







数据复制(数据密集型应用系统设计第五章)
一个可能出错的事物与一个不可能出错的事物之间的主要区别是, 当一个不可能出错的事物出错了, 通常也就意味着不可修复.
-----Douglas Adams, <<基本无害>> (1992)
为什么需要复制:
- 使数据在地理位置上更接近用户, 从而降低访问延迟
- 当部分组件出现故障, 系统依然可以继续工作, 从而提高可用性
- 扩展至多台机器以同时提供数据访问服务, 从而提高吞吐量
主节点和从节点
引入多副本后, 如何保证所有副本之间的数据是一致的?
常见的解决方案是 主从复制
- 指定某一副本为主副本, 当客户端写数据时, 必须将写请求发送给主副本
- 其他副本为从副本, 主副本将新数据写入本地存储, 然后将数据更改作为复制的日志发送给所有从副本, 每个从副本将更改日志严格按顺序应用到本地
- 客户读取数据时, 可以从主副本或从副本(一般是从副本)获取.
同步复制和异步复制
同步复制指的是主副本如果有写请求, 会将更改日志发送给所有从副本, 当有一个从副本写入成功后, 主副本即可返回客户写入成功, 不会等所有从副本写入成功才返回, 这样做的优势是主节点一旦发生故障, 从节点可以继续访问到最新的数据,缺点是需要等待从节点确认
异步复制
全异步模式如果主节点发生失败并且不可恢复, 那么所有尚未发送到从节点的更改日志会全部丢失, 优点是系统的吞吐性会更好, 这种看起来不靠谱的设计也被广泛使用, 特别是那些从节点数量巨大或分布在广域的地理环境中
加入新的从节点
假设有一个正在运行的系统, 为了提高容错能力考虑添加一个新的从节点, 因为数据是不断的在变化的, 如何确保新的从节点和主节点数据一致呢?
如果是锁定数据库(不让写入数据), 会违法高可用的目标
有一种不停机, 数据服务不中断的前提下完成从节点的加入
- 在某个时间点对主节点的数据副本产生一个快照, 这样能避免长时间锁定整个数据库
- 将此快照拷贝进新的从节点
- 从节点连接到主节点并请求获取快照点以后的更改日志
- 获得日志后从节点快速应用这些快照点之后的所有数据变更, 追赶到和主节点一致
节点失效
从节点失效: 追赶式恢复
- 从节点都保存了数据变更日志, 如果发生崩溃, 重启后根据日志位置, 从主节点获取之后的日志, 应用到本地
主节点失效: 节点切换
处理主节点故障比较棘手: 选择某个从节点将其提升为主节点, 客户端也要更新请求路由将写入数据发送到新的主节点, 然后其他从节点要接受来自新的主节点上数据变更日志
会遇到的问题:
- 如何选出新的主节点(一致性算法)
- 客户端如何将写请求发送到新的主节点(请求路由)
- 原节点重新恢复, 如何处理老的主节点和新的主节点(脑裂)
- 如何设置合理的心跳时间, 太短会导致很多不必要的切换, 太长则意味着总体恢复时间边长
复制日志的实现
-
基于语句的复制: 主节点记录所执行的每个写请求, 并将操作语句作为日志发送给从节点, 例如 insert, update, delete, 方式简单, 但是有一些不适用的场景
- 任何调用非确定性函数的语句, 例如 NOW() 或 RAND(), 可能在不同的副本上产生不同的值
- 如果语句中使用了自增列, 或依赖现有的数据, 例如: Update … Where 某些条件, 如果并发执行, 会产生不同的结果
- 有副作用的语句, 例如触发器, 存储过程, 用户定义的函数等
有一些可以采取措施, 比如当调用非确定性函数时, 将确定值记录在日志中, 但由于不确定性因素很多, 所以目前通常首选其他方案
-
基于预写日志(WAL)传输
- 对于日志结构的存储引擎(LSM-Tree) , 追加写日志, 然后后台合并日志
- 对于采用覆盖写的 Btree, 每次修改预先写入日志, 如果发生崩溃, 恢复后以更新索引的方式恢复到此前一致性状态
-
基于行的逻辑日志复制
-
对于行的插入, 日志包含所有相关列的新值
-
对弈行的删除, 日志里有一个标识行删除, 通常是主键
-
对于行的更新, 日志有一个值标识更新的行以及更新字段的新值
-
如果是一条事务, 则会产生多个上面的记录, 并在后面跟一个提交记录, 表示该事务已提交
Mysql 的 binlog 使用的就是基于行的复制, 好处是逻辑日志和存储引擎解耦, 能运行不同版本的存储引擎
复制滞后问题
上面提到的主从复制, 无论是同步复制还是异步复制, 总会有个别情况用户读从节点时候, 从节点还没来得及应用到主节点发来的更改日志, 虽然最后从节点会追赶上来, 但是用户显然是不高兴的
读自己的写
在一些场景中, 可以判断用户写完数据会立马读自己的数据, 例如发表博客, 提交评论等, 可以配置规则使这些用户写完立马查询的是主节点, 但是如果是同一用户多个设备访问数据, 例如 web 端修改完文章, 然后手机端读, 且 web 端连接 wifi, 手机端连接蜂窝移动网络, 这样就比较难判断
单调读
在一个从节点很多的集群里, 假定用户对不同的从副本进行了多次读取, 先是看到了用户有一条评论, 然后刷新页面后这条评论消失了, 用户会感到很困惑
单调读一致性确保不会发生这种异常, 实现方式是
确保每个用户总是从固定的副本执行读取, 例如基于用户 id 的哈希方法选择副本, 而不是随机选择副本, 但是有一个问题, 假如用户哈希的副本发生失效, 则必须路由到另一个副本
-
复制滞后的解决方案
多主节点复制: 到目前为止, 发生的问题都是依赖单个主节点的主从架构
这个架构存在一个明显的缺点: 系统只有一个主节点, 如果某种原因主从之间的网络中断, 主从复制方案就会影响所有的写入操作, 可以配置多个主节点, 每个主节点都能接受从写请求, 同时, 每个主节点还是其他主节点的从节点
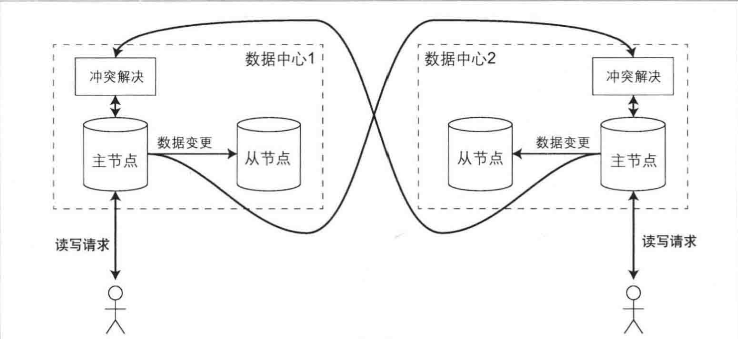
优势: 多主模型中, 每个写操作都可以在本地数据中心快速响应, 用户体验更好. 如果某个区域的主节点发生故障, 其他数据中心可以继续运行, 网络容忍方面, 数据中心之间的复制是异步复制, 不依赖网络延迟, 会最终写入成功
缺点: 不同的数据中心可能会同时修改相同的数据, 必须要有解决冲突的手段














 1693
1693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









