




 本文介绍了如何在Windows环境下利用Python3.6和TensorFlow搭建一个简单的卷积神经网络(CNN),对CIFAR-10数据集进行分类。数据集包含60000张32x32彩色图像,分为训练和测试两部分。通过Cifar10_data.py和CNN_Cifar-10.py两个文件完成数据读取、预处理、模型构建和训练过程。训练结果显示,模型在训练过程中具有较低的损失值,每秒能处理约154个样本,每个batch训练时间约为0.647秒。最终,模型在测试集上的表现也进行了评估。
本文介绍了如何在Windows环境下利用Python3.6和TensorFlow搭建一个简单的卷积神经网络(CNN),对CIFAR-10数据集进行分类。数据集包含60000张32x32彩色图像,分为训练和测试两部分。通过Cifar10_data.py和CNN_Cifar-10.py两个文件完成数据读取、预处理、模型构建和训练过程。训练结果显示,模型在训练过程中具有较低的损失值,每秒能处理约154个样本,每个batch训练时间约为0.647秒。最终,模型在测试集上的表现也进行了评估。
1.环境
本人电脑win7+python3.6+i5,E盘创建一个文件夹Cifar_data,里面包括cifar-10-binary.tar.gz解压后的数据集cifar-10-batches-bin,Cifar10_data.py文件主要负责读取数据并对其进行数据增强预处理。
CNN_Cifar-10.py,文件负责构建卷积神经网络的整体结构,并运行训练和测试的过程。
2.数据集
Cifar10网站链接
里面有三个版本的数据集,分别为
CIFAR-10 python版本
CIFAR-10 Matlab版本
CIFAR-10 binary 版本 (适合 C 语言)
本次用了第三个版本,解压后如下:
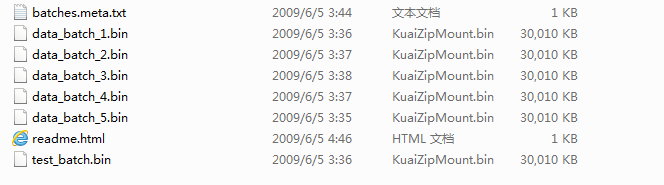
数据包含60000张32x32彩色图像,训练集图像50000张,测试集图像10000张,除了test_batch.bin中保存的10000张测试集图像数据,其他五个.bin文件各自保存10000张训练集图像。Cifar10数据集标注10类,彼此间没有重叠情况,batches.meta.txt文件中是10类标签的字符串信息。
3.代码
Cifar10_data.py
import os
import tensorflow as tf
"""
该文件负责读取数据并对其进行数据增强预处理
"""
num_classes=10
# 设定用于训练和评估的样本总数
num_examples_pre_epoch_for_train=50000
num_examples_pre_epoch_for_eval=10000
# 定义一个空类,用于返回读取的数据
class CIFAR10Record(object):
pass
# 定义读取cifar10数据的函数
def read_cifar10(file_queue):
result=CIFAR10Record()
label_bytes=1#如果是cifar_100数据集,则是为2
result.height=32
result.width=32
result.depth=3#RGB三通道
image_bytes=result.height*result.width*result.depth#=3072
# 每个样本都包含一个lable数据和image数据,结果为:record_bytes=3073
record_bytes=label_bytes+image_bytes
"""
创建一个文件读取类,并调用该类的read()函数从文件队列中读取文件
FiexdLengthRecordReader类用于读取固定长度字节数信息(针对bin文件而言,使用这个类读取比较合适)
"""
# 构造函数原型:__init__(self,record_bytes,header_bytes,footer_bytes,name)
reader=tf.FixedLengthRecordReader(record_bytes=record_bytes)
result.key,value=reader.read(file_queue)
# 得到的value就是record_bytes长度的包含多个label数据和image数据的字符串
# decode_raw函数可以将字符串解析成图像对应的像素数组
record_bytes=tf.decode_raw(value,tf.uint8)
# 将得到的record_bytes数组中第一个元素类型转换为int32类型
# strided_slice函数用于对input截取[begin,end]区间的数据
result.label=tf.cast(tf.strided_slice(record_bytes,[0],[label_bytes]),tf.int32)
# 剪切label后就剩下图片数据,将数据的格式从[depth*height*width]转换为[depth,height,width]
depth_major=tf.reshape(tf.strided_slice(record_bytes,[label_bytes],
[label_bytes+image_bytes]),
[result.depth,result.height,result.width])
# 将[depth,height,width]转换为[height,width,depth]
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9634
9634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









