







引言
支持向量机SVM是机器学习中非常优秀的算法,在解决小样本问题上具有出色的性能。然而,SVM的性能受其参数的影响。传统的依靠人工经验选取和网格试错法都难以很好地解决。群智能优化算法是一种很有吸引力的算法,可以在保持计算成本合理的情况下解决SVM参数的选择问题,提高SVM的分类性能和泛化能力。本文利用matlab自带的SVM分类器(省去了安装第三方工具箱的繁琐),通过群智能优化算法选择SVM合适参数,解决分类问题。
数据集
本文使用分类任务中经典的iris鸢尾花数据集。该数据集有3个类别,每个类别50个样本,每个样本4个特征,形成了150*4的样本格式,即样本数*特征个数。
SVM分类器
本文利用Matlab自带了SVM分类器fitcecoc函数用于多分类任务(类别数>2),利用fitcsvm用于二分类任务。详细信息请参考matlab的阅读文档:
https://www.mathworks.com/help/stats/fitcecoc.html
本文选择径向基核函数(RBF)作为SVM的核函数,因此,SVM待选择的参数有两个:惩罚系数C和核参数g。k折交叉验证的误差作为优化目标函数。
优化算法
以2023年发表在中科院1区SCI上的成吉思汗鲨鱼优化算法(Genghis Khan shark optimizer,GKSO)(源码),和受欢迎的灰狼优化算法(GWO)(源码)作为例子。前期也推出了多种统计指标(一网打尽优化算法的8种统计指标,助力提升论文录用率(附Matlab代码)),本文在SVM参数优化中继续使用。
% 这是一个入门级示例代码,目的是快速准确实现功能
% 更多高级的运用(图形美化,代码美化等),请自行探索修改
% 运行时间与电脑配置,参数设置等有关
% 关注微信公众号:优化算法侠,发现更多精彩
clc;clear;close all; warning off
disp('Running......')
%% 读取数据
load iris
data = iris(:,1:4); % 所有样本,格式:样本数N x 特征数M
labels=iris(:,5); % 所有标签-用1,2,3...表示
%% 一些设置
global train_data train_label test_data test_label %声明全局变量,便于后续使用
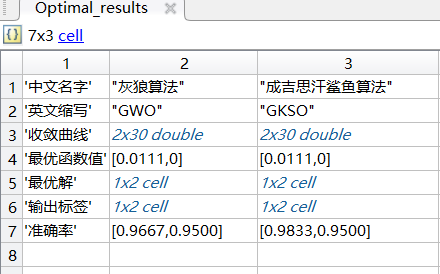
% 运行多次,结果保存在Optimal_results
str = {'中文名字','英文缩写','收敛曲线','最优函数值','最优解','输出标签','准确率'}; % 表头制作
Optimal_results={};
for i=1:length(str)
Optimal_results{i,1}=str(i);
end
%% 每一次运行重新划分数据集
% 参数设置
run_times=2; % 运行次数
train_p=0.6; % 训练集比例:60%
% 优化问题的四大元素:
fobj=@objective_func; % 目标函数
lb = [ 2^-3 2^-3]; % 下界
ub = [ 2^10 2^10 ]; % 上界
dim=length(lb); % 维度
%
nPop=20; % 种群数
MaxIter=30; % 最大迭代次数
for run_time=1:run_times
%% 划分训练集和测试集
[train_data, train_label,test_data,test_label]=data_splite(data,labels,train_p);
%% 调用优化算法
%
tic
[Best_score,Best_paras,cg_curve]=GWO(nPop,MaxIter,lb,ub,dim,fobj);
[out_label,accuracy]= Make_model(Best_paras); % 输入测试集输出结果
Optimal_results{1,2}="灰狼算法"; % 中文名字
Optimal_results{2,2}="GWO"; % 名字
Optimal_results{3,2}(run_time,:)=cg_curve; % 收敛曲线
Optimal_results{4,2}(run_time)=Best_score; % 最优函数值
Optimal_results{5,2}{run_time}=Best_paras; % 最优解
Optimal_results{6,2}{run_time}=out_label; % 输出的标签
Optimal_results{7,2}(run_time)=accuracy; % 准确率
%
[Best_score,Best_paras,cg_curve]=GKSO(nPop,MaxIter,lb,ub,dim,fobj);
[out_label,accuracy]= Make_model(Best_paras);
Optimal_results{1,3}="成吉思汗鲨鱼算法";
Optimal_results{2,3}="GKSO";
Optimal_results{3,3}(run_time,:)=cg_curve;
Optimal_results{4,3}(run_time)=Best_score;
Optimal_results{5,3}{run_time}=Best_paras;
Optimal_results{6,3}{run_time}=out_label;
Optimal_results{7,3}(run_time)=accuracy;
%
toc
end
%% 统计输出有:
% 最差值worst
% 最优值best
% 标准差值std
% 均值mean
% 中值median
% wilcoxon_test:Wilcoxon符号秩检验、 Wilcoxon秩和检验
% friedman_p_value:friedman检验
[Results,wilcoxon_test,friedman_p_value]=Cal_stats(Optimal_results);
for i=2:size(Results,2)
fprintf('%s 优化SVM的 %d 次平均准确率为:%.4f \n',Results{2,i},run_times,Results{7,i});
end
%% 绘图-收敛曲线,混淆矩阵,箱线图等
DrawPic(Results,Optimal_results)
disp('End !!!')结果展示:
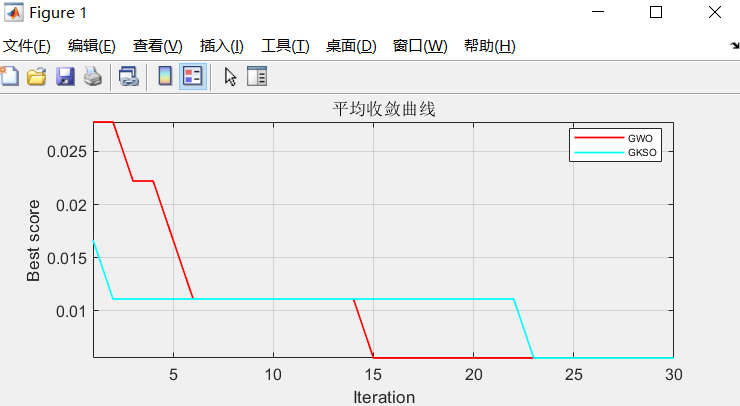
优化算法收敛曲线对比
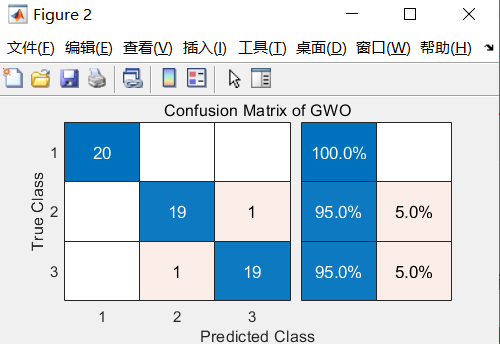
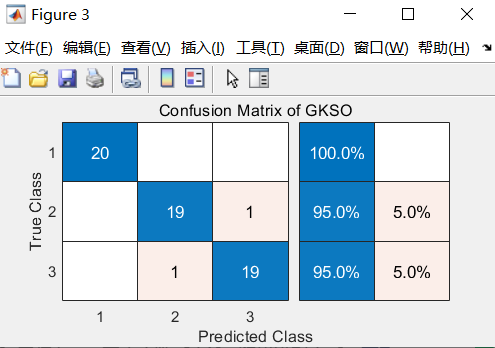
混淆矩阵
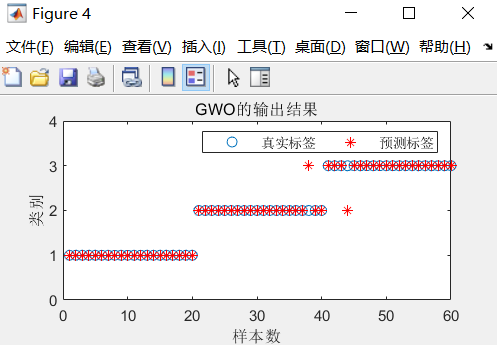
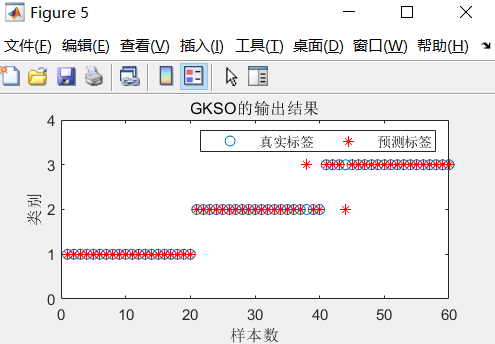
分类结果图
箱型图boxplot

多次运行结果保存在Optimal_results中。这里考虑快速验证代码和算法,仅运行了2次,可根据实际需要修改。
Matlab代码下载
微信搜索并关注-优化算法侠,或扫描下方二维码关注,以算法名字搜索历史文章即可下载。
320多种基础的群智能优化算法-matlab
175种群智能优化算法python库
求解cec测试函数-matlab
解决12工程设计优化问题-matlab
求解11种cec测试函数-python
解决12种工程设计优化问题-python
















 1626
1626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









