







排序完了后我们就开始做查找这一部分了,
查找的常用方法为:
- 线性查找O(n)
- 二分查找O(logn) -----必须是有序序列
- 散列查找O(1)-----利用散列表(哈希表)
例题3.5

import java.util.Arrays;
import java.util.Scanner;
public class c7 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int[] arr1 = new int[n];
for (int i = 0; i < n; i++) {
arr1[i] = scanner.nextInt();
}
int m = scanner.nextInt();
int[] arr2 = new int[m];
for (int i = 0; i < m; i++) {
arr2[i] = scanner.nextInt();
}
Arrays.sort(arr1);
for (int i = 0; i < m; i++) {
if( Arrays.binarySearch(arr1,arr2[i])>=0){
System.out.println("YES");
}
else {
System.out.println("NO");
}
}
}
}
竟然出乎意料的简单,不过有一点就是,必须排序才能二分查找,否则就用暴力方法,线性查找,线性查找这就不做过多解释了。
下面是c++的
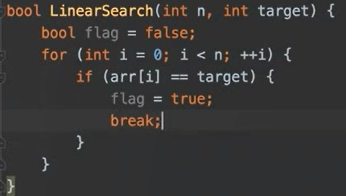
例题3.6 二分查找
二分查找一定是在,目标已经排序好的基础上进行了。
下面是参照了java部分源码来写的
static int binarySearch(int[] arr, int key){
int low = 0;
int high = arr.length - 1;
while (low <= high) {
int mid = (low + high) /2;//源码为(low+high) >>>1;
int midVal = arr[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}
emm估计也是算准了递归会降低效率吧
散列查找
散列查找有两种,一种是自定义的,一种是系统自带的。
散列表也叫做哈希表。
int arr[]= new int[10];
Random random = new Random(1);
HashMap<Integer, Integer> hashMap = new HashMap<Integer, Integer>();
for (int i = 0; i < 10; i++) {
arr[i] = random.nextInt(100);
hashMap.put(i,arr[i]);
}
Iterator<Map.Entry<Integer, Integer>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()){
System.out.println(iterator.next().getKey());
}
哈希表的遍历如上。这里使用了一个迭代器。
重点就是下面两个东西,注意泛型的位置<T,T>
HashMap<Integer, Integer> hashMap = new HashMap<Integer, Integer>();
Iterator<Map.Entry<Integer, Integer>> iterator = hashMap.entrySet().iterator();
while (iterator.hasNext()){
System.out.println(iterator.next().getKey());
}
这里注意一点
关于常用的IDE之eclipse代码优化的提示

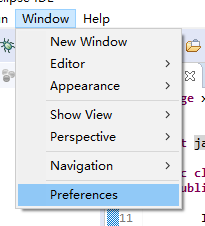
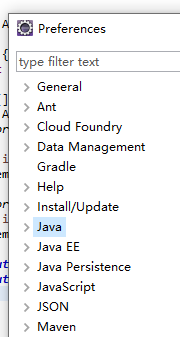
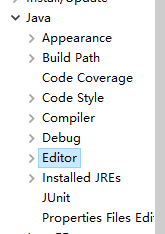


- 这里换成 abcdefghijklmnopqrstuvwxyz. 就会自动提示了。















 5588
5588











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









