







今天我们来学习一下怎么爬取m3u8格式的视频
需要用到:
- 浏览器
- import requests
- import re
- import time
可能有些小伙伴不知道该怎么安装第三方库,现在我来教你们一下:
1、打开cmd,快捷键是win+r。
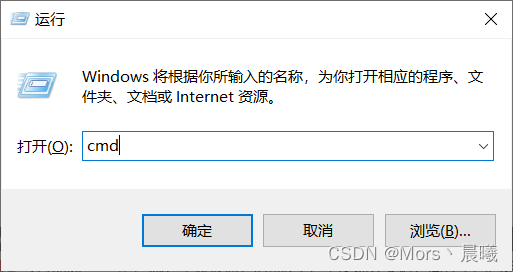
可以看到黑框框
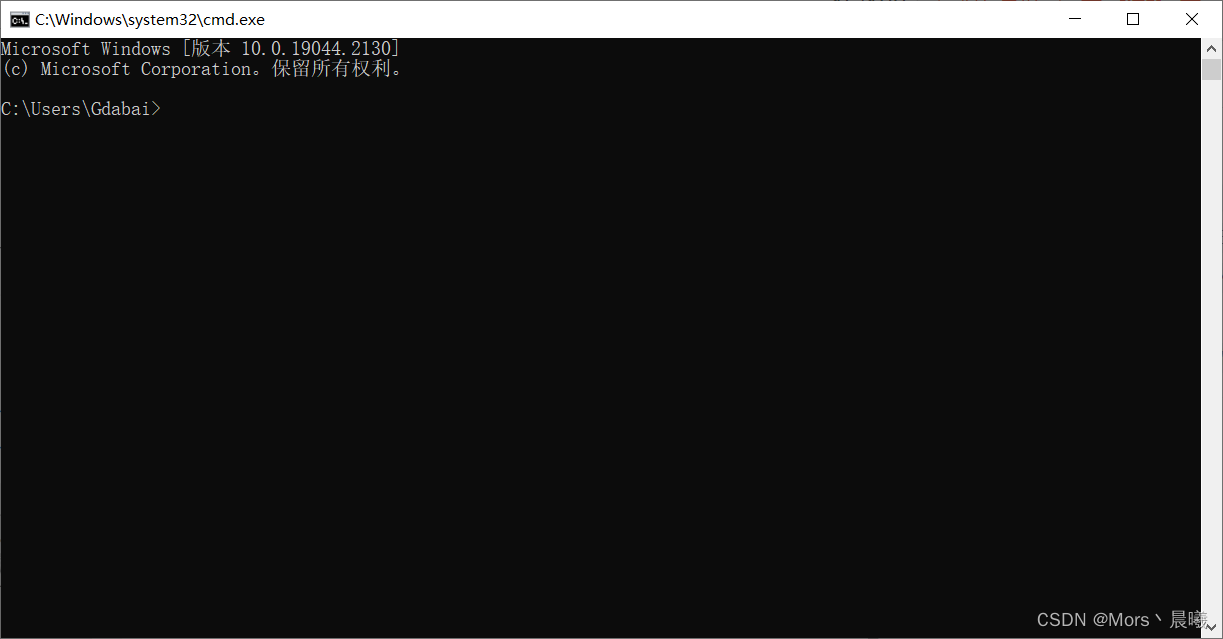
2、在这里输入pip install 你想要安装的库,就可以安装成功。
现在可以开始我们今天重点内容了
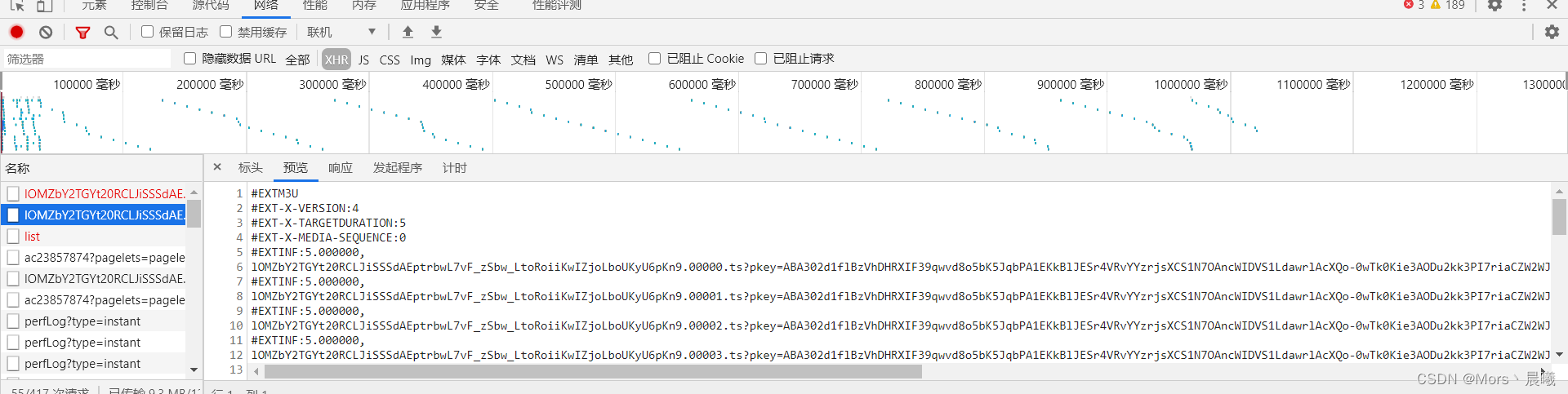
m3u8文件可以看到是这样的
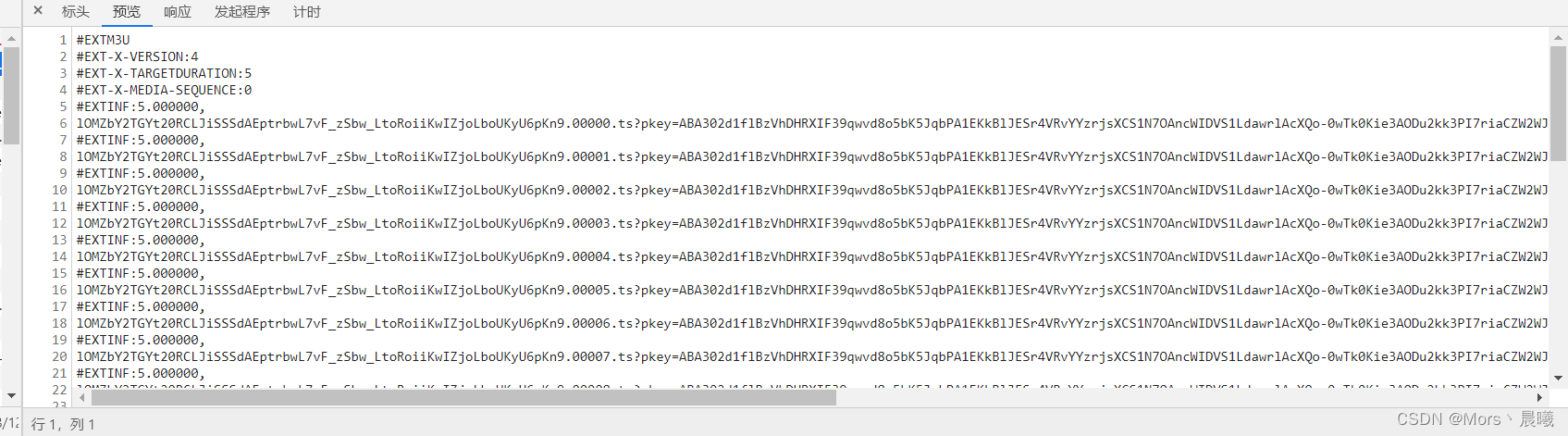
该怎么找到m3u8文件
1、按下F12
2、刷新页面,点击视频,然后再暂停
3、
来到这里,就可以看到了
接下来是代码:
这样就爬取完成了,看我们爬下来的视频
是不是很简单
在这里插入代码片
import requests
import re
import time
url='https://********/*****/*****/****/hls/lOMZbY2TGYt20RCLJiSSSdAEptrbwL7vF_zSbw_LtoRoiiKwIZjoLboUKyU6pKn9.m3u8?pkey=ABA302d1flBzVhDHRXIF39qwvd8o5bK5JqbPA1EKkBlJESr4VRvYYzrjsXCS1N7OAncWIDVS1LdawrlAcXQo-0wTk0Kie3AODu2kk3PI7riaCZW2WJ6ongGYK9rIKAY3pUSY59oMXCB7D5tFIbh7-rpKBBaSQ9IZXjRNhNoDOWRhJzEkEISuIMfKgn6zKcfSexLsJh4-ucu7Za-HRS7G9roGvzcdOT5IZ71s3qQSIsL4N-Y4LcU0_BGtgjjEZ1SwnI&safety_id=AALrSHa5ZUGUIeiZEyd5A3V6'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'}
response=requests.get(url=url,headers=headers).text
m3u8_list=re.sub('#E.*','',response).split()
print('开始下载视频')
for i in m3u8_list:
url='https://********/********/********/acfun_video/hls/'+i
ts_content=requests.get(url=url,headers=headers).content
with open('D:\代码库\python**\python爬虫**\**\****小姐姐**.mp4','ab') as file:
file.write(ts_content)
time.sleep(0.5)
print('视频下载完成')
现在可能有些小伙伴不知道该怎么获得User-Agent,以及为什么url=‘https:////********/acfun_video/hls/’+i我在这边拼接了这个字符串。
1、User-Agent的获得,随便打开一个网页,按下F12,刷新点击到network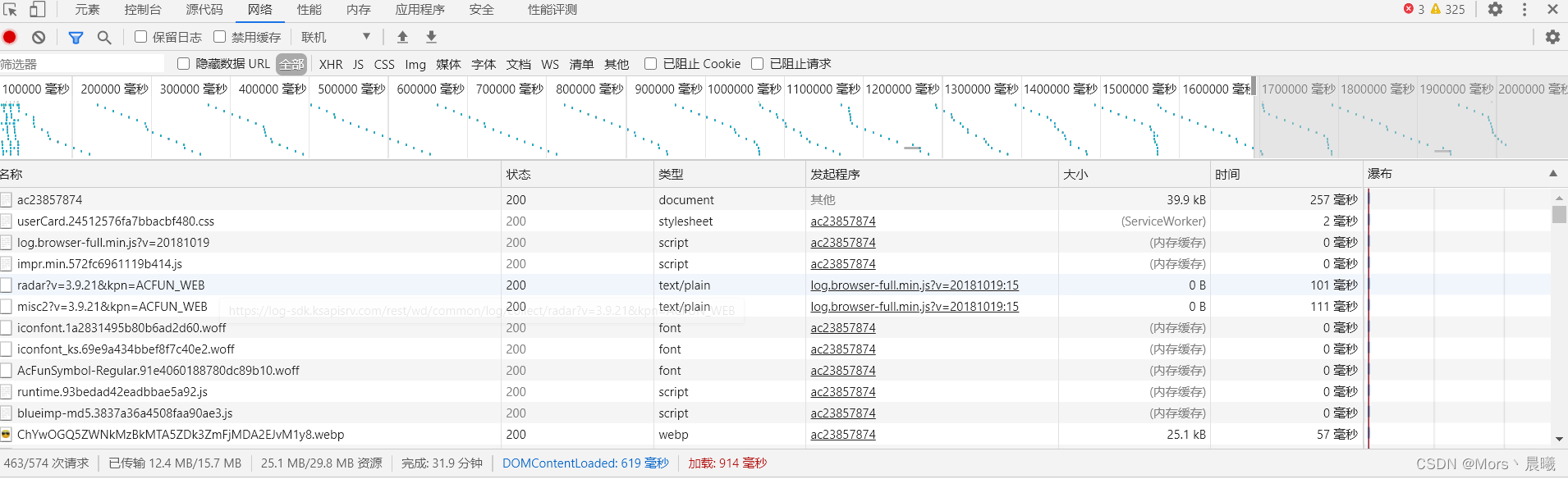
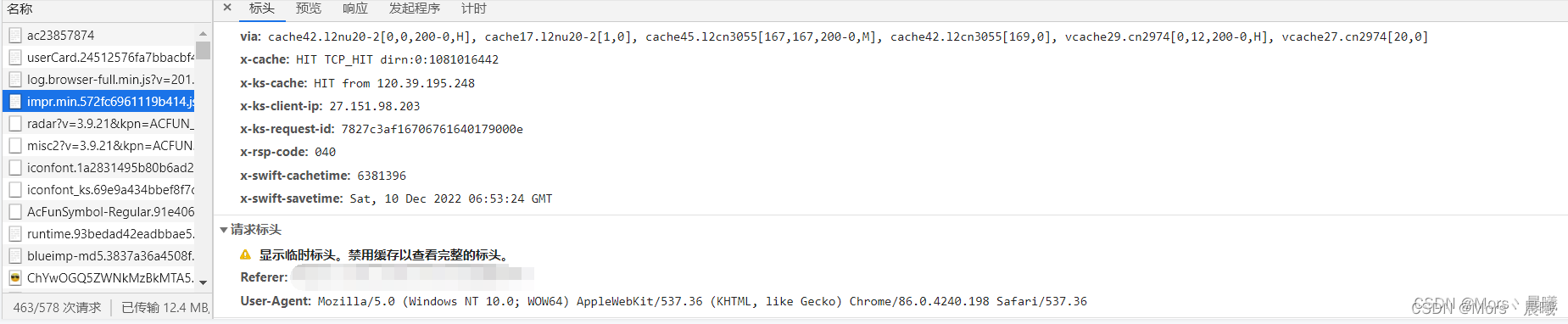
2、time.sleep(0.5)为什么要加这行,是因为防止访问太快给服务器造成困扰,这个地方很重要,一定要加上。
3、url=‘https:////********/acfun_video/hls/’+i为什么要拼接,是因为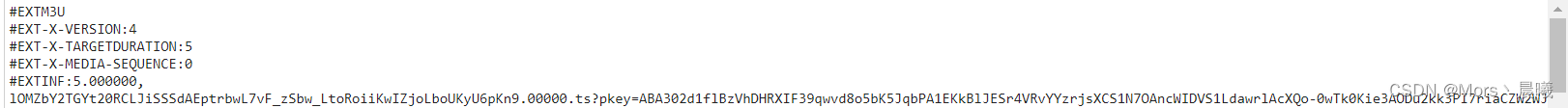
有没有发现他不是http开头的,说明他还有部分没了,需要找到一个ts

然后把缺的部分拼接一下,就可以正常使用了。
4、with open(‘D:\代码库\python***\python爬虫******小姐姐.mp4’,‘ab’) as file:,这行可以直接完成ts格式的转mp4格式
















 3315
3315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











