









系列文章目录
目录
239.滑动窗口最大值
(1)利用双端队列实现单调队列,队列只存可能为最大值的值,队头始终是最大值,队列始终是降序排序的。
自定义单调队列:
class MyQueue {
ArrayDeque<Integer> deque = new ArrayDeque<>();
//LinkedList<Integer> deque = new LinkedList<>();
public void pop(int value) {
}
public void push(int value) {
}
public int peek() {
}
}
(2)在调用队列方法时最好先判断一下队列是否为空,若队列为空,则调用某些方法比如pop()、removeFirst()、removeLast()、getFirst()、getLast()、remove()、element()时会报NoSuchElementException 异常。
①在单调队列中保存数组的值
(1)在pop()时要注意数组下标是否越界,只有当i >= k时才需要弹出元素。
(2)在记录对应的最大值时要注意只有在形成窗口后才需要记录,即i >= k - 1时才需要记录。
import java.util.LinkedList;
//leetcode submit region begin(Prohibit modification and deletion)
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int[] res = new int[nums.length - k + 1];
//存放结果元素的数组
int num = 0;
MyQueue myQueue = new MyQueue();
for (int i = 0; i < nums.length; i++) {
if(i >= k){//形成窗口k-1,在k时就开始要弹出元素
myQueue.pop(nums[i - k]);
}
myQueue.push(nums[i]);
if (i >= k - 1) {//形成窗口后再取最大值
res[num++] = myQueue.peek();
}
}
return res;
}
}
//自定义单调队列
class MyQueue {
ArrayDeque<Integer> deque = new ArrayDeque<>();
//LinkedList<Integer> deque = new LinkedList<>();
//在队列中保存数组的值
//弹出元素时,比较当前要弹出的数值是否等于队列出口的数值,如果相等则弹出(用if,只弹出一个元素!!)
public void pop(int val) {
if (!deque.isEmpty() && deque.peek() == val) {
deque.pop();
}
}
//添加元素时,如果要添加的元素大于入口(队列末尾)处的元素,就将入口(队列末尾)元素弹出
//保证队列元素单调递减
//比如此时队列元素3,1,2将要入队,比1大,所以1弹出,此时队列:3,2
public void push(int val) {
while (!deque.isEmpty() && deque.getLast() < val) {
deque.removeLast();
}
deque.offer(val);
}
//队列队顶元素始终为最大值
public int peek() {
return deque.peek();
}
}
//leetcode submit region end(Prohibit modification and deletion)
②在单调队列中保存数组的下标
在pop()时只需保证队列头结点位置在[i - k + 1, i]范围内,否则弹出头节点即可。
import java.util.LinkedList;
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
LinkedList<Integer> deque = new LinkedList<>();
int[] res = new int[nums.length - k + 1];
int num = 0;
for (int i = 0; i < nums.length; i++) {
//pop操作,i为nums下标,是要在[i - k + 1, i] 中选到最大值,
// 队列头结点需要在[i - k + 1, i]范围内,不符合则要弹出
if (!deque.isEmpty() && deque.peek() < i - k + 1) {
deque.poll();
}
//push操作,既然是单调,就要保证每次放进去的数字要比末尾的都大,否则也弹出
while (!deque.isEmpty() && nums[i] > nums[deque.peekLast()]) {
deque.pollLast();
}
deque.offer(i);
//peek操作,当i增长到符合第一个k范围的时候,每滑动一步都将队列头节点放入结果就行了
if (i >= k - 1) {
res[num++] = nums[deque.peek()];
}
}
return res;
}
}

347.前K个高频元素
(1)Comparator接口说明:
- 返回负数,形参中第一个参数排在前面;返回正数,形参中第二个参数排在前面;
- 对于队列:排在前面意味着往队头靠;
- 对于堆(使用
PriorityQueue实现):从队头到队尾按从小到大排就是最小堆(小顶堆);从队头到队尾按从大到小排就是最大堆(大顶堆)—>队头元素相当于堆的根节点。
(2)Lambda 表达式:也可称为闭包,它是推动 Java 8 发布的最重要新特性。Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。使用 Lambda 表达式可以使代码变的更加简洁紧凑。
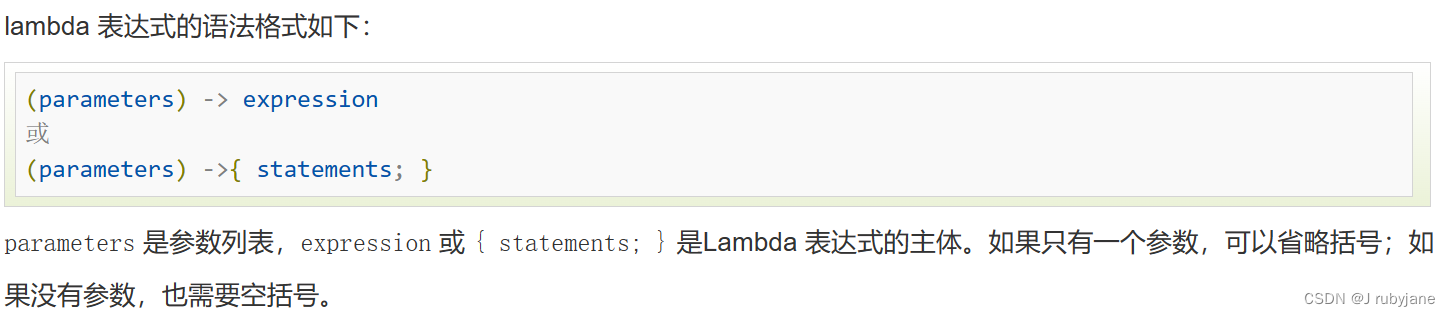
① HashMap(统计频次)+PriorityQueue(构建大顶堆,对频次进行排序)
1)在优先队列(PriorityQueue)中存储二元组(num,cnt)
(1)在优先队列中存储二元组(num,cnt),cnt表示元素值num在数组中的出现次数,出现次数按从队头到队尾的顺序是从大到小排,出现次数最多的在队头(相当于大顶堆)。
-
Lambda 表达式
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2)->pair2[1]-pair1[1]); -
使用
Comparator接口的匿名内部类PriorityQueue<int[]> pq = new PriorityQueue<>(new Comparator<int[]>() { @Override public int compare(int[] o1, int[] o2) { return o2[1] - o1[1];//从大到小排 } });
(2)将map中的键值对加入优先级队列进行排序,需要将键值对存储为有2个元素的数组,再加入优先级队列。
-
先获得
keySet,再根据key得到对应的value,然后将这两个元素作为数组元素加入到优先级队列中。Set<Integer> keyset = map.keySet(); for(Integer key:keyset){//大顶堆需要对所有元素进行排序 pq.add(new int[]{key,map.get(key)}); } -
获得
EntrySet,再根据EntrySet的getKey和getValue方法获得键值对的值。
<1>使用迭代器遍历map中的元素。Set<Map.Entry<Integer, Integer>> set = map.entrySet(); //迭代器 Iterator<Map.Entry<Integer, Integer>> iterator = set.iterator(); while(iterator.hasNext()){ Map.Entry<Integer, Integer> next = iterator.next(); pq.add(new int[]{next.getKey(),next.getValue()}); }<2>使用增强
for循环遍历map中的元素。for (Map.Entry<Integer, Integer> entry : set) { pq.add(new int[]{entry.getKey(), entry.getValue()}); }*/
完整代码如下:
import java.util.*;
class Solution {
public int[] topKFrequent(int[] nums, int k) {
HashMap<Integer, Integer> map = new HashMap<>();//key为数组元素值,val为对应出现次数
//将集合中所有元素加入map中
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
//大顶堆
PriorityQueue<int[]> pq = new PriorityQueue<>(new Comparator<int[]>() {
@Override
public int compare(int[] o1, int[] o2) {
return o2[1] - o1[1];//从大到小排
}
});
//将map中的键值对加入优先级队列进行排序
//①先获得keySet,再根据key得到对应的value
Set<Integer> keyset = map.keySet();
for(Integer key:keyset){//大顶堆需要对所有元素进行排序
pq.add(new int[]{key,map.get(key)});
}
int[] res = new int[k];
for (int i = 0; i < k; i++) {//依次从队头弹出k个,就是出现频率前k高的元素
res[i]=pq.poll()[0];
}
return res;
}
}
2)在优先队列(PriorityQueue)中存储Entry
在优先队列中存储Map.Entry,entry.getKey()表示元素值,entry.getValue()b表示在数组中的出现次数,出现次数按从队头到队尾的顺序是从大到小排,出现次数最多的在队头(相当于大顶堆)。使用Comparator接口的匿名内部类来作为比较器:
PriorityQueue<Map.Entry<Integer, Integer>> pq = new PriorityQueue<>(new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o2.getValue() - o1.getValue();//从大到小排
}
});
完整代码如下:
import java.util.*;
class Solution {
public int[] topKFrequent(int[] nums, int k) {
HashMap<Integer, Integer> map = new HashMap<>();//key为数组元素值,val为对应出现次数
//将集合中所有元素加入map中
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
//大顶堆
PriorityQueue<Map.Entry<Integer, Integer>> pq = new PriorityQueue<>(new Comparator<Map.Entry<Integer, Integer>>() {
@Override
public int compare(Map.Entry<Integer, Integer> o1, Map.Entry<Integer, Integer> o2) {
return o2.getValue() - o1.getValue();//从大到小排
}
});
//将map中的键值对加入优先级队列进行排序
for (Map.Entry<Integer, Integer> entry:map.entrySet()){
pq.add(entry);//大顶堆需要对所有元素进行排序
}
int[] res = new int[k];
for (int i = 0; i < k; i++) {//依次从队头弹出k个,就是出现频率前k高的元素
res[i]=pq.poll().getKey();
}
return res;
}
}

② HashMap(统计频次)+PriorityQueue(构建大小为k的小顶堆,对频次进行排序)
(1)在优先队列中存储二元组(num,cnt),cnt表示元素值num在数组中的出现次数,出现次数按从队头到队尾的顺序是从小到大排,出现次数最低的在队头(相当于小顶堆)。
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1,pair2)->pair1[1]-pair2[1]);
(2)小顶堆只需要维持k个元素有序,pq.size() < k即小顶堆元素个数小于k个时直接加入,否则当当前元素出现次数大于小顶堆的根结点(这k个元素中出现次数最少的那个)时,弹出队头(小顶堆的根结点),即把堆里出现次数最少的那个删除,再加入当前元素即可。
(3)最后在返回k个最高频次的元素的数组时,从数组后面开始加入元素,先弹出的是堆的根,出现次数少,后面弹出的出现次数多,这样最终该数字是从大到小返回的。
import java.util.*;
class Solution {
public int[] topKFrequent(int[] nums, int k) {
//key为数组元素值,val为对应出现次数
HashMap<Integer, Integer> map = new HashMap<>();
for (Integer num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
//使用小顶堆
PriorityQueue<int[]> pq = new PriorityQueue<>((pair1, pair2) -> pair1[1] - pair2[1]);//从小到大
for (Map.Entry<Integer, Integer> entry : map.entrySet()) {//小顶堆只需要维持k个元素有序
if (pq.size() < k) {//小顶堆元素个数小于k个时直接加
pq.add(new int[]{entry.getKey(), entry.getValue()});
} else {
if (entry.getValue() > pq.peek()[1]) {//当前元素出现次数大于小顶堆的根结点(这k个元素中出现次数最少的那个)
pq.poll();//弹出队头(小顶堆的根结点),即把堆里出现次数最少的那个删除,留下的就是出现次数多的了
pq.add(new int[]{entry.getKey(), entry.getValue()});
}
}
}
int[] res = new int[k];
//从数组后面开始加入元素,依次弹出小顶堆,先弹出的是堆的根,出现次数少,后面弹出的出现次数多
for (int i = k - 1; i >= 0; i--) {
res[i] = pq.poll()[0];
}
return res;
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









