









系列文章目录
435. 无重叠区间
贪心算法
通过排序让区间尽可能的重叠。可以左边界排序也可右边界排序。

按左边界排序(与【452. 用最少数量的箭引爆气球】思路差不多)
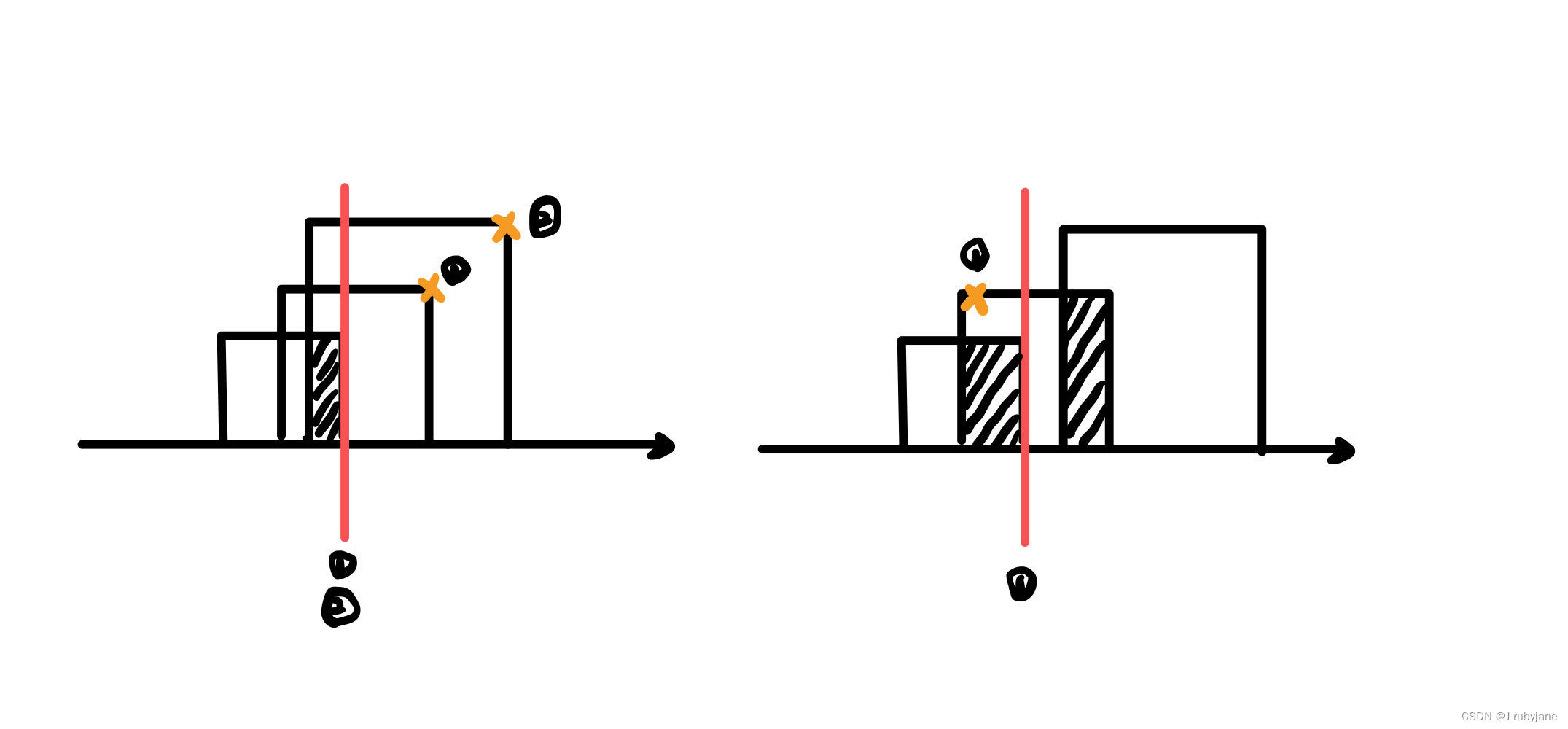
当两个区间重叠时,需要记录重叠的区间(或者记录最大非交叉区间的数量,即【452. 用最少数量的箭引爆气球】的弓箭的数量,只要把弓箭那道题目代码里非重叠区间的判断条件加个等号(认为[0,1][1,2]不是相邻区间),然后用总区间数减去弓箭数量就是要移除的区间数量了。),并更新最小右边界,因如果下一个区间的左边界<当前最小右边界,则说明有三个区间重叠,必须要删除其中两个才行。而如果下一个区间的左边界>当前最小右边界,则可以只删一个区间就可让区间不重叠。如下图所示:
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
//int nonOverlapNum = 1;
int overlapNum = 0;
Arrays.sort(intervals, (a, b) -> Integer.compare(a[0], b[0]));
/*for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] >= intervals[i - 1][1]) {// 区间非重叠
nonOverlapNum++;
} else {//重叠
intervals[i][1] = Math.min(intervals[i - 1][1], intervals[i][1]);
}
}
return intervals.length - nonOverlapNum;*/
for (int i = 1; i < intervals.length; i++) {
if (intervals[i][0] < intervals[i - 1][1]) {//区间重叠
overlapNum++;
intervals[i][1] = Math.min(intervals[i - 1][1], intervals[i][1]);
}
}
return overlapNum;
}
}
763.划分字母区间
贪心算法
①将字符串映射到哈希数组,用二维数组记录每个字母存在的区间, 转化为重叠区间问题求解
- 遍历每个字符记录每个字母的区间:将字符串映射到二维数组上,即下标为
s.charAt(i) - 'a'的地方,在遍历字符串时,将每个字符第一次出现的起始位置记录下来,注意第一个元素要区别对待且放在记录其他元素起始位置的下方,否则后面如果出现和第一个元素相同的字母[起始坐标为0],会错误更新起始位置。 - 判断当前区间与上一个区间是否重叠,进而判断是否划分片段,因是通过遍历字符串来间接遍历该字母所对应的区间,故区间起始位置已经是有序的了,只需查看是否覆盖即可。注意每次划分片段都是在片段的下一个区间进行的,因此最后一个片段得单独处理。
- 缺点:映射的数组没有过滤空元素,即有些没有在字符串中出现过的字母映射的下标上虽然没有值,但却在该数组中。故判断区间是否重叠时只能再遍历字符串以避免遍历到空元素,但这会导致重复遍历区间,比如一个字符出现两次,则会遍历两次该字符所对应的区间,如何只关注区间而不会产生空元素呢?可以映射到
LinkedHashMap使存储顺序与输入顺序相同,后序就不需要排序来判断区间是否的覆盖,key为出现过的字母,value为二维数组(存储key对应字母的区间索引)。
import java.util.LinkedList;
import java.util.List;
class Solution {
public List<Integer> partitionLabels(String s) {
List<Integer> res = new LinkedList<>();
int count = 0;
int[][] letter = new int[26][2];//26个字母2列 表示该字母对应的区间
//遍历每个字符记录每个字母的区间
for (int i = 0; i < s.length(); i++) {
//第一次出现,更新起始位置
if (i > 0 && letter[s.charAt(i) - 'a'][0] == 0) {
letter[s.charAt(i) - 'a'][0] = i;
}
//第一个元素区别对待一下(一定要放在下面,否则后面如果出现和第一个元素相同的字母[起始坐标为0],会错误更新起始位置)
letter[s.charAt(0) - 'a'][0] = 0;
// 更新结束位置
letter[s.charAt(i) - 'a'][1] = i;
}
//字符串从前往后遍历,其起始位置已经是有序的了,只需查看是否覆盖即可
for (int i = 1; i < s.length(); i++) {
if (letter[s.charAt(i - 1) - 'a'][1] >= letter[s.charAt(i) - 'a'][0]) {//重叠
letter[s.charAt(i) - 'a'][0] = Math.min(letter[s.charAt(i - 1) - 'a'][0], letter[s.charAt(i) - 'a'][0]);//取最小左边
letter[s.charAt(i) - 'a'][1] = Math.max(letter[s.charAt(i - 1) - 'a'][1], letter[s.charAt(i) - 'a'][1]);//取最大右边
} else {左边界大于右边界 即分割
count = letter[s.charAt(i - 1) - 'a'][1] - letter[s.charAt(i - 1) - 'a'][0] + 1;
res.add(count);
}
}
// 每次划分片段都是在片段的下一个区间进行的,最后一个片段得单独处理
count = letter[s.charAt(s.length() - 1) - 'a'][1] - letter[s.charAt(s.length() - 1) - 'a'][0] + 1;
res.add(count);
return res;
}
}
②将字符串映射到LinkedHashMap中,key为出现过的字母,value为二维数组(存储key对应字母的区间索引),然后判断区间是否覆盖(两种方法差不多,映射到哈希数组耗时少些)
class Solution {
public List<Integer> partitionLabels(String s) {
List<Integer> list = new LinkedList<>();
LinkedHashMap<Character, int[]> map = new LinkedHashMap<>();
int[][] intervals = new int[s.length()][2];
//将字符串映射到map中,key为字母,value为字母所对应的区间
int index = 0;
for (int i = 0; i < s.length(); i++) {
if (map.containsKey(s.charAt(i))) {
map.get(s.charAt(i))[1] = i;
map.put(s.charAt(i), map.get(s.charAt(i)));
} else {//第一次遇到元素,将起始位置存入二维数组,其每一个元素是一维数组
intervals[index][0] = i;
intervals[index][1] = i;
map.put(s.charAt(i), intervals[index]);
index++;
}
}
int left = intervals[0][0];//左边界
int right = intervals[0][1];//右边界
for (int i = 1; i < intervals.length; i++) {
if (right < intervals[i][0]) {//无重叠
list.add(right - left + 1);
left = right + 1/*intervals[i][0]*/;//更新左边界
}
//不管是否重叠都需更新右边界
right = Math.max(right, intervals[i][1]);//更新最大右边界
}
// 每次划分片段都是在片段的下一个区间进行的,最后一个片段得单独处理
list.add(right - left + 1);
return list;
}
}
③使用一个for循环,更新右边界,当移动下标达到最大右边界时,说明已经找到了一个片段(与【45.跳跃游戏 II】有点像)耗时最少
- 在遍历的过程中相当于是要找每一个字母的边界,如果找到之前遍历过的所有字母的最远边界,说明这个边界就是分割点了。此时前面出现过所有字母,最远也就到这个边界了。
- 步骤:
- 使用一维数组只统计每一个字符最后出现的位置;
- 从头遍历字符,并更新字符的最远出现下标,如果找到字符最远出现位置下标和当前下标相等了,则找到了分割点。
class Solution {
public List<Integer> partitionLabels(String s) {
List<Integer> res = new LinkedList<>();
int[] edge = new int[26];
//for循环统计每个字母的最大右边界
for (int i = 0; i < s.length(); i++) {
edge[s.charAt(i) - 'a'] = i;
}
//找分割点,for循环中,更新右边界,当移动下标达到最大右边界时,说明已经找到了分割点
int left = 0;
int right = 0;
for (int i = 0; i < s.length(); i++) {
if (right < edge[s.charAt(i) - 'a']) right = edge[s.charAt(i) - 'a'];//更新最大右边界
//上一行代码可写成:
//right = Math.max(edge[s.charAt(i) - 'a'],right);
if (i == right) {//当移动下标达到最大右边界时,说明已经找到了分割点
res.add(right - left + 1);
left = right + 1;
}
}
return res;
}
}
56. 合并区间
本质其实还是判断重叠区间问题。
贪心算法
按照左边界排序,排序之后局部最优:每次合并都取最大的右边界,这样就可以合并更多的区间了,整体最优:合并所有重叠的区间。
按照重叠区间来比较,则最后一个区间需单独处理
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
class Solution {
public int[][] merge(int[][] intervals) {
//先将区间按左边界从小到大排序
Arrays.sort(intervals, (a, b) -> Integer.compare(a[0], b[0]));
List<int[]> res = new LinkedList<>();//临时存放不重叠的区间
int left = intervals[0][0];
int right = intervals[0][1];
//按照重叠区间来比较,则最后一个区间需单独处理
for (int i = 1; i < intervals.length; i++) {
if (right < intervals[i][0]) {//如果区间不重叠
res.add(new int[]{left, right});//加入区间
left = intervals[i][0];//left
}
right = Math.max(right, intervals[i][1]);//更新最大右边界
}
//最后一个区间需单独处理
res.add(new int[]{left, right});
int[][] res1 = new int[res.size()][2];
res.toArray(res1);
return res1;
}
}
时间复杂度 : O(NlogN) ,排序需要O(NlogN)
空间复杂度 : O(logN) ,java 的内置排序是快速排序,需要 O(logN)空间















 289
289

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









