







爬取网页总体概述:
1.使用urllib请求网页,获取网页源码。
2.使用bs4配合re正则表达式进行页面数据解析,获取到自己想要的数据。
3.使用pymysql保存到数据库或xlwt保存成excel文件。
温馨提示:学习之前需要先了解py基础知识,urllib库、网页相关知识、bs4库、re库、正则表达式、pymysql库、xlwt库等知识。这里推荐菜鸟教程,地址:点击查看。
一、urllib请求网页
1、通过urllib.request.Request构造request请求,可为request加各类参数,比如常添加的header信息。

2、将构造好的request请求放置urllib.request.urlopen方法中,方法会返回一个响应response。

3、使用response.read方法可以获取网页内容。

二、bs4解析html源码
1、使用BeautifulSoup去解析urllib获取到的html源码。

2、分析网页,使用find_all找到自己需要的html块。

三、re正则表达式筛选有用信息
1、使用re.compile方法构建正则表达式。(注意:加上r,避免不必要的字符被转义。)

2、将html块转换为字符串,通过re.findall+构建的表达式找到我们需要的数据。

四、保存数据(xlwt、pymysql使用)
1、通过xlwt保存到表格文件
(1)通过xlwt.Workbook创建xls表
(2)通过add_sheet创建sheet表
(3)通过write添加表头
(4)插入数据
2、通过pymysql保存到数据库
(1)初始化数据库
(2)生成游标,编写sql语句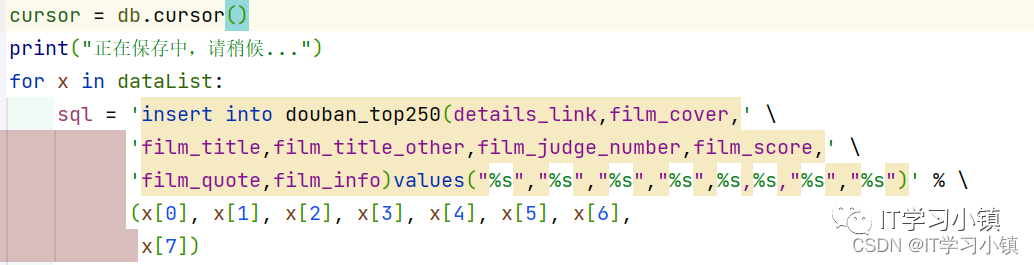
(3)执行sql语句
(4)关闭数据库
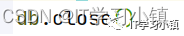
本文以爬取电影为例,编写了代码。源代码仅提供学习使用,请勿用于商业用途。
"IT学习小镇"号内回复“douban”即可获取源码。
















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











