







分治法
文章目录
分治法的基本思想
- 将规模为N的问题分解为k个规模较小的子问题,使这些子问题相互独立可分别求解,再将k个子问题的解合并成原问题的解.如子问题的规模仍很大,则反复分解直到问题小到可直接求解为止。
- 在分治法中,子问题的解法通常与原问题相同,自然导致递归过程。
合并排序
问题: 将n个元素排成非递减顺序。
算法思路:若n为1,算法终止;否则,将n个待排元素分割成k(k=2)个大致相等子集合A、B,对每一个子集合分别递归排序,再将排好序的子集归并为一个集合。
合并排序的递归算法
算法 MergeSort(A[0..n-1] )
// 输入:未排序序列A[0..n-1]
// 输出:已排序序列A[0..n-1]
if n > 1
copy A[0..n/2-1] to B[0..n/2-1]
copy A[n/2..n-1] to C[0..n/2-1]
MergeSort( B )
MergeSort( C )
Merge( B,C,A )
其中,Merge(B,C,A)是将有序数组B、C合并为有序数组A的算法。
算法 Merge(B[0..p-1],C[0..q-1],A[0..p+q-1])
i=0,j=0,k=0;
while i<p and j<q do
if B[i]≤C[j]
A[k]=B[i], i=i+1
else
A[k]=C[j], j=j+1
k=k+1
if i=p
copy C[j..q-1] to A[k..p+q-1]
else
copy B[i..p-1] to A[k..p+q-1]
合并排序举例
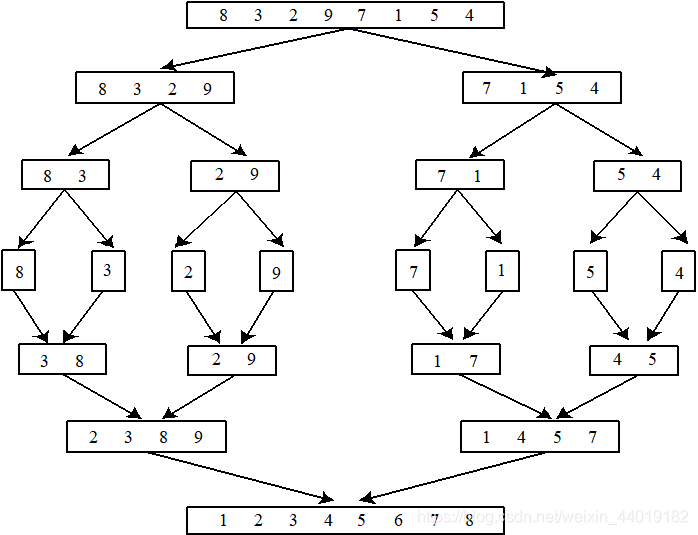
注:合并 [2,3,8,9] 与[1,4,5,7] 的过程:
从两个序列的头部开始合并:2与1比较,1被移到结果序列;2与4比较,2被移入结果序列;4与3比较,3被放入结果序列;4和8比较,4被放入结果序列, 8和5比较…,
合并排序的效率分析
设n=2k, 则关键字比较次数的递推关系式为:
C(n)=2C(n/2)+Cmerge(n)
C(1)=0
在最坏情况下,归并排序的效率Cmerge(n)=n-1,
于是,在最坏情况下
C (n)=2C(n/2)+n-1
解得
C(n)=nlog2n-n+1∈Θ(nlog2n)
快速排序
算法思路: 对于输入A[0… n-1],按以下三个步骤进行排序:
(1)分区:取A中的一个元素为支点(pivot) 将A[0…n-1]划分成3段:
A[0…s-1], A[s ], A[s+1…n-1],
使得
A[0…s-1]中任一元素A[s],
A[s+1…n-1]中任一元素 A[s]; 下标s 在划分过程中确定。
(2)递归求解:递归调用快速排序法分别对A[0…s-1]和A[s+1…n-1]排序。
(3)合并:合并A[0…s-1], A[s], A[s+1…n-1]为A[0…n-1]
使用基于两次扫描数组的方法:一次是从左到右,另一次从右到左,每次都把数组的元素和中轴进行比较。取决于扫描的指针是否相交,会发生3种不同的情况。如果扫描指针i和j不相交,也就是说i<j,我们简单地交换A[i]和A[j],再分别对i加一,j减一,然后继续开始扫描
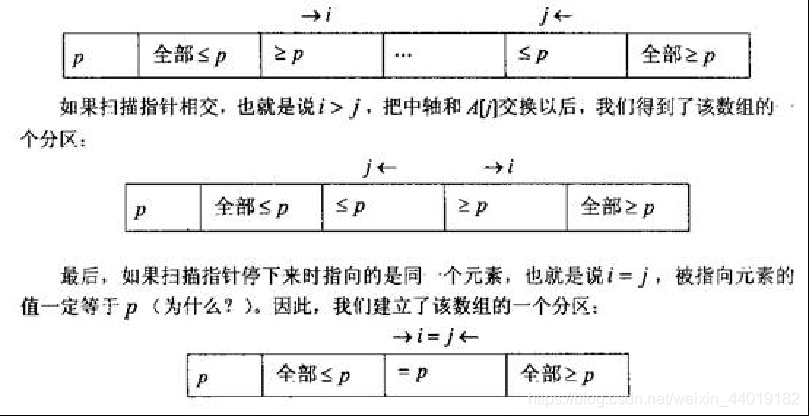
我们可以把第三种情况和指针相交的情况结合起来,只要i>=j,就交换中轴A[j]的位置。
数组的分区算法:
算法 Partition( A[l..r] )
// 以第一个元素为中轴,对子数组进行分区
// 输入:子数组A[l..r]
// 输出:分裂点/基准点pivot的位置
p ← A[l] i ← l; j ← r+1
repeat
repeat i ←i + 1 until A[i] ≥ p
repeat j ← j – 1 until A[j] ≤ p
swap( A[i], A[j] )
until i ≥ j
swap( A[i], A[j] ) //当i ≥j撤销最后一次交换
swap( A[l], A[j] )
return j
快速排序的例子(双向扫描)
例如:n=8
初始数组 A[0…n-1]=[8, 4, 1, 7, 11, 5, 6, 9],取元素A[0]=8作为分裂点,
位置: 0 1 2 3 4 5 6 7
{8, 4, 1, 7, 11, 5, 6, 9}
↑ ↑ 指针i、j分别向中间移动
{8, 4, 1, 7, 11, 5, 6, 9}
↑ ↑ 指针停止时,交换
{8, 4, 1, 7, 6, 5, 11, 9}
↑ ↑
快速排序的例子
分解得:A[0…s-1]=[4, 1, 7, 6, 5]; A[s]=8; A[s+1…7]=[11,9]; s=5
排序: A[0…s-1]=[1, 4, 5, 6, 7]; A[ s+1…n-1]=[9, 11]。
合并: 把A[0…s-1]中的元素放在分裂点元素8之前, A[s+1…n-1]中的元素放在分裂点元素之后, 结果[1, 4, 5, 6, 7, 8, 9, 11]
快速排序效率分析
- 基本操作:比较
- 最优情况:如果所有的分裂点位于相应子数组的中点,这就是最优的情况。在最优情况下,键值比较的次数Cbest(n)满足下面的递推式:
当n>1时, Cbest(n)=2 Cbest(n/2)+n, Cbest(1)=0
根据主定理, Cbest(n) ∈Θ(nlog2n) - 最坏情况下:
在进行了n+1次比较后建立了分区,还会对数组进行排序,继续到最后一个子数组A[n-2…n-1]。总比较次数为:
Cworst(n)=(n+1)+n+…+3
=(n+2)(n+1)/2-3 ∈Θ(n2) - 平均情况:假设分区的分裂点s(0 ≤ s ≤ n-1)位于每个位置的概率都是1/n,则有下面的递推式:
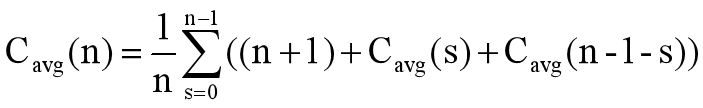
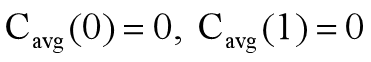
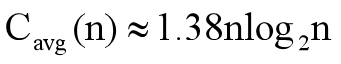
折半查找
对于有序数组的查找来说,折半查找是一种性能卓越的算法。它通过比较查找键K和数组中间元素A[m]来完成查找工作。如果它们相等,算法结束:否则,如果K<A[m],就对数组的前半部分执行该操作,如果K> A[m],则对数组的后半部分执行该操作:
swap A[i] and A[min]
A[0]…A[m-1] A[m] A[m+1]…A[n-1]
折半查找伪代码
BinarySearch( A[0..n-1], k )
// 输入:已排序大小为n的序列A,待搜索对象k
// 输出:如果搜索成功,则返回k的位置,否则返回-1
l=0,r=n-1;
While l≤r
mid= (l+r)/2
if k = A[mid] return mid
else if k < A[mid] r=mid-1
else l=mid+1
return -1
- 折半查找效率分析:
- 基本操作:比较
- 最坏情况下,比较次数
C(n)=C( n/2)+1
C(1)=1
设n=2k,可解得
C(n)=k+1=log2n+1
于是
C(n)∈Θ(log2n)
折半查找举例:
位置:0 1 2 3 4 5 6 7 8 9 10 11 12
值: 3,14,27,31,39,42,55,70,74,81,85,93,98
K=70
↑ ↑ ↑
迭代1 l=0 m=6 r=12
迭代2 l m=9 r
迭代3 l r
结果 m= (7+8)/2=7
二叉树遍历及其相关特性
二叉树高度的计算
算法 Height(T)
//输入一棵二叉树T
//输出二叉树的高度
//二叉树高度定义:叶子到树根的最长路径
if T=φ return -1
else
return max{Height(L), Height(R)}+1
例:计算上例中二叉树的高度
H(T)=1+max{H(2),H(6)}=2+max{H(3),H(4)}
=3+H(5)=5
二叉树遍历
- 所谓二叉树的遍历指的是遵循某一种次序来访问二叉树上的所有结点,使得树中每一个结点被访问了一次且只访问一次。
- 由于二叉树是一种非线性结构,树中的结点可能有不止一个的直接后继结点,所以遍历以前必须先规定访问的次序。
中序遍历(Inorder Traversal)
- 二叉树的中序遍历算法比较简单,使用递归的策略。在遍历以前首先确定遍历的树是否为空,如果为空,则直接返回;否则中序遍历的算法步骤如下:
- 对左子树L执行中序遍历算法
- 访问输出根结点V的值。
- 对右子树R执行中序遍历算法。
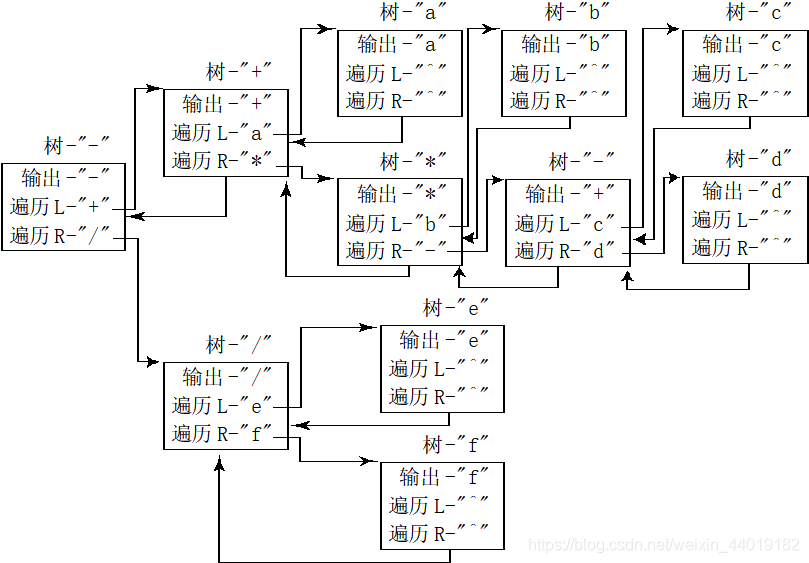
前序遍历(Preorder Traversal)
- 有了上面的中序遍历的过程,前序遍历也是类似的。在遍历以前首先确定遍历的树是否为空,如果为空,则直接返回;否则前序遍历的算法步骤如下:
- 访问输出根结点V的值;
- 对左子树L执行前序遍历算法。
- 对右子树R执行前序遍历算法。
前序遍历执行过程图
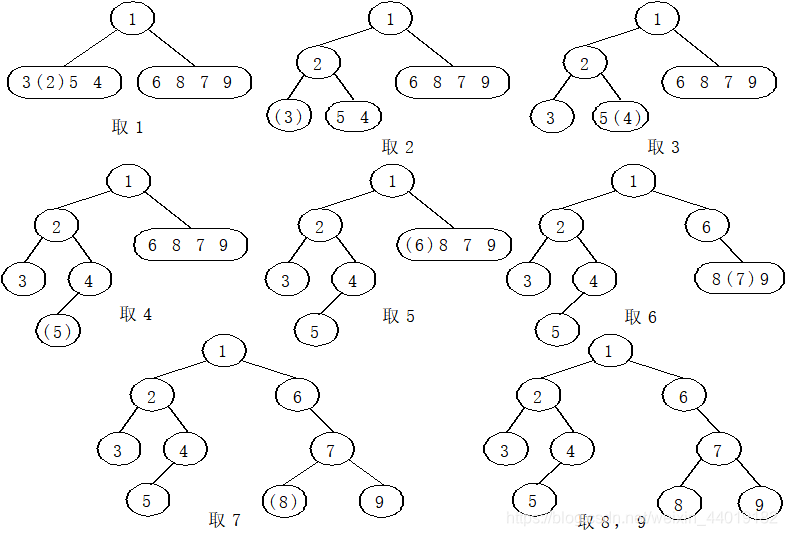
二叉树的构造
大整数乘法和Strassen矩阵乘法
设A、B为两个n位的大整数,直接计算需要执行n2次1位数的乘法。
A=a110n/2+a2 ,B=b110n/2+b2
直接计算:
A·B=(a110n/2+a2)(b110n/2+b2)
=a1b110n+(a1b2+a2b1)10n/2+a2b2
递归公式为:
C(n)=4C(n/2)+k·n
C(1)=1
解得 C(n)∈ O(n2)
改进的乘法
A·B=(a110n/2+a2)(b110n/2+b2)
=a1b110n+(a1b2+a2b1)10n/2+a2b2
=a1b110n+[(a1+a2)(b1+b2)-a1b1-a2b2)]10n/2+a2b2验证:
[(a1+a2)(b1+b2)-a1b1-a2b2)]=(a1b2+a2b1)这种方法需要3次n/2位的乘法及一些加减法。
记C(n)为计算两个n位整数相乘所需的基本操作执行次数,则有
C(n)=3C(n/2)+k·n
C(1)=1
其中,k为常数。
解此递归方程,得
C(n)=nlog3+2knlog3-2kn
∈O(nlog3) ≈O(n1.58)
可见,乘法效率有改善。
Strassen矩阵乘法
矩阵乘法是线性代数中最常见的运算之一,它在数值计算中有广泛的应用。若A和B是2个n×n的矩阵,则它们的乘积C=A×B同样是一个n×n的矩阵。A和B的乘积矩阵C中的元素C[i,j]定义为:

若依此定义来计算A和B的乘积矩阵C,则每计算C的一个元素C[i,j],需要做n个乘法和n-1次加法。因此,求出矩阵C的n2个元素所需的计算时间为O(n3)。
Strassen采用了分治技术,将计算2个n阶矩阵乘积所需的计算时间改进到
O(nlog27)=O(n2.18)。
首先,假设n=2k。将矩阵A,B和C中每一矩阵都分块成为4个大小相等的子矩阵,每个子矩阵都是n/2×n/2的方阵。由此可将方程C=A×B重写为:
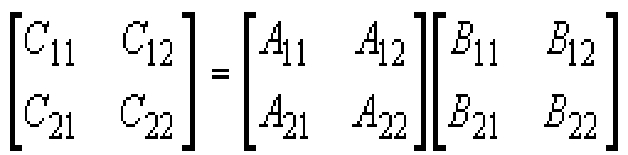
其中:
C11=A11B11+A12B21
C12=A11B12+A12B22
C21=A21B11+A22B21
C22=A21B12+A22B22
则2个2阶方阵的乘积可以直接用上式计算出来,共需8次乘法和4次加法。当子矩阵的阶大于2时,为求2个子矩阵的积,可以继续将子矩阵分块,直到子矩阵的阶降为2。依此算法,计算2个n阶方阵的乘积转化为计算8个n/2阶方阵的乘积和4个n/2阶方阵的加法(可在n2内完成)。因此,上述分治法的计算时间耗费T(n)应该满足:
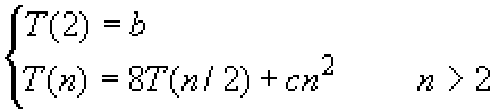
这个递归方程的解仍然是T(n)=O(n3)
Strassen提出了一种新的算法来计算2个2阶方阵的乘积。他的算法只用了7次乘法运算,但增加了加、减法的运算次数。这7次乘法是:
M1=A11(B12-B22)
M2=(A11+A12)B22
M3=(A21+A22)B11
M4=A22(B21-B11)
M5=(A11+A22)(B11+B22)
M6=(A12-A22)(B21+B22)
M7=(A11-A21)(B11+B12)
于是可得到:
C11=M5+M4-M2+M6
C12=M1+M2
C21=M3+M4
C22=M5+M1-M3-M7
以上计算的正确性很容易验证。Strassen矩阵乘积分治算法中,用了7次对于n/2阶矩阵乘积的递归调用和18次n/2阶矩阵的加减运算。由此可知,该算法的所需的计算时间T(n)满足如下的递归方程:
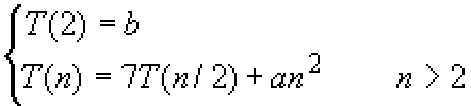
其解为T(n)∈O(nlog7)≈O(n2.81)。
由此可见,Strassen矩阵乘法的计算时间复杂性比普通矩阵乘法有阶的改进。
分治法解最近点对问题
问题: 给定平面S上n个点,找其中的一对点,使得在n(n-1)/2个点对中, 该点对的距离最小。
算法思路:
1. n较小时直接求(n=2).
2. S上的n个点分成大致相等的2个子集S1和S2
3. 分别求S1和S2中的最接近点对
4. 求一点在S1、另一点在S2中的最近点对
5. 从上述三对点中找距离最近的一对.
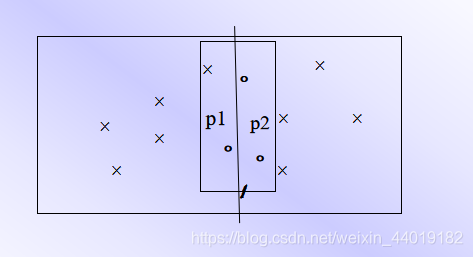
- 选取一垂直线l:x=m来作为分割直线。其中m为S中各点x坐标的中位数。由此将S分割为S1和S2。
- 递归地在S1和S2上找出其最小距离d1和d2,并设d=min{d1,d2},S中的最接近点对或者是d,或者是某个{p,q},其中p∈S1且q∈S2。
- 能否在线性时间内找到p,q?
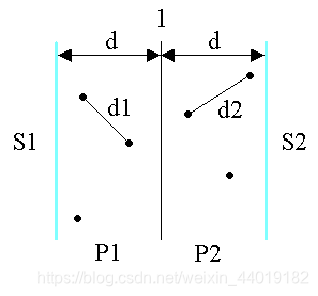
- 考虑P1中任意一点p,它若与P2中的点q构成最接近点对的候选者,则必有d(p,q)<d。满足这个条件的P2中的点一定落在一个d×2d的矩形R中
- 由d的意义可知,P2中任何2个S中的点的距离都不小于d。由此可以推出矩形R中最多只有6个S中的点。
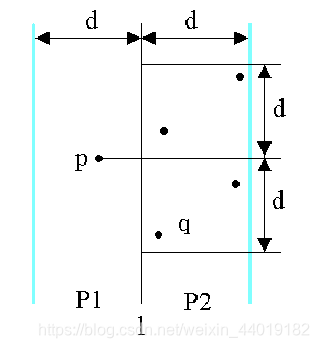
- 为了确切地知道要检查哪6个点,可以将p和P2中所有S2的点投影到垂直线l上。由于能与p点一起构成最接近点对候选者的S2中点一定在矩形R中,所以它们在直线l上的投影点距p在l上投影点的距离小于d。由上面的分析可知,这种投影点最多只有6个。
- 因此,若将P1和P2中所有S中点按其y坐标排好序,则对P1中所有点,对排好序的点列作一次扫描,就可以找出所有最接近点对的候选者。对P1中每一点最多只要检查P2中排好序的相继6个点。
快包算法
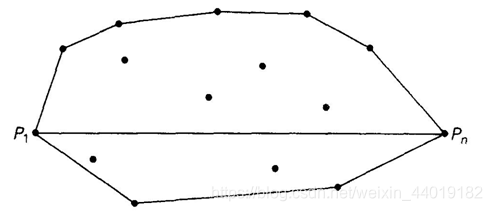
- 假设P1=(x1,y1),…,Pn=(Xn,Yn)是平面上n个点构成的集合S,这些点是按它们的x轴坐标升序排列的,并按照y轴坐标的升序建立连接。
- 最左面的点P1和最右面的点Pn一定是该集合的凸包顶点。
- 设向量P1Pn把点分为两个集合:S1是位于直线左侧或在直线上的点构成的集合:S2是位于直线右侧或在直线上的点构成的集合(如果向量P1P2是方向从P1到P2的直线,如果P1P2P3构成构成一个逆时针的回路,我们说点P3位于向量P1P2的左侧。
- 算法找到S1中的顶点P.max,它是距离直线P1Pn最远的点。如果作两条连接线的话,这个点确定了最大的三角形△P.maxP1Pn。
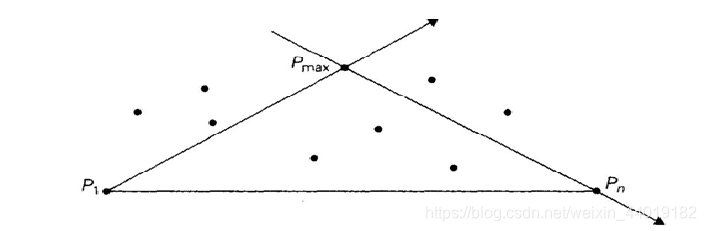
- 然后算法找出S1中所有在直线P1P.max左边的点;这些点以及P1和P.max,构成了集合S1,1。S1中在直线P.maxPn左边的点以及P.max和Pn构成了集合S1,2。不难证明,同时位于这两条直线左边的点是不存在的。包含在△P1P.maxPn之中的点也可以不再考虑了。
- 如果P1=(x1,y1),P2=(x2,y2),P3=(x3,y3)是平面上的任意三个点,那么三角形△P1P2P3的面积等于下面这个行列式绝对值的二分之一:

- 当且仅当点P3=(x3,y3)位于直线P1P2的左侧时,该表达式的符号为正。使用这个公式,我们可以在固定的时间内,检查一个点是否位于两个点确定的直线的左侧,并且可以求得这个点到这根直线的距离。
- 快包算法的效率:平均效率是Θ (n㏒n),最差效率是Θ(n2) 。














 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









