






傲视群雄的BERT
2018年的10月11日,Google发布的论文《Pre-training of Deep Bidirectional Transformers for Language Understanding》,成功在 11 项 NLP 任务中取得 state of the art 的结果,赢得自然语言处理学界的一片赞誉之声。
本文将从原理上来讨论BERT为什么可以在2022年的今天还能被大家广泛使用,并且各种魔改版本依旧盛行在各种比赛当中,其中不乏效果很好的版本。
何为BERT
1、BERT的结构
BERT全称为Pre-training of Deep Bidirectional Transformers for Language Understanding按字面意思可以理解为一种基于预训练的双向transformer模型,但其实,BERT中仅仅只用到了Transformer中的Encoder也就是编码部分,BERT的具体结构如下图: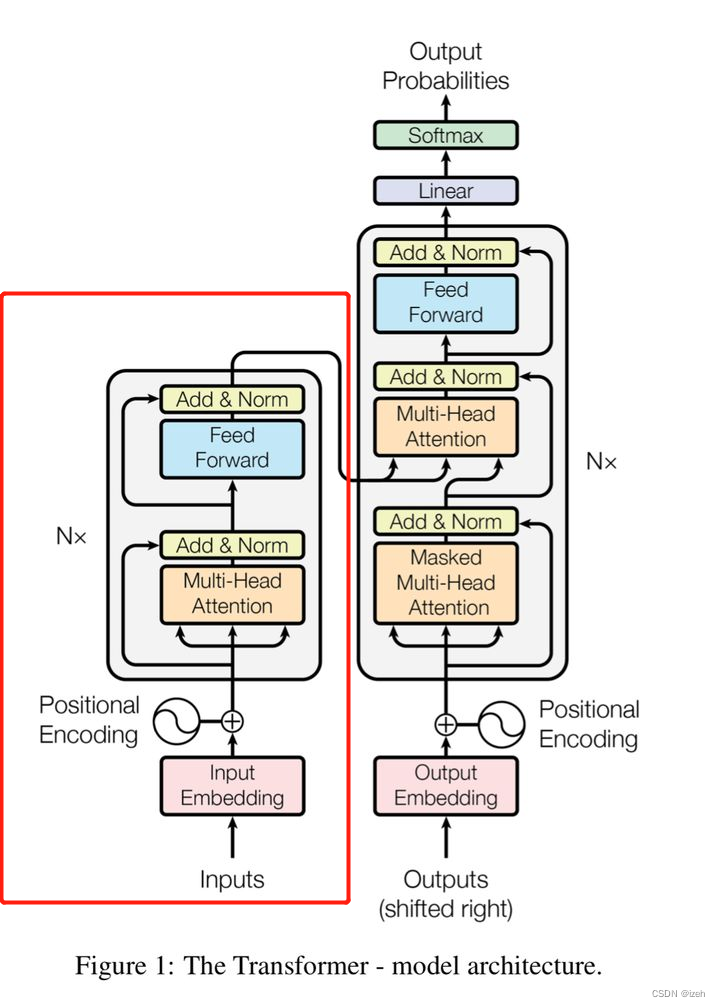 红色方框圈出来的就是BERT模型使用的Transformer的Encoder部分,而BERT对于Encoder的双向构建则如下图所示:
红色方框圈出来的就是BERT模型使用的Transformer的Encoder部分,而BERT对于Encoder的双向构建则如下图所示:
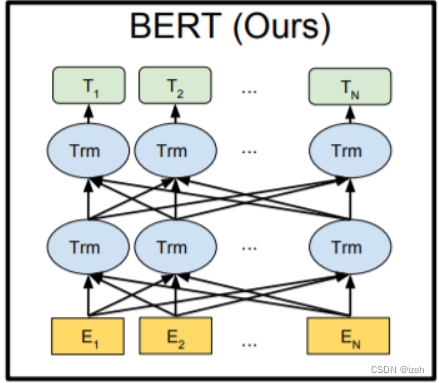
2、BERT的训练
和RNN、LSTM等传统的自回归语言模型不同是,BERT采用的是一种叫做自编码类型的训练方式,并且包含两个预训练任务:掩码语言模型(Masked Language Model, MLM)和下一个句子预测 ( Next Sentence Prediction,NSP),如下图所示: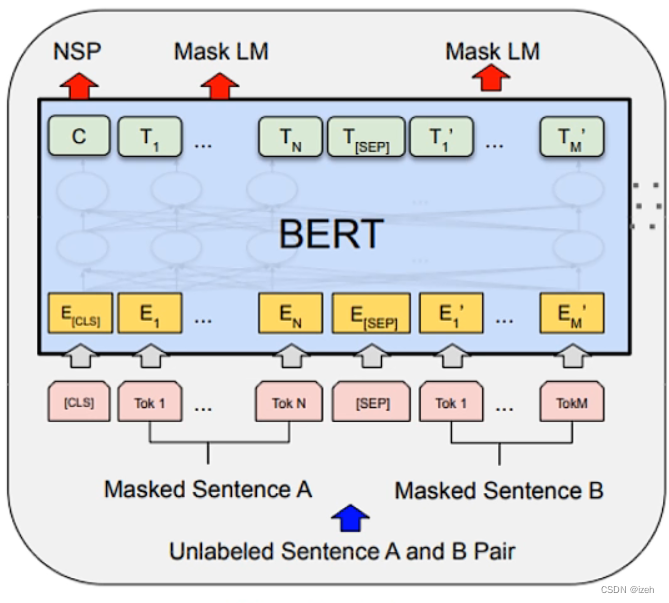
BERT为什么有效
BERT 模型依赖 Transformer 结构,其主要由多层自注意力网络层堆叠而成(含残差连接)。而自注意力的本质事实上是对词(或标记)与词之间关 系的刻画。不同类型的关系可以表达丰富的语义,例如名词短语内的依存关系、句法依存关系和指代关系等。而这些关系特征对于大部分语义理解类自然语言处理任务具有关键的作用。因此,自注意力的分析将有助于理解BERT模型对于关系(relational)
特征的学习能力。
BERT的使用
以BERT、GPT 等为代表的预训练技术为自然语言处理领域带来了巨大的变革。为了能够从大规模数据中充分地汲取知识,作为“容器”的预训练模型通常也需要具备相当大的规模。例如,BERT 模型含有上亿个参数,而 OpenAI 发布的GPT-3 模型更是达到了惊人的千亿级参数。尽管这些大规模的预训练模型在很多任务上表现优异,但是庞大的模型体量也使得其预测行为变得更加难以 〝理解”以及“不可控”。
而笔者在刚刚涉及深度学习的过程中也曾经尝试过使用自己搭建的BERT模型从零开始训练,可是因为设备和数据集的限制,模型预测效果令人汗颜。
一次笔者在网络中无意中发现了一个神奇的网站,他就是虽然笔者当时不知道,但其实早已大名鼎鼎的Huggingface。
Huggingface总部位于纽约,是一家专注于自然语言处理、人工智能和分布式系统的创业公司。他们所提供的聊天机器人技术一直颇受欢迎,但更出名的是他们在NLP开源社区上的贡献。Huggingface一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, state-of-the-art)的NLP技术,而非困窘于训练资源的匮乏。同时Hugging Face专注于NLP技术,拥有大型的开源社区。尤其是在github上开源的自然语言处理,预训练模型库 Transformers,已被下载超过一百万次,github上超过24000个star。Transformers 提供了NLP领域大量state-of-art的 预训练语言模型结构的模型和调用框架。
1、任务与数据集
本文采用的任务是文本分类任务中的情感分类,即给出一个句子,判断出它所表达的情感是积极的(用1表示)还是消极的(用0表示)。这里所使用的数据集是斯坦福大学所发布的一个情感分析数据集SST,其组成成分来自于电影的评论。在开始之前,我们需要先安装transformers,直接在pip上安装即可:
pip install transformers
然后加载我们需要用到的一些库:
import torch
import warnings
import numpy as np
import pandas as pd
import transformers as tfs
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
2、加载数据集
train_df = pd.read_csv('https://github.com/clairett/pytorch-sentiment-classification/raw/master/data/SST2/train.tsv', delimiter='\t', header=None)
train_set = train_df[:3000] #取其中的3000条数据作为我们的数据集
print("Train set shape:", train_set.shape)
train_set[1].value_counts() #查看数据集中标签的分布
得到以下输出:
Train set shape: (3000, 2)
1 1565
0 1435
Name: 1, dtype: int64
可以看到数据分布是比较均匀的。
请注意:我们使用[:,0,:]来提取序列第一个位置的输出向量,因为第一个位置是[CLS],比起其他位置,该向量应该更具有代表性,蕴含了整个句子的信息。紧接着,我们利用sklearn库的方法来把数据集切分成训练集和测试集。
3、建立模型
#part 2 - bert fine-tuned
import torch
from torch import nn
from torch import optim
import transformers as tfs
import math
class BertClassificationModel(nn.Module):
def __init__(self):
super(BertClassificationModel, self).__init__()
model_class, tokenizer_class, pretrained_weights = (tfs.BertModel, tfs.BertTokenizer, 'bert-base-uncased')
self.tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
self.bert = model_class.from_pretrained(pretrained_weights)
self.dense = nn.Linear(768, 2) #bert默认的隐藏单元数是768, 输出单元是2,表示二分类
def forward(self, batch_sentences):
batch_tokenized = self.tokenizer.batch_encode_plus(batch_sentences, add_special_tokens=True,
max_len=66, pad_to_max_length=True) #tokenize、add special token、pad
input_ids = torch.tensor(batch_tokenized['input_ids'])
attention_mask = torch.tensor(batch_tokenized['attention_mask'])
bert_output = self.bert(input_ids, attention_mask=attention_mask)
bert_cls_hidden_state = bert_output[0][:,0,:] #提取[CLS]对应的隐藏状态
linear_output = self.dense(bert_cls_hidden_state)
return linear_output
4、数据分批
下面我们对原来的数据集进行一些改造,分成batch_size为64大小的数据集,以便模型进行批量梯度下降。
sentences = train_set[0].values
targets = train_set[1].values
train_inputs, test_inputs, train_targets, test_targets = train_test_split(sentences, targets)
batch_size = 64
batch_count = int(len(train_inputs) / batch_size)
batch_train_inputs, batch_train_targets = [], []
for i in range(batch_count):
batch_train_inputs.append(train_inputs[i*batch_size : (i+1)*batch_size])
batch_train_targets.append(train_targets[i*batch_size : (i+1)*batch_size])
5、训练模型
#train the model
epochs = 3
lr = 0.01
print_every_batch = 5
bert_classifier_model = BertClassificationModel()
optimizer = optim.SGD(bert_classifier_model.parameters(), lr=lr, momentum=0.9)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
print_avg_loss = 0
for i in range(batch_count):
inputs = batch_train_inputs[i]
labels = torch.tensor(batch_train_targets[i])
optimizer.zero_grad()
outputs = bert_classifier_model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print_avg_loss += loss.item()
if i % print_every_batch == (print_every_batch-1):
print("Batch: %d, Loss: %.4f" % ((i+1), print_avg_loss/print_every_batch))
print_avg_loss = 0
这里我们用测试数据集对已经训练好的模型进行评价,并打印其准确率,笔者的模型最后的准确率是:90.43%
可以看出,通过微调的方式来建模,经过3个轮次的训练后,模型的准确率达到了90.53%,比起基于特征的建模方式有了较大提升。下面给出本文代码的地址,有需要的可以自取~谢谢您的阅读!
















 9501
9501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









