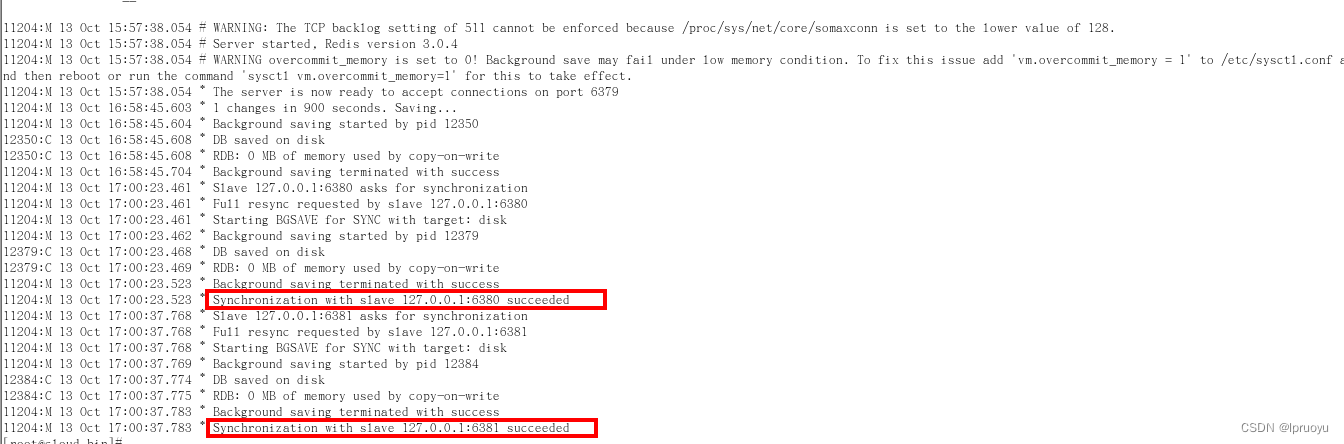
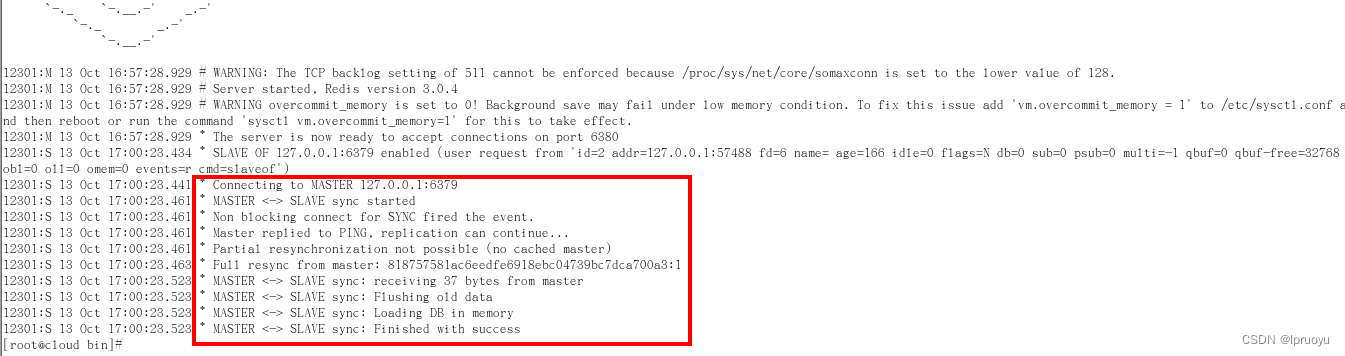
-
演示
1 切入点问题?slave1、slave2是从头开始复制还是从切入点开始复制?【从头开始复制】 比如从k4进来,那之前的123是否也可以复制【可以】 2 从机是否可以写? 【不可以,因为从机是read-only的,redis的Master-Slave保证了读写分离】 set可否?【set属于写命令,因此不行】 3 主机shutdown后情况如何?从机是上位还是原地待命 【从机保持状态不变,还是从机,原地待命等待主机再次上线】 4 主机又回来了后,主机新增记录,从机还能否顺利复制? 【可以,因为主机再次上线后,从机会再次自动连接作为主机的slave】 5 其中一台从机down后情况如何?依照原有它能跟上大部队吗? 【从机down掉后对于其他从机没有影响,主机的slaves数量-1】 【redis的服务上线默认都是master,因此,当从机再次上线,如果还要作为之前主机的从机,就需要使用slaveof命令再次连接主机】 -
小总结:
- 一主多仆模式下,即使主机死了,仆机们也不会有其它操作,仍然保存从机状态,只不过master_link_status会 从up变为down;当主机再次上线,那么从机们就会恢复与主机的连接,master_link_status会从down变为up
- 如果从机挂了,也就是与主机断开之后,如果从机再次上线,需要重新使用SLAVEOF命令连接主机,因为每一个Redis服务启动后都默认是master,除非你配置进redis.conf文件
反客为主
- 假设有三台机器:A、B、C,其中A是master,B、C是slave
- 对B机器使用
SLAVEOF no one命令就可以让B从slave重新变为master - 然后对机器A、C分别使用
slaveof B的ip B的端口命令,让A、C作为B的slaves - B从slave变为master,这就叫做反客为主
薪火相传(去中心化)
-
上一个Slave可以是下一个Slave的Master,Slave同样可以接收其他Slaves的连接和同步请求,那么该Slave作为了链条中下一个Slave的Master
-
可以有效减轻Master的写压力
-
中途变更转向:会清除之前的数据,重新建立拷贝最新的
-
127.0.0.1:6380:
[root@redis01 bin]# ./redis-server ../redis6380.conf [root@redis01 bin]# ./redis-cli -p 6380 127.0.0.1:6380> info replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6381,state=online,offset=42,lag=0 127.0.0.1:6380> set name lp OK -
127.0.0.1:6381:
[root@redis01 bin]# ./redis-server ../redis6381.conf [root@redis01 bin]# ./redis-cli -p 6381 127.0.0.1:6381> slaveof 127.0.0.1 6380 OK 127.0.0.1:6381> info replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up connected_slaves:1 127.0.0.1:6381> get name "lp" -
127.0.0.1:6382:
[root@redis01 bin]# ./redis-server ../redis6382.conf [root@redis01 bin]# ./redis-cli -p 6382 127.0.0.1:6382> slaveof 127.0.0.1 6381 OK 127.0.0.1:6382> info replication role:slave master_host:127.0.0.1 master_port:6381 master_link_status:up connected_slaves:0 127.0.0.1:6382> get name "lp"
哨兵模式(sentinel)
是什么
-
哨兵模式原理就是:监控(巡逻放哨);
-
一句话:哨兵模式就是“反客为主”的自动版(当主机挂了,自动在剩下的从机中以投票的方式选举出一个新主机)
-
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
怎么玩
-
启动Redis集群为一主二从模式:6379带着6380、6381
-
自定义的目录下新建sentinel.conf文件,名字绝不能错
-
在sentinel.conf文件中添加要监控的Redis服务节点:(一个sentinel.conf下能同时监控多个Master)
# 最后一个数字1,表示让主机挂掉后,salves投票看让谁接替成为主机,得票数多少后成为主机 sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1 # 可以监控多个Redis服务节点 # sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6381 1 # ... -
启动哨兵:redis-sentinel /…/sentinel.conf(
[root@redis01 ~]# /usr/local/redis/bin/redis-sentinel /usr/local/redis/sentinel.conf) -
如果被哨兵监控的master挂了那么其它slave就会投票重新选举一个新主机
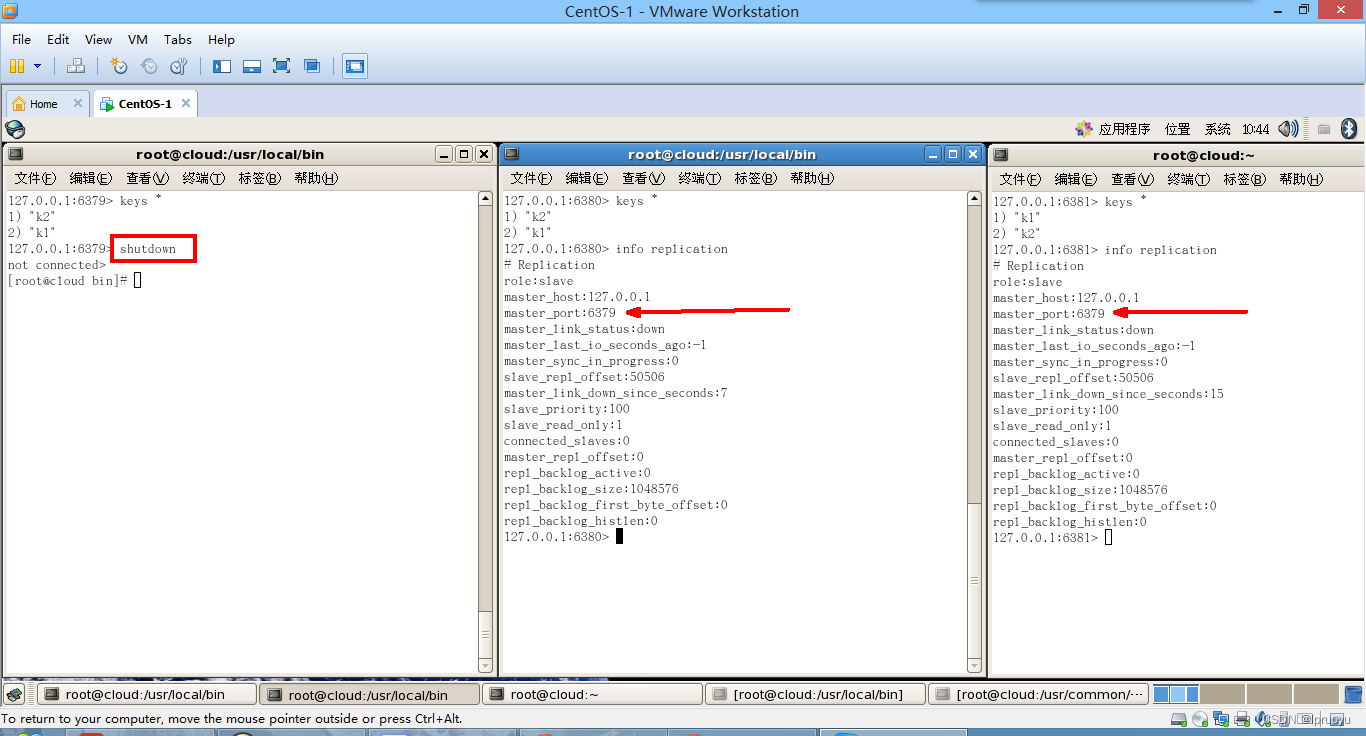
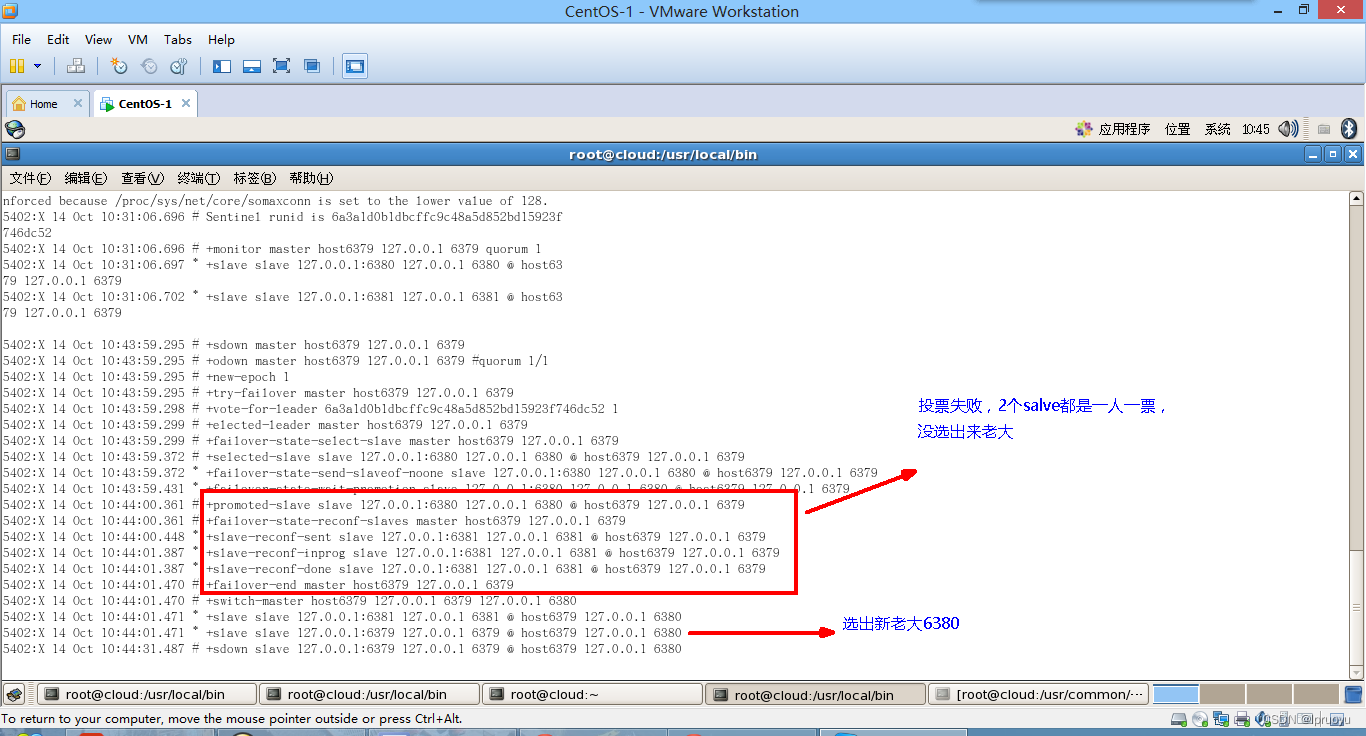
-
如果之前的主机重新上线,那么哨兵监控到它上线就会将其设为新选举出来的master的slave
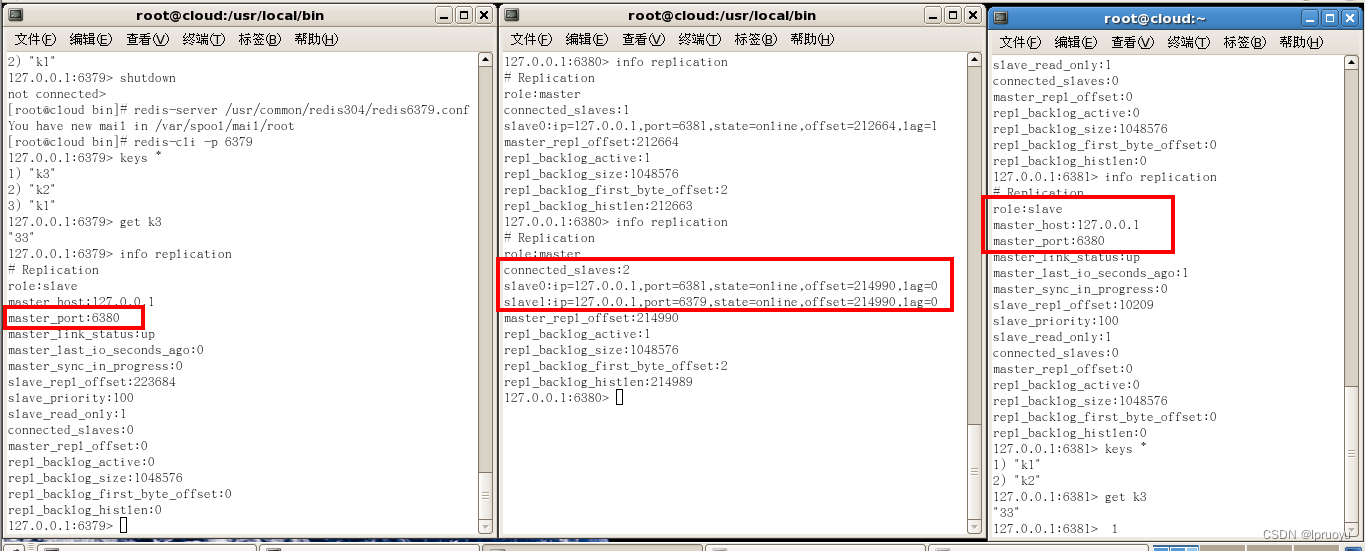
主从复制原理
- Slave启动成功连接到master后会发送一个sync命令
- Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
- 首次连接是全量复制,之后就是增量复制,但是只要是重新连接master,那么就是一次性完全同步(全量复制)将被自动执行
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步。
主从复制缺点
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟
- 当系统很繁忙的时候,延迟问题会更加严重
- Slave机器数量的增加也会使这个问题更加严重。
参考
尚硅谷-周阳: 尚硅谷超经典Redis教程.
本文完,感谢您的关注支持!















 555
555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









