










本文我们介绍一下Spark的Rpc网络框架,Spark框架当中很多地方都涉及网络通信,比如Spark各个组件间的消息互通、用户文件与Jar包的上传、节点间的Shuffle过程、Block数据的复制与备份等,在Spark0.x.x与Spark 1.x.x版本中组件之间的消息通信都借助于Akka,但是在Spark2.0版本中,基于Akka实现的Rpc被废弃掉,2.x和之后都使用的是Netty。本文介绍的版本是Spark2.1.1
SparkRpc整体架构图

我们先拿一个混入RpcEndpoint的组件Master的启动来具体分析一下
流程分析

我们看到,首先是先创建一个RpcEnv,我们点进去
private[spark] object RpcEnv {
def create(
name: String,
host: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
clientMode: Boolean = false): RpcEnv = {
create(name, host, host, port, conf, securityManager, 0, clientMode)
}
def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
numUsableCores: Int,
clientMode: Boolean): RpcEnv = {
// 用于保存RpcEnv的配置信息
val config = RpcEnvConfig(conf, name, bindAddress, advertiseAddress, port, securityManager,
numUsableCores, clientMode)
// 通过工厂创建NettyRpcEnv
new NettyRpcEnvFactory().create(config)
}
}
这里RpcEnvConfig是一个样例类,然后将信息传入 create()方法,我们之间点进去看一下
private[rpc] class NettyRpcEnvFactory extends RpcEnvFactory with Logging {
/**
*
* 创建RpcEnv
*/
def create(config: RpcEnvConfig): RpcEnv = {
val sparkConf = config.conf
// Use JavaSerializerInstance in multiple threads is safe. However, if we plan to support
// KryoSerializer in future, we have to use ThreadLocal to store SerializerInstance
/**
* 创建javaSerializerInstance。此实例将用于RPC传输对象的序列化。
*/
val javaSerializerInstance =
new JavaSerializer(sparkConf).newInstance().asInstanceOf[JavaSerializerInstance]
/**
* 创建NettyRpcEnv。创建NettyRpcEnv其实就是对内部各个子组件TransportConf、Dispatcher、TransportContext、TransportClientFactory、TransportServer的实例化过程
*/
val nettyEnv =
new NettyRpcEnv(sparkConf, javaSerializerInstance, config.advertiseAddress,
config.securityManager, config.numUsableCores)
if (!config.clientMode) {
// 启动NettyRpc环境
val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
/**
* 启动服务
* 1. dispatcher 服务启动的时候,会直接启动一个线程,不断取receivers队列里面的数据
* 2.TransportServer 数据传输服务。init初始化方法会创建一个TransportChannelHandler,
* 内部的channelReader方法。最终会调用dispatcher的postRemoteMessage方法,往队列中添加数据
*/
nettyEnv.startServer(config.bindAddress, actualPort)
(nettyEnv, nettyEnv.address.port)
}
try {
// startServiceOnPort实际上是调用了作为参数的偏函数startNettyRpcEnv
Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch {
case NonFatal(e) =>
nettyEnv.shutdown()
throw e
}
}
nettyEnv
}
}
这里之间new创建了NettyRpcEnv,内部会对很多子组件进行实例化,我们具体看一下
private[netty] class NettyRpcEnv(
val conf: SparkConf,
javaSerializerInstance: JavaSerializerInstance,
host: String,
securityManager: SecurityManager,
numUsableCores: Int) extends RpcEnv(conf) with Logging {
// 创建传输上下文TransportConf
private[netty] val transportConf = SparkTransportConf.fromSparkConf(
conf.clone.set("spark.rpc.io.numConnectionsPerPeer", "1"),
"rpc",
// netty传输线程数
conf.getInt("spark.rpc.io.threads", 0))
private val dispatcher: Dispatcher = new Dispatcher(this, numUsableCores)
private val streamManager = new NettyStreamManager(this)
private val transportContext = new TransportContext(transportConf,
new NettyRpcHandler(dispatcher, this, streamManager))
private def createClientBootstraps(): java.util.List[TransportClientBootstrap] = {
if (securityManager.isAuthenticationEnabled()) {
java.util.Arrays.asList(new AuthClientBootstrap(transportConf,
securityManager.getSaslUser(), securityManager))
} else {
java.util.Collections.emptyList[TransportClientBootstrap]
}
}
private val clientFactory = transportContext.createClientFactory(createClientBootstraps())
@volatile private var fileDownloadFactory: TransportClientFactory = _
val timeoutScheduler = ThreadUtils.newDaemonSingleThreadScheduledExecutor("netty-rpc-env-timeout")
private[netty] val clientConnectionExecutor = ThreadUtils.newDaemonCachedThreadPool(
"netty-rpc-connection",
conf.getInt("spark.rpc.connect.threads", 64))
@volatile private var server: TransportServer = _
private val stopped = new AtomicBoolean(false)
private val outboxes = new ConcurrentHashMap[RpcAddress, Outbox]()
我们一个一个来分析
TransportConf
通过调用SparkTransportConf.fromSparkConf()来创建,
* 传递的三个参数分别为SparkConf、模块名module及可用的内核数num-UsableCores。
* 如果numUsableCores小于等于0,那么线程数是系统可用处理器的数量,不过分配给网络传输的内核数量最多限制在8个。
* 最终确定的线程数将用于设置客户端传输线程数(spark.$module.io.clientThreads属性)和
* 服务端传输线程数(spark.$module.io.serverThreads属性)
* from-SparkConf的get的实现是SparkConf的get方法
*/
def fromSparkConf(_conf: SparkConf, module: String, numUsableCores: Int = 0): TransportConf = {
val conf = _conf.clone
// Specify thread configuration based on our JVM's allocation of cores (rather than necessarily
// assuming we have all the machine's cores).
// NB: Only set if serverThreads/clientThreads not already set.
val numThreads = defaultNumThreads(numUsableCores)
conf.setIfMissing(s"spark.$module.io.serverThreads", numThreads.toString)
conf.setIfMissing(s"spark.$module.io.clientThreads", numThreads.toString)
new TransportConf(module, new ConfigProvider {
override def get(name: String): String = conf.get(name)
override def get(name: String, defaultValue: String): String = conf.get(name, defaultValue)
override def getAll(): java.lang.Iterable[java.util.Map.Entry[String, String]] = {
conf.getAll.toMap.asJava.entrySet()
}
})
}
Dispatcher
内存模型

Dispatcher负责将RPC消息路由到要该对此消息处理的RpcEndpoint(RPC端点),能有效提高NettyRpcEnv对消息异步处理并最大提升并行处理能力。这里是直接new出来的,我们之间点进去看一下
private[netty] class Dispatcher(nettyEnv: NettyRpcEnv, numUsableCores: Int) extends Logging {
/**
* RPC端点数据,它包括了RpcEndpoint、NettyRpcEndpointRef及Inbox等属于同一个端点的实例。
* Inbox与RpcEndpoint、NettyRpcEndpointRef通过此EndpointData相关联。
* @param name
* @param endpoint
* @param ref
*/
private class EndpointData(
val name: String,
val endpoint: RpcEndpoint,
val ref: NettyRpcEndpointRef) {
val inbox = new Inbox(ref, endpoint)
}
/**
* 端点实例名称与端点数据EndpointData之间映射关系的缓存。
* 有了这个缓存,就可以使用端点名称从中快速获取或删除EndpointData了。
*/
private val endpoints: ConcurrentMap[String, EndpointData] =
new ConcurrentHashMap[String, EndpointData]
/**
* 端点实例RpcEndpoint与端点实例引用RpcEndpointRef之间映射关系的缓存。
* 有了这个缓存,就可以使用端点实例从中快速获取或删除端点实例引用了。
*/
private val endpointRefs: ConcurrentMap[RpcEndpoint, RpcEndpointRef] =
new ConcurrentHashMap[RpcEndpoint, RpcEndpointRef]
// Track the receivers whose inboxes may contain messages.
/**
* 存储端点数据EndpointData的阻塞队列。只有Inbox中有消息的EndpointData才会被放入此阻塞队列。
*/
private val receivers = new LinkedBlockingQueue[EndpointData]
/**
* True if the dispatcher has been stopped. Once stopped, all messages posted will be bounced
* immediately.
*
* Dispatcher是否停止的状态。
*/
@GuardedBy("this")
private var stopped = false
......
/** Thread pool used for dispatching messages. */
/**
* 用于对消息进行调度的线程池。此线程池运行的任务都是MessageLoop
* 1. 获取此线程池的大小numThreads。此线程池的大小默认为2与当前系统可用处理器数量之间的最大值,也可以使用spark.rpc.netty.dispatcher.numThreads属性配置。
* 2 .创建线程池。此线程池是固定大小的线程池,并且启动的线程都以后台线程方式运行,且线程名以dispatcher-event-loop为前缀。
* 3. 启动多个运行MessageLoop任务的线程,这些线程的数量与threadpool线程池的大小相同。
* 4. 返回此线程池的引用。
*
*
*/
private val threadpool: ThreadPoolExecutor = {
val availableCores =
if (numUsableCores > 0) numUsableCores else Runtime.getRuntime.availableProcessors()
val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads",
math.max(2, availableCores))
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "dispatcher-event-loop")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop)
}
pool
}
/** Message loop used for dispatching messages. */
/**
* 不断循环处理消息
* 1. 从receivers中获取EndpointData。receivers中的EndpointData,其Inbox的messages列表中肯定有了新的消息。
* 换言之,只有Inbox的messages列表中有了新的消息,此EndpointData才会被放入receivers中。
* 由于receivers是个阻塞队列,所以当receivers中没有EndpointData时,MessageLoop线程会被阻塞。
* 2. 如果取到的EndpointData是“毒药”(PoisonPill),那么此MessageLoop线程将退出(通过return语句),
* 并且会再次将PoisonPill放到队列里面,以达到所有MessageLoop线程都结束的效果。
* 3. 如果取到的EndpointData不是“毒药”,那么调用EndpointData中Inbox的process方法对消息进行处理。
*/
private class MessageLoop extends Runnable {
override def run(): Unit = {
try {
while (true) {
try {
//
val data = receivers.take()
// 如果数据为毒药
if (data == PoisonPill) {
// Put PoisonPill back so that other MessageLoops can see it.
receivers.offer(PoisonPill)
return
}
// 对消息做处理
data.inbox.process(Dispatcher.this)
} catch {
case NonFatal(e) => logError(e.getMessage, e)
}
}
} catch {
case _: InterruptedException => // exit
case t: Throwable =>
try {
// Re-submit a MessageLoop so that Dispatcher will still work if
// UncaughtExceptionHandler decides to not kill JVM.
threadpool.execute(new MessageLoop)
} finally {
throw t
}
}
}
}
/** A poison endpoint that indicates MessageLoop should exit its message loop. */
private val PoisonPill = new EndpointData(null, null, null)
}
上面的MessageLoop任务实际是将消息交给EndpointData中Inbox的process方法处理,我们先看一下Inbox
Inbox
/**
* An inbox that stores messages for an [[RpcEndpoint]] and posts messages to it thread-safely.
*
* 端点内的盒子。每个RpcEndpoint都有一个对应的盒子,这个盒子里有个存储InboxMessage消息的列表messages。
* 所有的消息将缓存在messages列表里面,并由RpcEndpoint异步处理这些消息
*/
private[netty] class Inbox(
val endpointRef: NettyRpcEndpointRef,
val endpoint: RpcEndpoint)
extends Logging {
inbox => // Give this an alias so we can use it more clearly in closures.
/**
* 消息列表。用于缓存需要由对应RpcEndpoint处理的消息,即与Inbox在同一EndpointData中的RpcEndpoint
* 非线程安全,进行并发操作需要加锁控制
*/
@GuardedBy("this")
protected val messages = new java.util.LinkedList[InboxMessage]()
/** True if the inbox (and its associated endpoint) is stopped. */
/**
* Inbox的停止状态。
*/
@GuardedBy("this")
private var stopped = false
/** Allow multiple threads to process messages at the same time. */
/**
* 是否允许多个线程同时处理messages中的消息。
*/
@GuardedBy("this")
private var enableConcurrent = false
/** The number of threads processing messages for this inbox. */
/**
* 激活线程的数量,即正在处理messages中消息的线程数量。
*/
@GuardedBy("this")
private var numActiveThreads = 0
// OnStart should be the first message to process
inbox.synchronized {
messages.add(OnStart)
}
......
}
这里newInbox的时候,就已经先往自己的消息列表中扔进了一个OnStart的消息,
截下来我们看一下Inbox处理消息的逻辑,process()
/**
* Process stored messages.
* 处理消息
* 1. 进行线程并发检查。具体是,如果不允许多个线程同时处理messages中的消息(enableConcurrent为false),
* 并且当前激活线程数(numActiveThreads)不为0,这说明已经有线程在处理消息,所以当前线程不允许再去处理消息(使用return返回)。
* 2. 从messages中获取消息。如果有消息未处理,则当前线程需要处理此消息,因而算是一个新的激活线程(需要将numActiveThreads加1)。如果messages中没有消息了(一般发生在多线程情况下),则直接返回。
* 3.根据消息类型进行匹配,并执行对应的逻辑
* 4. 对激活线程数量进行控制。当第3步对消息处理完毕后,当前线程作为之前已经激活的线程是否还有存在的必要呢?
* 这里有两个判断:
* 1. 如果不允许多个线程同时处理messages中的消息并且当前激活的线程数多于1个,那么需要当前线程退出并将numActiveThreads减1;
* 2. 如果messages已经没有消息要处理了,这说明当前线程无论如何也该返回并将numActiveThreads减1。
*/
def process(dispatcher: Dispatcher): Unit = {
var message: InboxMessage = null
inbox.synchronized {
if (!enableConcurrent && numActiveThreads != 0) {
return
}
message = messages.poll()
if (message != null) {
numActiveThreads += 1
} else {
return
}
}
while (true) {
/**
* 根据消息类型进行匹配,并执行对应的逻辑
*/
safelyCall(endpoint) {
message match {
// rpc请求的话,直接调用endpoint的receiveAndReply
case RpcMessage(_sender, content, context) =>
try {
endpoint.receiveAndReply(context).applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
})
} catch {
case e: Throwable =>
context.sendFailure(e)
// Throw the exception -- this exception will be caught by the safelyCall function.
// The endpoint's onError function will be called.
throw e
}
case OneWayMessage(_sender, content) =>
endpoint.receive.applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
})
case OnStart =>
endpoint.onStart()
if (!endpoint.isInstanceOf[ThreadSafeRpcEndpoint]) {
inbox.synchronized {
if (!stopped) {
enableConcurrent = true
}
}
}
case OnStop =>
val activeThreads = inbox.synchronized { inbox.numActiveThreads }
assert(activeThreads == 1,
s"There should be only a single active thread but found $activeThreads threads.")
// 删除endpointRef和endpoint的引用关系
dispatcher.removeRpcEndpointRef(endpoint)
endpoint.onStop()
assert(isEmpty, "OnStop should be the last message")
case RemoteProcessConnected(remoteAddress) =>
endpoint.onConnected(remoteAddress)
case RemoteProcessDisconnected(remoteAddress) =>
endpoint.onDisconnected(remoteAddress)
case RemoteProcessConnectionError(cause, remoteAddress) =>
endpoint.onNetworkError(cause, remoteAddress)
}
}
inbox.synchronized {
// "enableConcurrent" will be set to false after `onStop` is called, so we should check it
// every time.
if (!enableConcurrent && numActiveThreads != 1) {
// If we are not the only one worker, exit
numActiveThreads -= 1
return
}
message = messages.poll()
if (message == null) {
numActiveThreads -= 1
return
}
}
}
}
这里操作messages是在Inbox的锁保护之下,是因为messages是普通的java.util.LinkedList, LinkedList本身不是线程安全的,所以为了增加并发安全性,需要通过同步保护
这里可以总结一下,MessageLoop线程的执行逻辑是不断地消费各个EndpointData中Inbox里的消息
然后我们继续往下看,创建的下一个组件NettyStreamManager
NettyStreamManager
这里组件是专用于为NettyRpcEnv提供文件服务的能力
private[netty] class NettyStreamManager(rpcEnv: NettyRpcEnv)
extends StreamManager with RpcEnvFileServer {
private val files = new ConcurrentHashMap[String, File]()
private val jars = new ConcurrentHashMap[String, File]()
private val dirs = new ConcurrentHashMap[String, File]()
override def getChunk(streamId: Long, chunkIndex: Int): ManagedBuffer = {
throw new UnsupportedOperationException()
}
/**
* 由于NettyStreamManager只实现了Stream Manager的openStream方法,根据TransportRequestHandler的handle方法和process StreamRequest方法,
* 知道NettyStreamManager将只提供对StreamRequest类型消息的处理。
* 各个Executor节点就可以使用Driver节点的RpcEnv提供的NettyStreamManager,从Driver将Jar包或文件下载到Executor节点上供任务执行。
* @param streamId id of a stream that has been previously registered with the StreamManager.
* */
override def openStream(streamId: String): ManagedBuffer = {
val Array(ftype, fname) = streamId.stripPrefix("/").split("/", 2)
val file = ftype match {
case "files" => files.get(fname)
case "jars" => jars.get(fname)
case other =>
val dir = dirs.get(ftype)
require(dir != null, s"Invalid stream URI: $ftype not found.")
new File(dir, fname)
}
if (file != null && file.isFile()) {
new FileSegmentManagedBuffer(rpcEnv.transportConf, file, 0, file.length())
} else {
null
}
}
override def addFile(file: File): String = {
val existingPath = files.putIfAbsent(file.getName, file)
require(existingPath == null || existingPath == file,
s"File ${file.getName} was already registered with a different path " +
s"(old path = $existingPath, new path = $file")
s"${rpcEnv.address.toSparkURL}/files/${Utils.encodeFileNameToURIRawPath(file.getName())}"
}
override def addJar(file: File): String = {
val existingPath = jars.putIfAbsent(file.getName, file)
require(existingPath == null || existingPath == file,
s"File ${file.getName} was already registered with a different path " +
s"(old path = $existingPath, new path = $file")
s"${rpcEnv.address.toSparkURL}/jars/${Utils.encodeFileNameToURIRawPath(file.getName())}"
}
override def addDirectory(baseUri: String, path: File): String = {
val fixedBaseUri = validateDirectoryUri(baseUri)
require(dirs.putIfAbsent(fixedBaseUri.stripPrefix("/"), path) == null,
s"URI '$fixedBaseUri' already registered.")
s"${rpcEnv.address.toSparkURL}$fixedBaseUri"
}
}
我们继续看下一个创建的对象TransportContext,不过在创建这个对象传入了一个NettyRpcHandler,我们先看一下NettyRpcHandler
NettyRpcHandler
* NettyRpcHandler除实现了RpcHandler的两个receive方法,还实现了exception-Caught、channelActive与channelInactive等。exceptionCaught方法将会向Inbox中投递Remote ProcessConnectionError消 息。channelActive将 会 向Inbox中投 递RemoteProcess-Connected。
*
* channelInactive将会向Inbox中投递RemoteProcessDisconnected消息。这几个方法的处理都与receive方法类似
*
*/
private[netty] class NettyRpcHandler(
dispatcher: Dispatcher,
nettyEnv: NettyRpcEnv,
streamManager: StreamManager) extends RpcHandler with Logging {
// A variable to track the remote RpcEnv addresses of all clients
private val remoteAddresses = new ConcurrentHashMap[RpcAddress, RpcAddress]()
/**
* 1. 调用internalReceive方法将ByteBuffer类型的message转换为RequestMessage。
* 2. 调用Dispatcher的postRemoteMessage方法将消息转换为RpcMessage后放入Inbox的消息列表。
* MessageLoop将调用RpcEnd-Point实现类的receiveAndReply方法,即RpcEndPoint处理完消息后会向客户端进行回复
*
* @param client A channel client which enables the handler to make requests back to the sender
* of this RPC. This will always be the exact same object for a particular channel.
* @param message The serialized bytes of the RPC.
* @param callback Callback which should be invoked exactly once upon success or failure of the
* RPC.
*
*/
override def receive(
client: TransportClient,
message: ByteBuffer,
callback: RpcResponseCallback): Unit = {
// 将ByteBuffer类型的message转换为RequestMessage。
val messageToDispatch = internalReceive(client, message)
dispatcher.postRemoteMessage(messageToDispatch, callback)
}
/**
*
* @param client A channel client which enables the handler to make requests back to the sender
* of this RPC. This will always be the exact same object for a particular channel.
* @param message The serialized bytes of the RPC.
*
* 此方法不会对客户端进行回复。此方法也调用了internalReceive方法,但是最后向EndpointData的Inbox投递消息使用了postOneWayMessage方法
*
* 只接收TransportClient和ByteBuffer两个参数,RpcResponse-Callback为默认的ONE_WAY_CALLBACK,
*/
override def receive(
client: TransportClient,
message: ByteBuffer): Unit = {
val messageToDispatch = internalReceive(client, message)
dispatcher.postOneWayMessage(messageToDispatch)
}
/**
* 1. 从TransportClient中获取远端地址RpcAddress。
* 2. 调用NettyRpcEnv的deserialize方法对客户端发送的序列化后的消息(即ByteBuffer类型的消息)进行反序列化,根据deserialize的实现,
* 反序列化实际使用了javaSerializerInstance。javaSerializerInstance是通过NettyRpcEnv的构造参数传入的对象,类型
*
* 3.如果反序列化得到的请求消息requestMessage中没有发送者的地址信息,则使用从TransportClient中获取的远端地址RpcAddress、
* requestMessage的接收者(即RpcEndpoint)、requestMessage的内容,以构造新的RequestMessage
* 4. 如果反序列化得到的请求消息requestMessage中含有发送者的地址信息,则将从TransportClient中获取的远端地址RpcAddress与requestMessage中的发送者地址信息之间的映射关系放入缓存remoteAddresses
* 。还将调用Dispatcher的postToAll方法,向endpoints缓存的所有EndpointData的Inbox中放入RemoteProcessConnected消息。最后将返回requestMessage
* @param client
* @param message
* @return
*/
private def internalReceive(client: TransportClient, message: ByteBuffer): RequestMessage = {
// 从TransportClient中获取远端地址RpcAddress。
val addr = client.getChannel().remoteAddress().asInstanceOf[InetSocketAddress]
assert(addr != null)
val clientAddr = RpcAddress(addr.getHostString, addr.getPort)
val requestMessage = RequestMessage(nettyEnv, client, message)
if (requestMessage.senderAddress == null) {
// Create a new message with the socket address of the client as the sender.
new RequestMessage(clientAddr, requestMessage.receiver, requestMessage.content)
} else {
// The remote RpcEnv listens to some port, we should also fire a RemoteProcessConnected for
// the listening address
val remoteEnvAddress = requestMessage.senderAddress
if (remoteAddresses.putIfAbsent(clientAddr, remoteEnvAddress) == null) {
dispatcher.postToAll(RemoteProcessConnected(remoteEnvAddress))
}
requestMessage
}
}
......
}
这里方法receive(),会调用dispatch的方法,看见名字我们就知道是发送请求的,这里先不分析,现在只是初始化,这些方法还没有到调用的时候。我们等到调用到在进行分析,我们往回走,看创建TransportContext
TransportContext
将上面刚创建的NettyRpcHandler传进去
/*
TransportContext: 传输服务的上下文对象
* TransportClientFactory: RPC客户端的工厂类
* TransportServer: RPC服务端的实现
*/
public class TransportContext {
private static final Logger logger = LoggerFactory.getLogger(TransportContext.class);
// 传输上下文的配置对象(创建TransportClientFactory和TransportServer时都需要的)
private final TransportConf conf;
// 对客户端请求消息进行处理(只用于创建TransportServer 服务端对象)
private final RpcHandler rpcHandler;
private final boolean closeIdleConnections;
/**
* Force to create MessageEncoder and MessageDecoder so that we can make sure they will be created
* before switching the current context class loader to ExecutorClassLoader.
*
* Netty's MessageToMessageEncoder uses Javassist to generate a matcher class and the
* implementation calls "Class.forName" to check if this calls is already generated. If the
* following two objects are created in "ExecutorClassLoader.findClass", it will cause
* "ClassCircularityError". This is because loading this Netty generated class will call
* "ExecutorClassLoader.findClass" to search this class, and "ExecutorClassLoader" will try to use
* RPC to load it and cause to load the non-exist matcher class again. JVM will report
* `ClassCircularityError` to prevent such infinite recursion. (See SPARK-17714)
*/
// 在消息放到channel前,先对消息内容进行编码,防止管道另一端读取时粘包和解析错误(提前定义传输协议)
private static final MessageEncoder ENCODER = MessageEncoder.INSTANCE;
// 对从channel中读取的ByteBuf进行拆包,防止粘包和解析错误
private static final MessageDecoder DECODER = MessageDecoder.INSTANCE;
public TransportContext(TransportConf conf, RpcHandler rpcHandler) {
this(conf, rpcHandler, false);
}
public TransportContext(
TransportConf conf,
RpcHandler rpcHandler,
boolean closeIdleConnections) {
this.conf = conf;
this.rpcHandler = rpcHandler;
this.closeIdleConnections = closeIdleConnections;
}
......
}
然后我们继续往下走,刚创建的transportContext直接调用createClientFactory(),并且传入了刚创建的客户端引导程序,
TransportClientFactory
创建传输客户端工厂TransportClientFactory是NettyRpcEnv向远端服务发起请求的基础,并且Spark与远端RpcEnv进行通信都依赖于TransportClientFactory生产的TransportClient
/
* 传输服务的客户端的工厂对象
*/
public class TransportClientFactory implements Closeable {
/** A simple data structure to track the pool of clients between two peer nodes. */
/**
* ClientPool实际是由TransportClient的数组构成,通过对每个TransportClient分别采用不同的锁,降低并发情况下线程间对锁的争用,进而减少阻塞,提高并发度。
*/
private static class ClientPool {
TransportClient[] clients;
Object[] locks;
ClientPool(int size) {
clients = new TransportClient[size];
locks = new Object[size];
// 每个object与client按照数组索引一一对应
for (int i = 0; i < size; i++) {
locks[i] = new Object();
}
}
}
private static final Logger logger = LoggerFactory.getLogger(TransportClientFactory.class);
private final TransportContext context;
private final TransportConf conf;
// 客户端的引导程序列表
private final List<TransportClientBootstrap> clientBootstraps;
// 针对每个socket地址的连接池ClientPool
private final ConcurrentHashMap<SocketAddress, ClientPool> connectionPool;
/** Random number generator for picking connections between peers. */
private final Random rand;
private final int numConnectionsPerPeer;
private final Class<? extends Channel> socketChannelClass;
private EventLoopGroup workerGroup;
private PooledByteBufAllocator pooledAllocator;
private final NettyMemoryMetrics metrics;
public TransportClientFactory(
TransportContext context,
List<TransportClientBootstrap> clientBootstraps) {
this.context = Preconditions.checkNotNull(context);
// 这里通过调用TransportContext的getConf获取。
this.conf = context.getConf();
// 参数传递的TransportClientBootstrap列表
this.clientBootstraps = Lists.newArrayList(Preconditions.checkNotNull(clientBootstraps));
// 针对每个socket地址的连接池ClientPool的缓存
this.connectionPool = new ConcurrentHashMap<>();
// 从TransportConf获 取 的key为“spark.+模 块名+.io.num-ConnectionsPerPeer”的属性
// Spark的很多组件都利用RPC框架构建,它们之间按照模块名区分,例如,RPC模块的key为“spark.rpc.io.num ConnectionsPerPeer”。
this.numConnectionsPerPeer = conf.numConnectionsPerPeer();
// 对Socket地址对应的连接池ClientPool中缓存的TransportClient进行随机选择,对每个连接做负载均衡
this.rand = new Random();
// IO模式,即从TransportConf获取key为“spark.+模块名+.io.mode”的属性值。默认值为NIO, Spark还支持EPOLL。
IOMode ioMode = IOMode.valueOf(conf.ioMode());
// 客户端Channel被创建时使用的类,通过ioMode来匹配,默认为NioSocketChannel, Spark还支持EpollEventLoopGroup。
this.socketChannelClass = NettyUtils.getClientChannelClass(ioMode);
// 根据Netty的规范,客户端只有worker组,所以此处创建worker-Group。workerGroup的实际类型是NioEventLoopGroup。
this.workerGroup = NettyUtils.createEventLoop(
ioMode,
conf.clientThreads(),
conf.getModuleName() + "-client");
this.pooledAllocator = NettyUtils.createPooledByteBufAllocator(
conf.preferDirectBufs(), false /* allowCache */, conf.clientThreads());
this.metrics = new NettyMemoryMetrics(
this.pooledAllocator, conf.getModuleName() + "-client", conf);
}
......
}
我们看一下ClientPool的设计

我们接着往下走,这里声明了一个TransportClientFactory,名字为fileDownloadFactoryn用于文件下载,因为有些RpcEnv本身并不需要从远端下载文件,所以这里只声明了变量fileDownloadFactory,并未进一步对其初始化。
需要下载文件的RpcEnv会调用downloadClient方法创建TransportClientFactory, 并用此TransportClientFactory创建下载所需的传输客户端TransportClient。
接着往下走
/**
* 当TransportClient发出请求之后,会等待获取服务端的回复,这就涉及超时问题。另外由于TransportClientFactory.createClient方法是阻塞式调用,所以需要一个异步的处理
*
* 用于处理请求超时的调度器。timeoutScheduler的类型实际是ScheduledExecutorService,
* 比起使用Timer组件,ScheduledExecutorService将比Timer更加稳定,
* 比如线程挂掉后,ScheduledExecutorService会重启一个新的线程定时检查请求是否超时
*
* 在NettyRpcEnv.ask()方法时使用到
*/
val timeoutScheduler = ThreadUtils.newDaemonSingleThreadScheduledExecutor("netty-rpc-env-timeout")
我们接着往下走,
/**
* 一个用于异步处理TransportClientFactory.createClient方法调用的线程池。这个线程池的大小默认为64,可以使用spark.rpc.connect.threads属性进行配置
* 在Outbox.launchConnectTask()中有使用
*/
private[netty] val clientConnectionExecutor = ThreadUtils.newDaemonCachedThreadPool(
"netty-rpc-connection",
conf.getInt("spark.rpc.connect.threads", 64))
接着往下走
/**
* NettyRpcEnv不应该只具有向远端服务发起请求并接收响应的能力,也应当对外提供接收请求、处理请求、回复客户端的服务。
*/
@volatile private var server: TransportServer = _
这里只是声明,并没有进行初始化,等到初始化我们在讲,接着往下走,
private val stopped = new AtomicBoolean(false)
/**
* A map for [[RpcAddress]] and [[Outbox]]. When we are connecting to a remote [[RpcAddress]],
* we just put messages to its [[Outbox]] to implement a non-blocking `send` method.
*
* RpcAddress与Outbox的映射关系的缓存。每次向远端发送请求时,此请求消息首先放入此远端地址对应的Outbox,然后使用线程异步发送。
*/
private val outboxes = new ConcurrentHashMap[RpcAddress, Outbox]()
到这里,NettyRpcEnv基本创建完成了,但是还没有使用,我们回到前面的代码,继续往下走
/**
* 创建NettyRpcEnv。创建NettyRpcEnv其实就是对内部各个子组件TransportConf、Dispatcher、TransportContext、TransportClientFactory、TransportServer的实例化过程
*/
val nettyEnv =
new NettyRpcEnv(sparkConf, javaSerializerInstance, config.advertiseAddress,
config.securityManager, config.numUsableCores)
if (!config.clientMode) {
// 启动NettyRpc环境
val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort =>
/**
* 启动服务
* 1. dispatcher 服务启动的时候,会直接启动一个线程,不断取receivers队列里面的数据
* 2.TransportServer 数据传输服务。init初始化方法会创建一个TransportChannelHandler,
* 内部的channelReader方法。最终会调用dispatcher的postRemoteMessage方法,往队列中添加数据
*/
nettyEnv.startServer(config.bindAddress, actualPort)
(nettyEnv, nettyEnv.address.port)
}
try {
// startServiceOnPort实际上是调用了作为参数的偏函数startNettyRpcEnv
Utils.startServiceOnPort(config.port, startNettyRpcEnv, sparkConf, config.name)._1
} catch {
case NonFatal(e) =>
nettyEnv.shutdown()
throw e
}
}
nettyEnv
}
这里拿到刚才创建的nettyEnv,直接调用他的startServer方法,
/**
* 1. 创建TransportServer。这里使用了TransportContext的createServer方法
* 2. 向Dispatcher注册RpcEndpointVerifier。RpcEndpointVerifier用于校验指定名称的RpcEndpoint是否存在。
* RpcEndpointVerifier在Dispatcher中的注册名为endpoint-verifier
* 3. TransportServer初始化并且启动后,就可以利用NettyRpcHandler和NettyStreamManager对外提供服务了
* @param bindAddress
* @param port
*/
def startServer(bindAddress: String, port: Int): Unit = {
val bootstraps: java.util.List[TransportServerBootstrap] =
if (securityManager.isAuthenticationEnabled()) {
java.util.Arrays.asList(new AuthServerBootstrap(transportConf, securityManager))
} else {
java.util.Collections.emptyList()
}
// 创建传输服务
server = transportContext.createServer(bindAddress, port, bootstraps)
// 注册RPC端点服务
dispatcher.registerRpcEndpoint(
RpcEndpointVerifier.NAME, new RpcEndpointVerifier(this, dispatcher))
}
上面声明的TransportServer,并没有进行初始化,这里进行初始化,我们直接进去createServer(),传入RpcHandler
// 创建服务端对象
public TransportServer createServer(
String host, int port, List<TransportServerBootstrap> bootstraps) {
return new TransportServer(this, host, port, rpcHandler, bootstraps);
}
/**
* Server for the efficient, low-level streaming service.
*
* https://www.jianshu.com/p/845912b39580 netty Socket实例
* 传输服务的服务端对象
*
* 一个 RPC 端点一个 TransportServer,接受远程消息后调用 Dispatcher 分发消息至对应收发件箱。
*/
public class TransportServer implements Closeable {
private static final Logger logger = LoggerFactory.getLogger(TransportServer.class);
private final TransportContext context;
private final TransportConf conf;
private final RpcHandler appRpcHandler;
private final List<TransportServerBootstrap> bootstraps;
private ServerBootstrap bootstrap;
private ChannelFuture channelFuture;
private int port = -1;
private NettyMemoryMetrics metrics;
/**
* Creates a TransportServer that binds to the given host and the given port, or to any available
* if 0. If you don't want to bind to any special host, set "hostToBind" to null.
* */
public TransportServer(
TransportContext context,
String hostToBind,
int portToBind,
RpcHandler appRpcHandler,
List<TransportServerBootstrap> bootstraps) {
this.context = context;
this.conf = context.getConf();
// RPC请求处理器RpcHandler。
this.appRpcHandler = appRpcHandler;
// 参数传递的TransportServerBootstrap列表。
this.bootstraps = Lists.newArrayList(Preconditions.checkNotNull(bootstraps));
try {
// 对TransportServer进行初始化
init(hostToBind, portToBind);
} catch (RuntimeException e) {
JavaUtils.closeQuietly(this);
throw e;
}
}
public int getPort() {
if (port == -1) {
throw new IllegalStateException("Server not initialized");
}
return port;
}
/**
* 初始化Server
* 1. 创建bossGroup和workerGroup。
* 2. 创建一个分配器
* 3. 调用Netty的API创建Netty的服务端根引导程序并对其进行配置。
* 4. 为根引导程序设置channel初始化回调函数,此回调函数首先设置TransportServer-Bootstrap到根引导程序中,然后调用TransportContext的initializePipeline方法初始化Channel的pipeline
* 5. 给根引导程序绑定Socket的监听端口,最后返回监听的端口。
* @param hostToBind
* @param portToBind
*/
private void init(String hostToBind, int portToBind) {
IOMode ioMode = IOMode.valueOf(conf.ioMode());
// Netty服务端需要同时创建bossGroup和workerGroup
EventLoopGroup bossGroup =
NettyUtils.createEventLoop(ioMode, conf.serverThreads(), conf.getModuleName() + "-server");
EventLoopGroup workerGroup = bossGroup;
PooledByteBufAllocator allocator = NettyUtils.createPooledByteBufAllocator(
conf.preferDirectBufs(), true /* allowCache */, conf.serverThreads());
// 创建Netty的服务端根引导程序并对其进行配置
bootstrap = new ServerBootstrap()
.group(bossGroup, workerGroup)
.channel(NettyUtils.getServerChannelClass(ioMode))
.option(ChannelOption.ALLOCATOR, allocator)
.childOption(ChannelOption.ALLOCATOR, allocator);
this.metrics = new NettyMemoryMetrics(
allocator, conf.getModuleName() + "-server", conf);
if (conf.backLog() > 0) {
bootstrap.option(ChannelOption.SO_BACKLOG, conf.backLog());
}
if (conf.receiveBuf() > 0) {
bootstrap.childOption(ChannelOption.SO_RCVBUF, conf.receiveBuf());
}
if (conf.sendBuf() > 0) {
bootstrap.childOption(ChannelOption.SO_SNDBUF, conf.sendBuf());
}
// 为根引导程序设置channel初始化回调函数
bootstrap.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) {
RpcHandler rpcHandler = appRpcHandler;
for (TransportServerBootstrap bootstrap : bootstraps) {
rpcHandler = bootstrap.doBootstrap(ch, rpcHandler);
}
context.initializePipeline(ch, rpcHandler);
}
});
// 给根引导程序绑定socket的监听端口
InetSocketAddress address = hostToBind == null ?
new InetSocketAddress(portToBind): new InetSocketAddress(hostToBind, portToBind);
// 绑定端口
channelFuture = bootstrap.bind(address);
channelFuture.syncUninterruptibly();
port = ((InetSocketAddress) channelFuture.channel().localAddress()).getPort();
logger.debug("Shuffle server started on port: {}", port);
}
上文都是一些Netty的API操作,我们看一下,为根引导程序设置channel初始化回调函数,里面的initializePipeline()方法
*
* 初始化TransportChannelHandler
* 创建TransportClient和TransportServer初始化的实现中,都在channel初始化回调函数中调用了TransportContext的initializePipeline方法,
*
*/
public TransportChannelHandler initializePipeline(
SocketChannel channel,
RpcHandler channelRpcHandler) {
try {
// createChannelHandler(),真正创建TransportClient是在这个方法里面
// Netty框架使用工作链模式来对每个ChannelInboundHandler的实现类的channelRead方法进行链式调用
TransportChannelHandler channelHandler = createChannelHandler(channel, channelRpcHandler);
channel.pipeline()
// 编码
.addLast("encoder", ENCODER)
// TransportFrameDecoder 对从channel中读取的ByteBuf按照数据帧进行解析
//
.addLast(TransportFrameDecoder.HANDLER_NAME, NettyUtils.createFrameDecoder())
// 解码
.addLast("decoder", DECODER)
.addLast("idleStateHandler", new IdleStateHandler(0, 0, conf.connectionTimeoutMs() / 1000))
// NOTE: Chunks are currently guaranteed to be returned in the order of request, but this
// would require more logic to guarantee if this were not part of the same event loop.
// 添加处理handler,核心处理方法 channelReader
.addLast("handler", channelHandler);
return channelHandler;
} catch (RuntimeException e) {
logger.error("Error while initializing Netty pipeline", e);
throw e;
}
}
我们看一下createChannelHandler()方法是怎么创建TransportChannelHandler的
/*
* 创建channelHandler
*/
private TransportChannelHandler createChannelHandler(Channel channel, RpcHandler rpcHandler) {
// 用于处理服务端的响应,并且对发出请求的客户端进行响应的处理程序。
TransportResponseHandler responseHandler = new TransportResponseHandler(channel);
// 直接new创建 根据 OutBox 消息的 receiver 信息,请求对应远程 TransportServer
TransportClient client = new TransportClient(channel, responseHandler);
TransportRequestHandler requestHandler = new TransportRequestHandler(channel, client,
rpcHandler, conf.maxChunksBeingTransferred());
/**
* Transport-Client只使用了TransportResponseHandler。
* TransportChannelHandler在服务端将代理Transport-RequestHandler对请求消息进行处理,并在客户端代理TransportResponseHandler对响应消息进行处理。
*/
return new TransportChannelHandler(client, responseHandler, requestHandler,
conf.connectionTimeoutMs(), closeIdleConnections);
}
然后进行的操作就是绑定了一些编码和解码的处理器,因为在网络传输过程中,会遇到粘包和拆包的问题,这里spark的解决方式,和业界处理粘包和拆包思路都是一致的。
// 在消息放到channel前,先对消息内容进行编码,防止管道另一端读取时粘包和解析错误(提前定义传输协议)
private static final MessageEncoder ENCODER = MessageEncoder.INSTANCE;
// 对从channel中读取的ByteBuf进行拆包,防止粘包和解析错误
private static final MessageDecoder DECODER = MessageDecoder.INSTANCE;
线程模型采用Multi-Reactors + mailbox的异步方式来处理,
Schema Declaration和序列化方面,Spark RPC默认采用Java native serialization方案,主要从兼容性和JVM平台内部组件通信,以及scala语言的融合考虑,所以不具备跨语言通信的能力,性能上也不是追求极致,目前还没有使用Kyro等更好序列化性能和数据大小的方案。
协议结构,Spark RPC采用私有的wire format如下,采用headr+payload的组织方式,header中包括整个frame的长度,message的类型,请求UUID。为解决TCP粘包和半包问题,以及组织成完整的Message的逻辑都在org.apache.spark.network.protocol.MessageEncoder中。

我们进去看一下编码器,整个类东西不多
MessageEncoder
/*
* https://www.cnblogs.com/AIPAOJIAO/p/10631551.html 粘包和拆包
*
*
*
* Spark RPC采用私有的wire format如下,采用headr+payload的组织方式,header中包括整个frame的长度,message的类型,请求UUID。为解决TCP粘包和半包问题,以及组织成完整的Message的逻辑都在这里
* (业界常用的方式,固定消息协议,固定字节大小)
*
*/
@ChannelHandler.Sharable
public final class MessageEncoder extends MessageToMessageEncoder<Message> {
private static final Logger logger = LoggerFactory.getLogger(MessageEncoder.class);
public static final MessageEncoder INSTANCE = new MessageEncoder();
private MessageEncoder() {}
/***
* Encodes a Message by invoking its encode() method. For non-data messages, we will add one
* ByteBuf to 'out' containing the total frame length, the message type, and the message itself.
* In the case of a ChunkFetchSuccess, we will also add the ManagedBuffer corresponding to the
* data to 'out', in order to enable zero-copy transfer.
*/
@Override
public void encode(ChannelHandlerContext ctx, Message in, List<Object> out) throws Exception {
Object body = null;
long bodyLength = 0;
boolean isBodyInFrame = false;
// If the message has a body, take it out to enable zero-copy transfer for the payload.
if (in.body() != null) {
try {
bodyLength = in.body().size();
body = in.body().convertToNetty();
isBodyInFrame = in.isBodyInFrame();
} catch (Exception e) {
in.body().release();
if (in instanceof AbstractResponseMessage) {
AbstractResponseMessage resp = (AbstractResponseMessage) in;
// Re-encode this message as a failure response.
String error = e.getMessage() != null ? e.getMessage() : "null";
logger.error(String.format("Error processing %s for client %s",
in, ctx.channel().remoteAddress()), e);
encode(ctx, resp.createFailureResponse(error), out);
} else {
throw e;
}
return;
}
}
Message.Type msgType = in.type();
// All messages have the frame length, message type, and message itself. The frame length
// may optionally include the length of the body data, depending on what message is being
// sent.
// 头长度
int headerLength = 8 + msgType.encodedLength() + in.encodedLength();
// 总共写多少个字节长度
long frameLength = headerLength + (isBodyInFrame ? bodyLength : 0);
// 根据头的大小分配Header的大小
ByteBuf header = ctx.alloc().heapBuffer(headerLength);
header.writeLong(frameLength);
msgType.encode(header);
// 调用每个不同请求的不同encode
in.encode(header);
assert header.writableBytes() == 0;
if (body != null) {
// We transfer ownership of the reference on in.body() to MessageWithHeader.
// This reference will be freed when MessageWithHeader.deallocate() is called.
out.add(new MessageWithHeader(in.body(), header, body, bodyLength));
} else {
out.add(header);
}
}
}
解码器
MessageDecoder
@ChannelHandler.Sharable
public final class MessageDecoder extends MessageToMessageDecoder<ByteBuf> {
private static final Logger logger = LoggerFactory.getLogger(MessageDecoder.class);
public static final MessageDecoder INSTANCE = new MessageDecoder();
private MessageDecoder() {}
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
Message.Type msgType = Message.Type.decode(in);
Message decoded = decode(msgType, in);
assert decoded.type() == msgType;
logger.trace("Received message {}: {}", msgType, decoded);
out.add(decoded);
}
private Message decode(Message.Type msgType, ByteBuf in) {
switch (msgType) {
case ChunkFetchRequest:
return ChunkFetchRequest.decode(in);
case ChunkFetchSuccess:
return ChunkFetchSuccess.decode(in);
case ChunkFetchFailure:
return ChunkFetchFailure.decode(in);
case RpcRequest:
return RpcRequest.decode(in);
case RpcResponse:
return RpcResponse.decode(in);
case RpcFailure:
return RpcFailure.decode(in);
case OneWayMessage:
return OneWayMessage.decode(in);
case StreamRequest:
return StreamRequest.decode(in);
case StreamResponse:
return StreamResponse.decode(in);
case StreamFailure:
return StreamFailure.decode(in);
default:
throw new IllegalArgumentException("Unexpected message type: " + msgType);
}
}
}
具体消息协议,是一个接口,我们看一下
/**
* 实现Encodable接口的类将可以转换到一个ByteBuf中,多个对象将被存储到预先分配的单个ByteBuf,所以这里的encodedLength用于返回转换的对象数量
*/
public interface Message extends Encodable {
/** Used to identify this request type. */
// 返回消息的类型。
Type type();
/** An optional body for the message. */
// 消息中可选的内容体
ManagedBuffer body();
/** Whether to include the body of the message in the same frame as the message. */
// 用于判断消息的主体是否包含在消息的同一帧中
boolean isBodyInFrame();
/** Preceding every serialized Message is its type, which allows us to deserialize it. */
enum Type implements Encodable {
ChunkFetchRequest(0), ChunkFetchSuccess(1), ChunkFetchFailure(2),
RpcRequest(3), RpcResponse(4), RpcFailure(5),
StreamRequest(6), StreamResponse(7), StreamFailure(8),
OneWayMessage(9), User(-1);
private final byte id;
Type(int id) {
assert id < 128 : "Cannot have more than 128 message types";
this.id = (byte) id;
}
public byte id() { return id; }
@Override public int encodedLength() { return 1; }
@Override public void encode(ByteBuf buf) { buf.writeByte(id); }
public static Type decode(ByteBuf buf) {
byte id = buf.readByte();
switch (id) {
case 0: return ChunkFetchRequest;
case 1: return ChunkFetchSuccess;
case 2: return ChunkFetchFailure;
case 3: return RpcRequest;
case 4: return RpcResponse;
case 5: return RpcFailure;
case 6: return StreamRequest;
case 7: return StreamResponse;
case 8: return StreamFailure;
case 9: return OneWayMessage;
case -1: throw new IllegalArgumentException("User type messages cannot be decoded.");
default: throw new IllegalArgumentException("Unknown message type: " + id);
}
}
}
}
使用wireshake具体分析一下。
看一个RPC请求,客户端调用分两个TCP Segment传输,这是因为Spark使用netty的时候header和body分别writeAndFlush出去。
下图是第一个TCP segment

例子中蓝色的部分是header,头中的字节解析如下:
00 00 00 00 00 00 05 d2 // 十进制1490,是整个frame的长度
03一个字节表示的是RpcRequest,枚举定义如下:
RpcRequest(3)
RpcResponse(4)
RpcFailure(5)
StreamRequest(6)
StreamResponse(7)
StreamFailure(8),
OneWayMessage(9)
User(-1
每个字节的意义如下:
4b ac a6 9f 83 5d 17 a9 // 8个字节是UUID
05 bd // 十进制1469,payload长度
具体的Payload就长下面这个样子,可以看出使用Java native serialization,一个简单的Echo请求就有1469个字节,还是很大的,序列化的效率不高。但是Spark RPC定位内部通信,不是一个通用的RPC框架,并且使用的量非常小,所以这点消耗也就可以忽略了,还有Spark Structured Streaming使用该序列化方式,其性能还是可以满足要求的。

我们往前走,接着看,将编码器和解码器和TransportChannelHandler绑定到channel之后,给根引导程序绑定socket的监听端口,然后init方法也就执行完了
总结一下 初始化server 大概5步
- 创建bossGroup和workerGroup
- 创建一个分配器
- 调用Netty的API创建Netty的服务端根引导程序并对其进行配置
- 为根引导程序设置channel初始化回调函数,此回调函数首先设置TransportServer-Bootstrap到根引导程序中,然后调用TransportContext的initializePipeline方法初始化Channel的pipeline
- 给根引导程序绑定Socket的监听端口,最后返回监听的端口。
我们往回看,createServer创建完成之后,调用registerRpcEndpoint()方法
/**
* 注册rpc端点,这个方法则可以将EndpointData放入receivers
* 1. 使用当前RpcEndpoint所在NettyRpcEnv的地址和RpcEndpoint的名称创建RpcEndpointAddress对象。
* 2. 创建RpcEndpoint的引用对象——NettyRpcEndpointRef。
* 3. 创建EndpointData,并放入endpoints缓存。
* 4. 将RpcEndpoint与NettyRpcEndpointRef的映射关系放入endpointRefs缓存。
* 5. 将EndpointData放入阻塞队列receivers的队尾。MessageLoop线程异步获取到此EndpointData,并处理其Inbox中刚刚放入的OnStart消息,
* 最终调用RpcEndpoint的OnStart方法在RpcEndpoint开始处理消息之前做一些准备工作
* 6. 返回NettyRpcEndpointRef。
* 对RpcEndpoint注册
* @param name
* @param endpoint
* @return
*/
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
val addr = RpcEndpointAddress(nettyEnv.address, name)
// 创建RpcEndpoint的引用对象
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
synchronized {
if (stopped) {
throw new IllegalStateException("RpcEnv has been stopped")
}
if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) {
throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name")
}
val data = endpoints.get(name)
endpointRefs.put(data.endpoint, data.ref)
receivers.offer(data) // for the OnStart message
}
endpointRef
}
这里直接创建了NettyRpcEndpointRef
NettyRpcEndpointRef
private[netty] class NettyRpcEndpointRef(
@transient private val conf: SparkConf,
// 远端RpcEndpoint的地址RpcEndpointAddress。
private val endpointAddress: RpcEndpointAddress,
@transient @volatile private var nettyEnv: NettyRpcEnv) extends RpcEndpointRef(conf) {
/**
* 类型为TransportClient(TransportClient)。
* Netty-RpcEndpointRef将利用此TransportClient向远端的RpcEndpoint发送请求。
*/
@transient @volatile var client: TransportClient = _
/**
* 返回_address属性的值,或返回null。
* @return
*/
override def address: RpcAddress =
if (endpointAddress.rpcAddress != null) endpointAddress.rpcAddress else null
private def readObject(in: ObjectInputStream): Unit = {
in.defaultReadObject()
nettyEnv = NettyRpcEnv.currentEnv.value
client = NettyRpcEnv.currentClient.value
}
private def writeObject(out: ObjectOutputStream): Unit = {
out.defaultWriteObject()
}
// 返回_name属性的值。
override def name: String = endpointAddress.name
/**
* 首先将message封装为Request Message,然后调用NettyRpcEnv的ask方法。
* @param message
* @param timeout
* @tparam T
* @return
*/
override def ask[T: ClassTag](message: Any, timeout: RpcTimeout): Future[T] = {
nettyEnv.ask(new RequestMessage(nettyEnv.address, this, message), timeout)
}
/**
* 首先将message封装为RequestMessage,然后调用NettyRpcEnv的send方法。
* @param message
*/
override def send(message: Any): Unit = {
require(message != null, "Message is null")
nettyEnv.send(new RequestMessage(nettyEnv.address, this, message))
}
override def toString: String = s"NettyRpcEndpointRef(${endpointAddress})"
final override def equals(that: Any): Boolean = that match {
case other: NettyRpcEndpointRef => endpointAddress == other.endpointAddress
case _ => false
}
final override def hashCode(): Int =
if (endpointAddress == null) 0 else endpointAddress.hashCode()
}
然后我们继续往下走,直接往 端点实例名称与端点数据EndpointData之间映射关系的缓存,添加进了这个注册的端点的名称数据,然后将数据放入 端点实例RpcEndpoint与端点实例引用RpcEndpointRef之间映射关系的缓存中。 最后往 存储端点数据EndpointData的阻塞队列中添加消息,最后将引用返回。整个注册流程大概是
- 使用当前RpcEndpoint所在NettyRpcEnv的地址和RpcEndpoint的名称创建RpcEndpointAddress对象。
- 创建RpcEndpoint的引用对象——NettyRpcEndpointRef。
- 创建EndpointData,并放入endpoints缓存。
4. 将RpcEndpoint与NettyRpcEndpointRef的映射关系放入endpointRefs缓存。
5. 将EndpointData放入阻塞队列receivers的队尾。MessageLoop线程异步获取到此EndpointData,并处理其Inbox中刚刚放入的OnStart消息, 最终调用RpcEndpoint的OnStart方法在RpcEndpoint开始处理消息之前做一些准备工作 - 返回NettyRpcEndpointRef。
完成 对RpcEndpoint注册
registerRpcEndpoint()方法执行完毕,不过我们这个注册方法注册的endpoint是RpcEndpointVerifier
private[netty] class RpcEndpointVerifier(override val rpcEnv: RpcEnv, dispatcher: Dispatcher)
extends RpcEndpoint {
/**
* 1. 接收CheckExistence类型的消息,匹配出name参数,此参数代表要查询的Rpc-Endpoint的具体名称。
* 2. 调用Dispatcher的verify方法。verify用于校验Dispatcher的endpoints缓存中是否存在名为name的RpcEndpoint
* 3. 调用RpcCallContext的reply方法回复客户端,true或false
* @param context
* @return
*/
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case RpcEndpointVerifier.CheckExistence(name) => context.reply(dispatcher.verify(name))
}
}
private[netty] object RpcEndpointVerifier {
val NAME = "endpoint-verifier"
/** A message used to ask the remote [[RpcEndpointVerifier]] if an `RpcEndpoint` exists. */
case class CheckExistence(name: String)
}
到此,我们回到master的main方法开始,这个时候NettyRpcEnv已经创建出来了,并且也启动了server服务,注册了一个endpoint-verifier的端点服务,接下来我们继续往下走

进到里面,发现也是注册一个端点,就是上面的registerRpcEndpoint()方法,不过这回注册是端点是master而已。
还记得上面初始化dispathcer的时候,会有一个死循环的线程池,不断循环处理receivers中的消息,我们执行完registerRpcEndpoint方法后,就会往receivers里面添加数据,我们现在去分析dispatcher的处理数据流程。
/** Message loop used for dispatching messages. */
/**
* 不断循环处理消息
* 1. 从receivers中获取EndpointData。receivers中的EndpointData,其Inbox的messages列表中肯定有了新的消息。
* 换言之,只有Inbox的messages列表中有了新的消息,此EndpointData才会被放入receivers中。
* 由于receivers是个阻塞队列,所以当receivers中没有EndpointData时,MessageLoop线程会被阻塞。
* 2. 如果取到的EndpointData是“毒药”(PoisonPill),那么此MessageLoop线程将退出(通过return语句),
* 并且会再次将PoisonPill放到队列里面,以达到所有MessageLoop线程都结束的效果。
* 3. 如果取到的EndpointData不是“毒药”,那么调用EndpointData中Inbox的process方法对消息进行处理。
*/
private class MessageLoop extends Runnable {
override def run(): Unit = {
try {
while (true) {
try {
//
val data = receivers.take()
// 如果数据为毒药
if (data == PoisonPill) {
// Put PoisonPill back so that other MessageLoops can see it.
receivers.offer(PoisonPill)
return
}
// 对消息做处理
data.inbox.process(Dispatcher.this)
} catch {
case NonFatal(e) => logError(e.getMessage, e)
}
}
} catch {
case _: InterruptedException => // exit
case t: Throwable =>
try {
// Re-submit a MessageLoop so that Dispatcher will still work if
// UncaughtExceptionHandler decides to not kill JVM.
threadpool.execute(new MessageLoop)
} finally {
throw t
}
}
}
}
我们进入Inbox的process方法
/**
* Process stored messages.
* 处理消息
* 1. 进行线程并发检查。具体是,如果不允许多个线程同时处理messages中的消息(enableConcurrent为false),
* 并且当前激活线程数(numActiveThreads)不为0,这说明已经有线程在处理消息,所以当前线程不允许再去处理消息(使用return返回)。
* 2. 从messages中获取消息。如果有消息未处理,则当前线程需要处理此消息,因而算是一个新的激活线程(需要将numActiveThreads加1)。如果messages中没有消息了(一般发生在多线程情况下),则直接返回。
* 3.根据消息类型进行匹配,并执行对应的逻辑
* 4. 对激活线程数量进行控制。当第3步对消息处理完毕后,当前线程作为之前已经激活的线程是否还有存在的必要呢?
* 这里有两个判断:
* 1. 如果不允许多个线程同时处理messages中的消息并且当前激活的线程数多于1个,那么需要当前线程退出并将numActiveThreads减1;
* 2. 如果messages已经没有消息要处理了,这说明当前线程无论如何也该返回并将numActiveThreads减1。
*/
def process(dispatcher: Dispatcher): Unit = {
var message: InboxMessage = null
inbox.synchronized {
if (!enableConcurrent && numActiveThreads != 0) {
return
}
message = messages.poll()
if (message != null) {
numActiveThreads += 1
} else {
return
}
}
while (true) {
/**
* 根据消息类型进行匹配,并执行对应的逻辑
*/
safelyCall(endpoint) {
message match {
// rpc请求的话,直接调用endpoint的receiveAndReply
case RpcMessage(_sender, content, context) =>
try {
endpoint.receiveAndReply(context).applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
})
} catch {
case e: Throwable =>
context.sendFailure(e)
// Throw the exception -- this exception will be caught by the safelyCall function.
// The endpoint's onError function will be called.
throw e
}
case OneWayMessage(_sender, content) =>
endpoint.receive.applyOrElse[Any, Unit](content, { msg =>
throw new SparkException(s"Unsupported message $message from ${_sender}")
})
case OnStart =>
endpoint.onStart()
if (!endpoint.isInstanceOf[ThreadSafeRpcEndpoint]) {
inbox.synchronized {
if (!stopped) {
enableConcurrent = true
}
}
}
case OnStop =>
val activeThreads = inbox.synchronized { inbox.numActiveThreads }
assert(activeThreads == 1,
s"There should be only a single active thread but found $activeThreads threads.")
// 删除endpointRef和endpoint的引用关系
dispatcher.removeRpcEndpointRef(endpoint)
endpoint.onStop()
assert(isEmpty, "OnStop should be the last message")
case RemoteProcessConnected(remoteAddress) =>
endpoint.onConnected(remoteAddress)
case RemoteProcessDisconnected(remoteAddress) =>
endpoint.onDisconnected(remoteAddress)
case RemoteProcessConnectionError(cause, remoteAddress) =>
endpoint.onNetworkError(cause, remoteAddress)
}
}
inbox.synchronized {
// "enableConcurrent" will be set to false after `onStop` is called, so we should check it
// every time.
if (!enableConcurrent && numActiveThreads != 1) {
// If we are not the only one worker, exit
numActiveThreads -= 1
return
}
message = messages.poll()
if (message == null) {
numActiveThreads -= 1
return
}
}
}
}
由于我们新建Inbox的时候,同步代码块会往message里面放入Onstart的消息,所以这里我们直接获取消息,然后进行模式匹配处理消息,我们找到onStart的处理逻辑,发现直接是调用了端点的onStart()方法,那我们就直接返回到Master,找到onStart()方法
这里怎么处理请求我们讲完了,如果message里面有rpc的消息,就调用相关端点的receiveAndReply方法(),这里就不多展开,下面讲怎么发送请求

这里的self方法是获取endpoint相关联的RpcEndpointRef,只有拿到ref才能去向客户端做发送请求。
/*
* 获取RpcEndpoint相关联的RpcEndpointRef。从代码实现看到
* ,其实现实际调用了RpcEnv的endpointRef方法。由于RpcEnv并未实现此方法,所以需要RpcEnv的子类来实现。
*
*/
final def self: RpcEndpointRef = {
require(rpcEnv != null, "rpcEnv has not been initialized")
rpcEnv.endpointRef(this)
}
我们看一下拿到引用后,调用NettyRpcEnv的send方法
/**
* 首先将message封装为RequestMessage,然后调用NettyRpcEnv的send方法。
* @param message
*/
override def send(message: Any): Unit = {
require(message != null, "Message is null")
nettyEnv.send(new RequestMessage(nettyEnv.address, this, message))
}
/**
* 1. 如果请求消息的接收者的地址与当前NettyRpcEnv的地址相同。那么新建Promise对象,并且给Promise的future(类型为Future)设置完成时的回调函数(成功时调用onSuccess方法,失败时调用onFailure方法)。
* 发送消息最终通过调用本地Dispatcher的postOneWayMessage方法
* 2. 如果请求消息的接收者的地址与当前NettyRpcEnv的地址不同,那么将message序列化,并与onFailure、onSuccess方法一道封装为RpcOutboxMessage类型的消息。
* 最后调用postToOutbox方法将消息投递出去
* @param message
*/
private[netty] def send(message: RequestMessage): Unit = {
val remoteAddr = message.receiver.address
if (remoteAddr == address) {
// Message to a local RPC endpoint.
try {
dispatcher.postOneWayMessage(message)
} catch {
case e: RpcEnvStoppedException => logDebug(e.getMessage)
}
} else {
// Message to a remote RPC endpoint.
postToOutbox(message.receiver,
OneWayOutboxMessage(message.serialize(this)))
}
}
我们先看一下请求消息的接收者的地址与当前NettyRpcEnv的地址相同的发送逻辑
/**
* Posts a message to a specific endpoint.
* 将消息提交给指定的RpcEndpoint
*
* 1. 根据端点名称endpointName从缓存endpoints中获取EndpointData。
* 2. 如果当前Dispatcher没有停止并且缓存endpoints中确实存在名为endpointName的EndpointData,
* 那么将调用EndpointData对应Inbox的post方法将消息加入Inbox的消息列表中,因此还需要将EndpointData推入receivers,
* 以便MessageLoop处理此Inbox中的消息。Inbox的post方法的实现其逻辑为Inbox未停止时向messages列表加入消息。
*
*
* @param endpointName name of the endpoint.
* @param message the message to post
* @param callbackIfStopped callback function if the endpoint is stopped.
*/
private def postMessage(
endpointName: String,
message: InboxMessage,
callbackIfStopped: (Exception) => Unit): Unit = {
val error = synchronized {
val data = endpoints.get(endpointName)
if (stopped) {
Some(new RpcEnvStoppedException())
} else if (data == null) {
Some(new SparkException(s"Could not find $endpointName."))
} else {
data.inbox.post(message)
receivers.offer(data)
None
}
}
// We don't need to call `onStop` in the `synchronized` block
error.foreach(callbackIfStopped)
}
这里很简单,直接将消息发送到端点服务的inbox里面,然后将数据放入receivers中,dispatcher的处理线程会去拿出消息做匹配处理。
然后我们看一下第二种情形,如果请求消息的接收者的地址与当前NettyRpcEnv的地址不同
/**
* postToOutbox用于向远端节点上的RpcEndpoint发送消息
* 1. 如果NettyRpcEndpointRef中的TransportClient不为空,则直接调用OutboxMessage的sendWith方法
* 2. 获取NettyRpcEndpointRef的远端RpcEndpoint地址所对应的Outbox。
* 首先从outboxes缓存中获取Outbox。如果outboxes中没有相应的Outbox,则需要新建Outbox并放入outboxes缓存中。
* 3. 如果当前NettyRpcEnv已经处于停止状态,则将第2步得到的Outbox从outboxes中移除,并且调用Outbox的stop方法停止Outbox。
* 如果当前NettyRpcEnv还未停止,则调用第2)步得到的Outbox的send方法发送消息。
*
*
* @param receiver
* @param message
*/
private def postToOutbox(receiver: NettyRpcEndpointRef, message: OutboxMessage): Unit = {
if (receiver.client != null) {
message.sendWith(receiver.client)
} else {
require(receiver.address != null,
"Cannot send message to client endpoint with no listen address.")
val targetOutbox = {
val outbox = outboxes.get(receiver.address)
if (outbox == null) {
// 直接新建一个Outbox
val newOutbox = new Outbox(this, receiver.address)
// 放入缓存
val oldOutbox =
outboxes.putIfAbsent(receiver.address, newOutbox)
if (oldOutbox == null) {
newOutbox
} else {
oldOutbox
}
} else {
outbox
}
}
if (stopped.get) {
// It's possible that we put `targetOutbox` after stopping. So we need to clean it.
outboxes.remove(receiver.address)
targetOutbox.stop()
} else {
targetOutbox.send(message)
}
}
}
这里我们先看一下第二种情况,因为按照我们分析的代码执行的先后顺序的话,程序执行到这里,还是没有创建TransportClient,之前我们看到的是server已经创建的,先创建一个Outbox,然后将消息放到RpcAddress与Outbox的映射关系的缓存中
然后我们继续往下走,如果当前NettyRpcEnv没有停止,直接调用远端的OutBox的send方法
/**
* Send a message. If there is no active connection, cache it and launch a new connection. If
* [[Outbox]] is stopped, the sender will be notified with a [[SparkException]].
* 1. 判断当前Outbox的状态是否已经停止。
* 2. 如果Outbox已经停止,则向发送者发送SparkException异常。
* 如果Outbox还未停止,则将OutboxMessage添加到messages列表中,并且调用drainOutbox方法处理messages中的消息。drainOutbox是一个私有方法
*
*
*/
def send(message: OutboxMessage): Unit = {
val dropped = synchronized {
if (stopped) {
true
} else {
messages.add(message)
false
}
}
if (dropped) {
message.onFailure(new SparkException("Message is dropped because Outbox is stopped"))
} else {
drainOutbox()
}
}
先将消息添加到 其他远端NettyRpcEnv上的所有RpcEndpoint发送的消息列表messages中, 然后调用drainOutbox()去处理messages中的消息
/**
* Drain the message queue. If there is other draining thread, just exit. If the connection has
* not been established, launch a task in the `nettyEnv.clientConnectionExecutor` to setup the
* connection.
*
* 处理消息
*
* 1. 如果当前Outbox已经停止或者正在连接远端服务,则返回。
* 2. 如果Outbox中的TransportClient为null,这说明还未连接远端服务。此时需要调用launchConnectTask方法运行连接远端服务的任务,然后返回
* 3. 如果正有线程在处理(即发送)messages列表中的消息,则返回。
* 4. 如果messages列表中没有消息要处理,则返回。否则取出其中的一条消息,并将draining状态置为true
* 5. 循环处理messages列表中的消息,即不断从messages列表中取出消息并调用OutboxMessage的sendWith方法发送消息。
*/
private def drainOutbox(): Unit = {
var message: OutboxMessage = null
synchronized {
if (stopped) {
return
}
if (connectFuture != null) {
// We are connecting to the remote address, so just exit
return
}
if (client == null) {
// There is no connect task but client is null, so we need to launch the connect task.
launchConnectTask()
return
}
if (draining) {
// There is some thread draining, so just exit
return
}
message = messages.poll()
if (message == null) {
return
}
draining = true
}
while (true) {
try {
val _client = synchronized { client }
if (_client != null) {
message.sendWith(_client)
} else {
assert(stopped == true)
}
} catch {
case NonFatal(e) =>
handleNetworkFailure(e)
return
}
synchronized {
if (stopped) {
return
}
message = messages.poll()
if (message == null) {
draining = false
return
}
}
}
}
我们这里client是为空的,所以直接调用launchConnectTask()方法
/**
* 运行连接远端服务的任务
*
* 1. 构造Callable的匿名内部类,此匿名类将调用NettyRpcEnv的createClient方法创建TransportClient,
* 然后调用drainOutbox方法处理Outbox中的消息。
* 2. 使用NettyRpcEnv中的clientConnectionExecutor提交Callable的匿名内部类。
*/
private def launchConnectTask(): Unit = {
connectFuture = nettyEnv.clientConnectionExecutor.submit(new Callable[Unit] {
override def call(): Unit = {
try {
val _client = nettyEnv.createClient(address)
outbox.synchronized {
client = _client
if (stopped) {
closeClient()
}
}
} catch {
case ie: InterruptedException =>
// exit
return
case NonFatal(e) =>
outbox.synchronized { connectFuture = null }
handleNetworkFailure(e)
return
}
outbox.synchronized { connectFuture = null }
// It's possible that no thread is draining now. If we don't drain here, we cannot send the
// messages until the next message arrives.
drainOutbox()
}
})
}
之前dispatcher创建的客户端连接线程池这里用到了,然后我们直接看createClient()方法
private[netty] def createClient(address: RpcAddress): TransportClient = {
clientFactory.createClient(address.host, address.port)
}
直接调用TransportClientFactory的createClient(),我们进去看一下
/ *
* 每个TransportClient实例只能和一个远端的RPC服务通信,所以Spark中的组件如果想要和多个RPC服务通信,就需要持有多个TransportClient实例,
* 实际是从缓存中获取TransportClient,如果缓存中没有,在创建
*
* 虚假的创建步骤
* 1. 调用InetSocketAddress的静态方法createUnresolved构建InetSocketAddress
* 然后从connectionPool中获取与此地址对应的ClientPool,如果没有,则需要新建ClientPool,并放入缓存connectionPool中
* 2. 根据numConnectionsPerPeer的大小(使用“spark.+模块名+.io.numConnections-PerPeer”属性配置),从ClientPool中随机选择一个TransportClient
* 3. 如果ClientPool的clients数组中在随机产生的索引位置不存在TransportClient或者TransportClient没有激活,则进入第5步,否则对此TransportClient进行第4步的检查
* 4. 更新TransportClient的channel中配置的TransportChannelHandler的最后一次使用时间,确保channel没有超时,然后检查TransportClient是否是激活状态,最后返回此TransportClient给调用方。
* 5. 由于缓存中没有TransportClient可用,于是调用InetSocketAddress的构造器创建InetSocketAddress对象
* 在这一步骤多个线程可能会产生竞争条件(由于没有同步处理,所以多个线程极有可能同时执行到此处,都发现缓存中没有TransportClient可用,于是都使用InetSocketAddress的构造器创建InetSocketAddress),会创建多个。
* 6. 按照随机产生的数组索引,locks数组中的锁对象可以对clients数组中的TransportClient一对一进行同步。
* 即便之前产生了竞争条件,但是在这一步只能有一个线程进入。先进入的线程调用重载的createClient方法创建TransportClient对象并放入ClientPool的clients数组中。当率先进入的线程退出后,其他线程才能进入,
* 此时发现ClientPool的clients数组中已经存在了TransportClient对象,那么将不再创建TransportClient,直接获取
*
*/
public TransportClient createClient(String remoteHost, int remotePort)
throws IOException, InterruptedException {
// Get connection from the connection pool first.
// If it is not found or not active, create a new one.
// Use unresolved address here to avoid DNS resolution each time we creates a client.
// 创建InetSocketAddress,传入主机和端口
final InetSocketAddress unresolvedAddress =
InetSocketAddress.createUnresolved(remoteHost, remotePort);
// Create the ClientPool if we don't have it yet.
ClientPool clientPool = connectionPool.get(unresolvedAddress);
if (clientPool == null) {
connectionPool.putIfAbsent(unresolvedAddress, new ClientPool(numConnectionsPerPeer));
clientPool = connectionPool.get(unresolvedAddress);
}
// 随机选择一个TransportClient
int clientIndex = rand.nextInt(numConnectionsPerPeer);
TransportClient cachedClient = clientPool.clients[clientIndex];
// 进行判空和激活检查
if (cachedClient != null && cachedClient.isActive()) {
// Make sure that the channel will not timeout by updating the last use time of the
// handler. Then check that the client is still alive, in case it timed out before
// this code was able to update things.
TransportChannelHandler handler = cachedClient.getChannel().pipeline()
.get(TransportChannelHandler.class);
synchronized (handler) {
// 确保channel没有超时
handler.getResponseHandler().updateTimeOfLastRequest();
}
// 获取并返回激活的
if (cachedClient.isActive()) {
logger.trace("Returning cached connection to {}: {}",
cachedClient.getSocketAddress(), cachedClient);
return cachedClient;
}
}
// If we reach here, we don't have an existing connection open. Let's create a new one.
// Multiple threads might race here to create new connections. Keep only one of them active.
final long preResolveHost = System.nanoTime();
final InetSocketAddress resolvedAddress = new InetSocketAddress(remoteHost, remotePort);
final long hostResolveTimeMs = (System.nanoTime() - preResolveHost) / 1000000;
if (hostResolveTimeMs > 2000) {
logger.warn("DNS resolution for {} took {} ms", resolvedAddress, hostResolveTimeMs);
} else {
logger.trace("DNS resolution for {} took {} ms", resolvedAddress, hostResolveTimeMs);
}
// 锁控制
synchronized (clientPool.locks[clientIndex]) {
cachedClient = clientPool.clients[clientIndex];
// 如果已有,并且是激活的,那么直接获取
if (cachedClient != null) {
if (cachedClient.isActive()) {
logger.trace("Returning cached connection to {}: {}", resolvedAddress, cachedClient);
return cachedClient;
} else {
logger.info("Found inactive connection to {}, creating a new one.", resolvedAddress);
}
}
// 创建TransportClient(会激活)
clientPool.clients[clientIndex] = createClient(resolvedAddress);
// 直接返回
return clientPool.clients[clientIndex];
}
}
我们见一下真正创建Client的方法
/** Create a completely new {@link TransportClient} to the remote address. */
/**
* 每个TransportClient实例只能和一个远端的RPC服务通信,所以Spark中的组件如果想要和多个RPC服务通信,就需要持有多个TransportClient实例
*
* 真正的创建步骤
* 1. 创建根引导程序Bootstrap并对其进行配置。
* 2. 为根引导程序设置管道初始化回调函数,此回调函数将调用TransportContext的initializePipeline方法初始化Channel的pipeline。
* 3. 使用根引导程序连接远程服务器,当连接成功对管道初始化时会回调初始化回调函数,将TransportClient和Channel对象分别设置到原子引用clientRef与channelRef中。
* 4. 给TransportClient设置客户端引导程序,即设置TransportClientFactory中的Transport-ClientBootstrap列表。
* 5. 返回此TransportClient对象。
*
* @param address
* @return
* @throws IOException
* @throws InterruptedException
*/
private TransportClient createClient(InetSocketAddress address)
throws IOException, InterruptedException {
logger.debug("Creating new connection to {}", address);
// 创建根引导程序Bootstrap并对其进行配置
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(workerGroup)
.channel(socketChannelClass)
// Disable Nagle's Algorithm since we don't want packets to wait
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, conf.connectionTimeoutMs())
.option(ChannelOption.ALLOCATOR, pooledAllocator);
if (conf.receiveBuf() > 0) {
bootstrap.option(ChannelOption.SO_RCVBUF, conf.receiveBuf());
}
if (conf.sendBuf() > 0) {
bootstrap.option(ChannelOption.SO_SNDBUF, conf.sendBuf());
}
final AtomicReference<TransportClient> clientRef = new AtomicReference<>();
final AtomicReference<Channel> channelRef = new AtomicReference<>();
// 为跟引导程序设置channel初始化回调函数
bootstrap.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
TransportChannelHandler clientHandler = context.initializePipeline(ch);
// 将TransportClient和Channel对象分别设置到clientRef与channelRef中。
clientRef.set(clientHandler.getClient());
channelRef.set(ch);
}
});
// Connect to the remote server
long preConnect = System.nanoTime();
// 使用根引导程序连接远程服务器
ChannelFuture cf = bootstrap.connect(address);
if (!cf.await(conf.connectionTimeoutMs())) {
throw new IOException(
String.format("Connecting to %s timed out (%s ms)", address, conf.connectionTimeoutMs()));
} else if (cf.cause() != null) {
throw new IOException(String.format("Failed to connect to %s", address), cf.cause());
}
TransportClient client = clientRef.get();
Channel channel = channelRef.get();
assert client != null : "Channel future completed successfully with null client";
// Execute any client bootstraps synchronously before marking the Client as successful.
long preBootstrap = System.nanoTime();
logger.debug("Connection to {} successful, running bootstraps...", address);
try {
for (TransportClientBootstrap clientBootstrap : clientBootstraps) {
// 设置客户端引导程序
clientBootstrap.doBootstrap(client, channel);
}
} catch (Exception e) { // catch non-RuntimeExceptions too as bootstrap may be written in Scala
long bootstrapTimeMs = (System.nanoTime() - preBootstrap) / 1000000;
logger.error("Exception while bootstrapping client after " + bootstrapTimeMs + " ms", e);
client.close();
throw Throwables.propagate(e);
}
long postBootstrap = System.nanoTime();
logger.info("Successfully created connection to {} after {} ms ({} ms spent in bootstraps)",
address, (postBootstrap - preConnect) / 1000000, (postBootstrap - preBootstrap) / 1000000);
// 直接返回对象
return client;
}
这里为跟引导程序设置channel初始化回调函数的方法中,initializePipeline方法和服务端执行的是一致的,上文已经分析过,也是绑定一些处理器,然后执行完initializePipeline方法之后, 又将TransportClient和Channel对象分别设置到clientRef与channelRef中。
这个时候,我们前文的endpointRef的endpointClient就已经有了,不为空了,我们返回继续往下走。
launchConnectTask()方法中,创建完client之后,会调用drainOutbox()方法,我们进去分析一下
*
* 处理消息
*
* 1. 如果当前Outbox已经停止或者正在连接远端服务,则返回。
* 2. 如果Outbox中的TransportClient为null,这说明还未连接远端服务。此时需要调用launchConnectTask方法运行连接远端服务的任务,然后返回
* 3. 如果正有线程在处理(即发送)messages列表中的消息,则返回。
* 4. 如果messages列表中没有消息要处理,则返回。否则取出其中的一条消息,并将draining状态置为true
* 5. 循环处理messages列表中的消息,即不断从messages列表中取出消息并调用OutboxMessage的sendWith方法发送消息。
*/
private def drainOutbox(): Unit = {
var message: OutboxMessage = null
synchronized {
if (stopped) {
return
}
if (connectFuture != null) {
// We are connecting to the remote address, so just exit
return
}
if (client == null) {
// There is no connect task but client is null, so we need to launch the connect task.
launchConnectTask()
return
}
if (draining) {
// There is some thread draining, so just exit
return
}
message = messages.poll()
if (message == null) {
return
}
draining = true
}
while (true) {
try {
val _client = synchronized { client }
if (_client != null) {
message.sendWith(_client)
} else {
assert(stopped == true)
}
} catch {
case NonFatal(e) =>
handleNetworkFailure(e)
return
}
synchronized {
if (stopped) {
return
}
message = messages.poll()
if (message == null) {
draining = false
return
}
}
}
}
按照代码的处理逻辑,最后会调用OutboxMessage的sendWith方法,我们这里以发送RpcOutboxMessage为例,最终会调用Client的sendRpc()方法
* 向服务端发送RPC的请求,通过At least Once Delivery原则保证请求不会丢失。
*
* 1. 使用UUID生成请求主键requestId
* 2. 调用addRpcRequest向handler添加requestId与回调类RpcResponseCallback的引用之间的关系。TransportResponseHandler的addRpcRequest方法
* 3. 调用Channel的writeAndFlush方法将RPC请求发送出去,这和在服务端调用的respond方法响应客户端的一样,都是使用channel的writeAndFlush方法
*/
public long sendRpc(ByteBuffer message, RpcResponseCallback callback) {
long startTime = System.currentTimeMillis();
if (logger.isTraceEnabled()) {
logger.trace("Sending RPC to {}", getRemoteAddress(channel));
}
// 使用UUID生成请求主键requestId
long requestId = Math.abs(UUID.randomUUID().getLeastSignificantBits());
// 添加requestId与RpcResponseCallback的引用关系
handler.addRpcRequest(requestId, callback);
// 发送RPC请求
channel.writeAndFlush(new RpcRequest(requestId, new NioManagedBuffer(message)))
.addListener(future -> {
// 如果发送成功,打印requestId,远端地址以及花费的时间
if (future.isSuccess()) {
long timeTaken = System.currentTimeMillis() - startTime;
if (logger.isTraceEnabled()) {
logger.trace("Sending request {} to {} took {} ms", requestId,
getRemoteAddress(channel), timeTaken);
}
} else {
// 如果发送失败,除了打印错误日志外,还要调用TransportResponseHandler的removeRpcRequest方法。将此次请求从outstandingRpcs缓存中移除。
String errorMsg = String.format("Failed to send RPC %s to %s: %s", requestId,
getRemoteAddress(channel), future.cause());
logger.error(errorMsg, future.cause());
handler.removeRpcRequest(requestId);
channel.close();
try {
callback.onFailure(new IOException(errorMsg, future.cause()));
} catch (Exception e) {
logger.error("Uncaught exception in RPC response callback handler!", e);
}
}
});
return requestId;
}
这里是调用Netty的API进行消息发送,按照Netty框架来讲,最终消息会发送到之前服务端绑定的channel中,使用TransportChannelHandler的channelRead()方法来接收处理消息。这个方法是实现ChannelInboundHandler的类都要实现这个方法
不知道的可以看一下这个文章介绍的Netty基本使用
https://blog.csdn.net/qq_26323323/article/details/84226845/
/**
* 核心方法,实现ChannelInboundHandler的类都要实现这个方法
* @param ctx
* @param request
* @throws Exception
*/
@Override
public void channelRead(ChannelHandlerContext ctx, Object request) throws Exception {
// 如果请求是RequestMessage,则将此消息的处理进一步交给TransportRequestHandler,
if (request instanceof RequestMessage) {
requestHandler.handle((RequestMessage) request);
// 当读取的request是ResponseMessage时,则将此消息的处理进一步交给TransportResponseHandler
} else if (request instanceof ResponseMessage) {
responseHandler.handle((ResponseMessage) request);
} else {
ctx.fireChannelRead(request);
}
}
我们刚才发送的是RequestMessage请求,我们先看这个,所以这里将消息交给了TransportRequestHandler,并且调用他的handler方法。
/**
* 除了processOneWayMessage消息外
* 其他的消息都是最终调用respond方法响应客户端
* @param request
*/
@Override
public void handle(RequestMessage request) {
if (request instanceof ChunkFetchRequest) {
// 处理块儿请求
processFetchRequest((ChunkFetchRequest) request);
} else if (request instanceof RpcRequest) {
// 处理RPC请求
processRpcRequest((RpcRequest) request);
} else if (request instanceof OneWayMessage) {
// 处理无需回复的RPC请求
processOneWayMessage((OneWayMessage) request);
} else if (request instanceof StreamRequest) {
// 处理流请求
processStreamRequest((StreamRequest) request);
} else {
throw new IllegalArgumentException("Unknown request type: " + request);
}
}
总共4种请求,我们找Rpc请求看一下
private void processRpcRequest(final RpcRequest req) {
try {
//将RpcRequest消息的发送消息的客户端,内容体、及一个RpcResponseCallback类型的匿名内部类作为参数传递给了RpcHandler的receive方法
// 真正用于处理RpcRequest消息的是RpcHandler
rpcHandler.receive(reverseClient, req.body().nioByteBuffer(), new RpcResponseCallback() {
@Override
public void onSuccess(ByteBuffer response) {
respond(new RpcResponse(req.requestId, new NioManagedBuffer(response)));
}
@Override
public void onFailure(Throwable e) {
respond(new RpcFailure(req.requestId, Throwables.getStackTraceAsString(e)));
}
});
} catch (Exception e) {
logger.error("Error while invoking RpcHandler#receive() on RPC id " + req.requestId, e);
respond(new RpcFailure(req.requestId, Throwables.getStackTraceAsString(e)));
} finally {
req.body().release();
}
}
我们先看receive方法,进去后,其实是NettyRpcHandler的receive方法,
/**
* 1. 调用internalReceive方法将ByteBuffer类型的message转换为RequestMessage。
* 2. 调用Dispatcher的postRemoteMessage方法将消息转换为RpcMessage后放入Inbox的消息列表。
* MessageLoop将调用RpcEnd-Point实现类的receiveAndReply方法,即RpcEndPoint处理完消息后会向客户端进行回复
*
* @param client A channel client which enables the handler to make requests back to the sender
* of this RPC. This will always be the exact same object for a particular channel.
* @param message The serialized bytes of the RPC.
* @param callback Callback which should be invoked exactly once upon success or failure of the
* RPC.
*
*/
override def receive(
client: TransportClient,
message: ByteBuffer,
callback: RpcResponseCallback): Unit = {
// 将ByteBuffer类型的message转换为RequestMessage。
val messageToDispatch = internalReceive(client, message)
dispatcher.postRemoteMessage(messageToDispatch, callback)
}
首先调用internalReceive()方法,将ByteBuffer类型的message转换为RequestMessage。
/**
* 1. 从TransportClient中获取远端地址RpcAddress。
* 2. 调用NettyRpcEnv的deserialize方法对客户端发送的序列化后的消息(即ByteBuffer类型的消息)进行反序列化,根据deserialize的实现,
* 反序列化实际使用了javaSerializerInstance。javaSerializerInstance是通过NettyRpcEnv的构造参数传入的对象,类型
*
* 3.如果反序列化得到的请求消息requestMessage中没有发送者的地址信息,则使用从TransportClient中获取的远端地址RpcAddress、
* requestMessage的接收者(即RpcEndpoint)、requestMessage的内容,以构造新的RequestMessage
* 4. 如果反序列化得到的请求消息requestMessage中含有发送者的地址信息,则将从TransportClient中获取的远端地址RpcAddress与requestMessage中的发送者地址信息之间的映射关系放入缓存remoteAddresses
* 。还将调用Dispatcher的postToAll方法,向endpoints缓存的所有EndpointData的Inbox中放入RemoteProcessConnected消息。最后将返回requestMessage
* @param client
* @param message
* @return
*/
private def internalReceive(client: TransportClient, message: ByteBuffer): RequestMessage = {
// 从TransportClient中获取远端地址RpcAddress。
val addr = client.getChannel().remoteAddress().asInstanceOf[InetSocketAddress]
assert(addr != null)
val clientAddr = RpcAddress(addr.getHostString, addr.getPort)
val requestMessage = RequestMessage(nettyEnv, client, message)
if (requestMessage.senderAddress == null) {
// Create a new message with the socket address of the client as the sender.
new RequestMessage(clientAddr, requestMessage.receiver, requestMessage.content)
} else {
// The remote RpcEnv listens to some port, we should also fire a RemoteProcessConnected for
// the listening address
val remoteEnvAddress = requestMessage.senderAddress
if (remoteAddresses.putIfAbsent(clientAddr, remoteEnvAddress) == null) {
dispatcher.postToAll(RemoteProcessConnected(remoteEnvAddress))
}
requestMessage
}
}
然后会调用dispatcher的postRemoteMessage()方法,
/** Posts a message sent by a remote endpoint. */
def postRemoteMessage(message: RequestMessage, callback: RpcResponseCallback): Unit = {
/**
* RpcCallContext是用于回调客户端的上下文
*/
val rpcCallContext =
new RemoteNettyRpcCallContext(nettyEnv, callback, message.senderAddress)
val rpcMessage = RpcMessage(message.senderAddress, message.content, rpcCallContext)
postMessage(message.receiver.name, rpcMessage, (e) => callback.onFailure(e))
}
最终调用postMessage()方法,将消息提交给指定的RpcEndpoint,然后将消息添加到Inbox的消息列表中
/**
* Posts a message to a specific endpoint.
* 将消息提交给指定的RpcEndpoint
*
* 1. 根据端点名称endpointName从缓存endpoints中获取EndpointData。
* 2. 如果当前Dispatcher没有停止并且缓存endpoints中确实存在名为endpointName的EndpointData,
* 那么将调用EndpointData对应Inbox的post方法将消息加入Inbox的消息列表中,因此还需要将EndpointData推入receivers,
* 以便MessageLoop处理此Inbox中的消息。Inbox的post方法的实现其逻辑为Inbox未停止时向messages列表加入消息。
*
*
* @param endpointName name of the endpoint.
* @param message the message to post
* @param callbackIfStopped callback function if the endpoint is stopped.
*/
private def postMessage(
endpointName: String,
message: InboxMessage,
callbackIfStopped: (Exception) => Unit): Unit = {
val error = synchronized {
val data = endpoints.get(endpointName)
if (stopped) {
Some(new RpcEnvStoppedException())
} else if (data == null) {
Some(new SparkException(s"Could not find $endpointName."))
} else {
data.inbox.post(message)
receivers.offer(data)
None
}
}
// We don't need to call `onStop` in the `synchronized` block
error.foreach(callbackIfStopped)
}
到这里,从刚开始的send()方法,一直执行到最后,将消息加到inbox的messages中,然后dispatcher的处理线程任务则会取出数据,然后模式匹配,最终调用相关endpoint的处理方法,这里RpcMessage的处理方法则为receiveAndReply(),master的话,就会调用master的receiveAndReply()
这一步部分发送消息我们分析完了,往前找
private void processRpcRequest(final RpcRequest req) {
try {
//将RpcRequest消息的发送消息的客户端,内容体、及一个RpcResponseCallback类型的匿名内部类作为参数传递给了RpcHandler的receive方法
// 真正用于处理RpcRequest消息的是RpcHandler
rpcHandler.receive(reverseClient, req.body().nioByteBuffer(), new RpcResponseCallback() {
@Override
public void onSuccess(ByteBuffer response) {
respond(new RpcResponse(req.requestId, new NioManagedBuffer(response)));
}
@Override
public void onFailure(Throwable e) {
respond(new RpcFailure(req.requestId, Throwables.getStackTraceAsString(e)));
}
});
} catch (Exception e) {
logger.error("Error while invoking RpcHandler#receive() on RPC id " + req.requestId, e);
respond(new RpcFailure(req.requestId, Throwables.getStackTraceAsString(e)));
} finally {
req.body().release();
}
}
这里有回调方法方法,如果发送成功,则将消息封装为RpcResponse,然后调用respond()方法发送响应客户端,底层也是Netty的writeAndFlush方法
/**
* Responds to a single message with some Encodable object. If a failure occurs while sending,
* it will be logged and the channel closed.
*
* respond方法中实际调用了Channel的writeAndFlush方法响应客户端
*/
private ChannelFuture respond(Encodable result) {
SocketAddress remoteAddress = channel.remoteAddress();
return channel.writeAndFlush(result).addListener(future -> {
if (future.isSuccess()) {
logger.trace("Sent result {} to client {}", result, remoteAddress);
} else {
logger.error(String.format("Error sending result %s to %s; closing connection",
result, remoteAddress), future.cause());
channel.close();
}
});
}
最终还是发送到客户端的管道中,然后客户端绑定的TransportChannelHandler,又会去调用channelRead()方法,根据请求的不通,调用requestHandler或者responseHandler的handle()的方法,不断地处理消息。这当中的编码和解码本文中也讲过了。至于文件,jar上传下载,会发送块儿请求,如果读者完整跟着走下来一步一步分析的话,那么自己就应该可以看懂的。最后总结一下
Endpoint 启动过程图

Endpoint 启动后,默认会向 Inbox 中添加 OnStart 消息,不同的端点(Master/Worker/Client)消费 OnStart 指令时,进行相关端点的启动额外处理。
Endpoint 启动时,会默认启动 TransportServer,且启动结束后会进行一次同步测试 rpc 可用性(askSync-BoundPortsRequest)。
Dispatcher 作为一个分发器,内部存放了 Inbox,Outbox 的等相关句柄和存放了相关处理状态数据,结构大致如下:
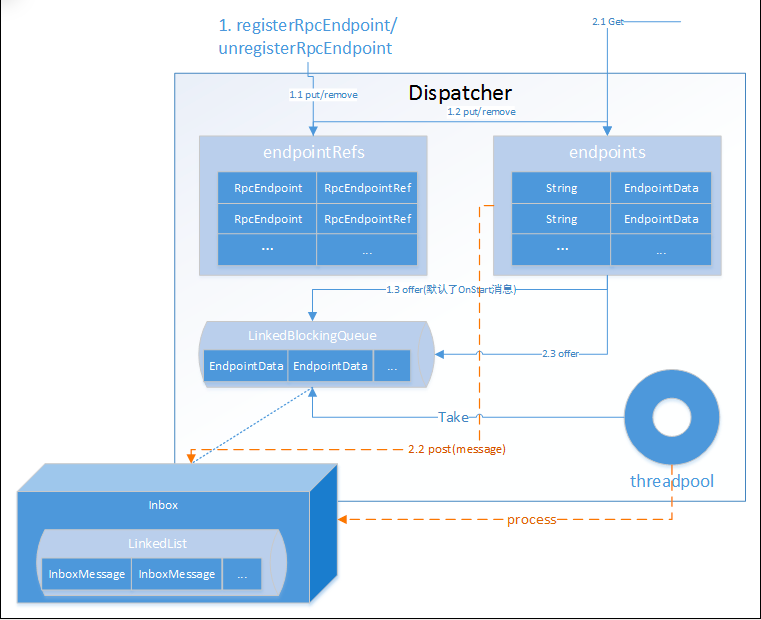
Endpoint Send&Ask 流程图

Endpoint 根据业务需要存入两个维度的消息组合:send/ask 某个消息,receiver 是自身与非自身
•1 OneWayMessage:send + 自身,直接存入收件箱
•2 OneWayOutboxMessage:send + 非自身,存入发件箱并直接发送
•3 RpcMessage:ask + 自身,直接存入收件箱,另外还需要存入 LocalNettyRpcCallContext,需要回调后再返回
•4 RpcOutboxMessage:ask + 非自身,存入发件箱并直接发送,需要回调后再返回
Endpoint Receive 流程图

Endpoint Inbox 处理流程图
Spark 在 Endpoint 的设计上核心设计即为 Inbox 与 Outbox,其中 Inbox 核心要点为:
•1 内部的处理流程拆分为多个消息指令(InboxMessage)存放入 Inbox。
•2 当 Dispatcher 启动最后,会启动一个名为【dispatcher-event-loop】的线程扫描 Inbox 待处理 InboxMessage,并调用 Endpoint 根据 InboxMessage 类型做相应处理
•3 当 Dispatcher 启动最后,默认会向 Inbox 存入 OnStart 类型的 InboxMessage,Endpoint 在根据 OnStart 指令做相关的额外启动工作,三端启动后所有的工作都是对 OnStart 指令处理衍生出来的,因此可以说 OnStart 指令是相互通信的源头。

消息指令类型大致如下三类:
•1 OnStart/OnStop
•2 RpcMessage/OneWayMessage
•3 RemoteProcessDisconnected/RemoteProcessConnected/RemoteProcessConnectionError
组件交互图

如果读者从开始一直跟到现在,那么我觉得直接把sparkRpc从spark中剥离出来,自己实现一个,也是不难的。后面会更Spark其他的组件源码分析。















 1704
1704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









