







第六章就来学习一下Flink的状态(Checkpoint和Savepoint)容错与两阶段提交。
问题整理:
1. 什么是Flink的状态?状态后端?状态容错机制?
2. 什么是Flink的Checkpoints?
3. 什么是Flink的Savepoints?
4. Flink的两阶段提交又是什么?
5. Flink的Checkpoint怎么优化?
1. 状态与容错
在 Flink 的框架中,进行有状态的计算是 Flink 最重要的特性之一。所谓的状态,其实指的是 Flink 程序的中间计算结果。Flink 支持了不同类型的状态,并且针对状态的持久化还提供了专门的机制和状态管理器。
1.1 状态
Flink 的官方博客中这也描述:所谓的状态指的是,在流处理过程中那些需要记住的数据,而这些数据既可以包括业务数据,也可以包括元数据。Flink 本身提供了不同的状态管理器来管理状态,并且这个状态可以非常大。
Flink 的状态数据可以存在 JVM 的堆内存或者堆外内存中,当然也可以借助第三方存储,例如 Flink 已经实现的对 RocksDB 支持。Flink 的官网同样给出了适用于状态计算的几种情况:
- When an application searches for certain event patterns, the state will store the sequence of events encountered so far
- When aggregating events per minute/hour/day, the state holds the pending aggregates
- When training a machine learning model over a stream of data points, the state holds the current version of the model parameters
- When historic data needs to be managed, the state allows efficient access to events that occurred in the past
以上四种情况分别是:复杂事件处理获取符合某一特定时间规则的事件、聚合计算、机器学习的模型训练、使用历史的数据进行计算。
1.2 Flink 状态分类和使用
在 Flink 中,根据数据集是否按照某一个 Key 进行分区,将状态分为 Keyed State 和 Operator State(Non-Keyed State)两种类型。
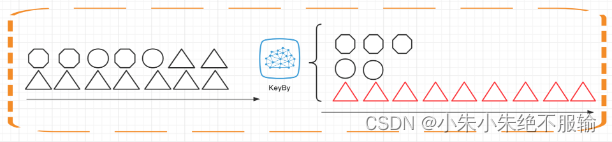
如上图所示,Keyed State 是经过分区后的流上状态,每个 Key 都有自己的状态,图中的八边形、圆形和三角形分别管理各自的状态,并且只有指定的 key 才能访问和更新自己对应的状态。
与 Keyed State 不同的是,Operator State 可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。每个算子子任务上的数据共享自己的状态。
但是有一点需要说明的是,无论是 Keyed State 还是 Operator State,Flink 的状态都是基于本地的,即每个算子子任务维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。
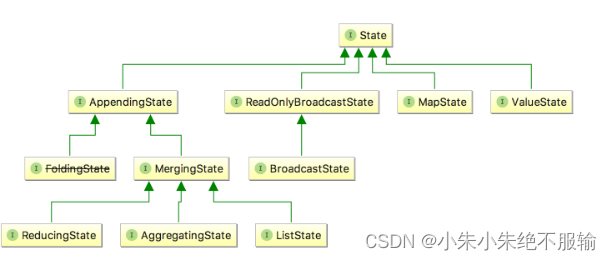
我们可以看一下 State 的类图,对于 Keyed State,Flink 提供了几种现成的数据结构供我们使用,State 主要有四种实现,分别为 ValueState、MapState、AppendingState 和 ReadOnlyBrodcastState ,其中 AppendingState 又可以细分为 ReducingState、AggregatingState 和 ListState。
那么我们怎么访问这些状态呢?Flink 提供了 StateDesciptor 方法专门用来访问不同的 state。这里就不做详细解释了。
Operator State 的实际应用场景不如 Keyed State 多,一般来说它会被用在 Source 或 Sink 等算子上,用来保存流入数据的偏移量或对输出数据做缓存,以保证 Flink 应用的 Exactly-Once 语义。
同样,我们对于任何状态数据还可以设置它们的过期时间。如果一个状态设置了 TTL,并且已经过期,那么我们之前保存的值就会被清理。
想要使用 TTL,我们需要首先构建一个 StateTtlConfig 配置对象;然后,可以通过传递配置在任何状态描述符中启用 TTL 功能。
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(10))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
descriptor.enableTimeToLive(ttlConfig);
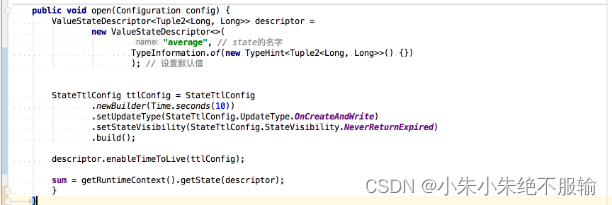
StateTtlConfig 这个类中有一些配置需要我们注意:

UpdateType 表明了过期时间什么时候更新,而对于那些过期的状态,是否还能被访问则取决于 StateVisibility 的配置。
1.3 状态后端种类和配置
在上面的内容中讲到了 Flink 的状态数据可以存在 JVM 的堆内存或者堆外内存中,当然也可以借助第三方存储。默认情况下,Flink 的状态会保存在 taskmanager 的内存中,Flink 提供了三种可用的状态后端用于在不同情况下进行状态后端的保存。
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
MemoryStateBackend
顾名思义,MemoryStateBackend 将 state 数据存储在内存中,一般用来进行本地调试用,我们在使用 MemoryStateBackend 时需要注意的一些点包括:
每个独立的状态(state)默认限制大小为 5MB,可以通过构造函数增加容量,状态的大小不能超过akka的Framesize大小,聚合后的状态必须能够放进JobManager的内存中.
MemoryStateBackend 可以通过在代码中显示指定:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false));
其中,new MemoryStateBackend(DEFAULT_MAX_STATE_SIZE,false) 中的 false 代表关闭异步快照机制。
很明显 MemoryStateBackend 适用于我们本地调试使用,来记录一些状态很小的 Job 状态信息。
FsStateBackend
FsStateBackend 会把状态数据保存在 TaskManager 的内存中。CheckPoint 时,将状态快照写入到配置的文件系统目录中,少量的元数据信息存储到 JobManager 的内存中。
使用 FsStateBackend 需要我们指定一个文件路径,一般来说是 HDFS 的路径,例如,hdfs://namenode:40010/flink/checkpoints。
我们同样可以在代码中显示指定:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints", false));
FsStateBackend 因为将状态存储在了外部系统如 HDFS 中,所以它适用于大作业、状态较大、全局高可用的那些任务。
RocksDBStateBackend
RocksDBStateBackend 和 FsStateBackend 有一些类似,首先它们都需要一个外部文件存储路径,比如 HDFS 的 hdfs://namenode:40010/flink/checkpoints,此外也适用于大作业、状态较大、全局高可用的那些任务。
但是与 FsStateBackend 不同的是,RocksDBStateBackend 将正在运行中的状态数据保存在 RocksDB 数据库中,RocksDB 数据库默认将数据存储在 TaskManager 运行节点的数据目录下。
这意味着,RocksDBStateBackend 可以存储远超过 FsStateBackend 的状态,可以避免向 FsStateBackend 那样一旦出现状态暴增会导致 OOM,但是因为将状态数据保存在 RocksDB 数据库中,吞吐量会有所下降。
此外,需要注意的是,RocksDBStateBackend 是唯一支持增量快照的状态后端。
2. Checkpoints(检查点)
2.1 Checkpoints
Flink中基于异步轻量级的分布式快照技术提供了Checkpoints容错机制,Checkpoints可以将同一时间点作业/算子的状态数据全局统一快照处理,包括前面提到的算子状态和键值分区状态。当发生了故障后,Flink会将所有任务的状态恢复至最后一次Checkpoint中的状态,并从那里重新开始执行。
那么Checkpoints的生成策略是什么样的呢?它会在什么时候进行快照的生成呢?
其实就是在所有任务都处理完同一个输入数据流的时候,这时就会对当前全部任务的状态进行一个拷贝,生成Checkpoints。
为了方便理解,这里先简单的用一个朴素算法来解释这一生成过程(Flink的Checkpoints算法实际要更加复杂,在下面会详细讲解)
- 暂停接受所有输入流。
- 等待已经流入系统的数据被完全处理,即所有任务已经处理完所有的输入数据。
- 将所有任务的状态拷贝到远程持久化,生成Checkpoints。在所有任务完成自己的拷贝工作后,Checkpoints生成完毕。
- 恢复所有数据流的接收。
2.2 恢复流程
为了方便进行实例的讲解,假设当前有一个Source任务,负责从一个递增的数字流(1、2、3、4……)中读取数据,读取到的数据会分为奇数流和偶数流,求和算子的两个任务会分别对它们进行求和。在当前任务中,数据源算子的任务会将输入流的当前偏移量存为状态,求和算子的任务会将当前和存为状态。
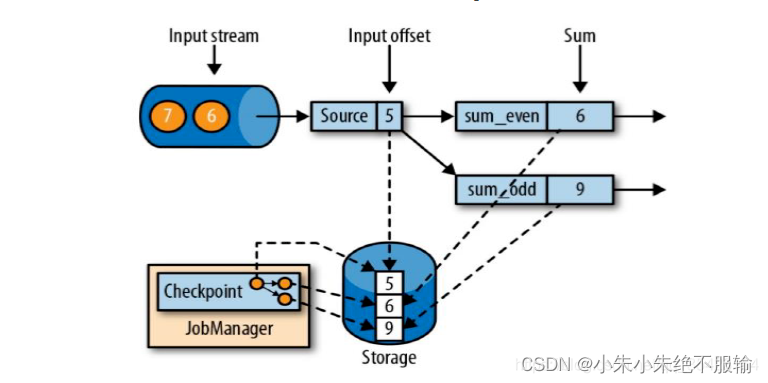
如上图,在当前生成的Checkpoints中保存的输入偏移为5,偶数求和为6,奇数求和为9。
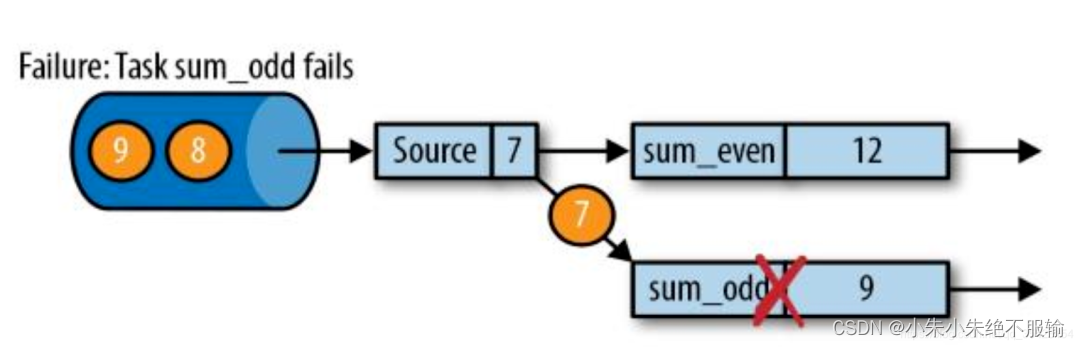
假设在下一轮计算中,任务sum_odd计算出现了问题,任务sum_odd的时候产生了问题,导致结果出现错误。由于出现问题,为了防止从头开始重复计算,此时会通过Checkpoints来进行快照的恢复。
Checkpoints恢复应用需要以下三个步骤:
- 重启整个应用
- 利用最新的检查点重置任务状态
- 恢复所有任务的处理
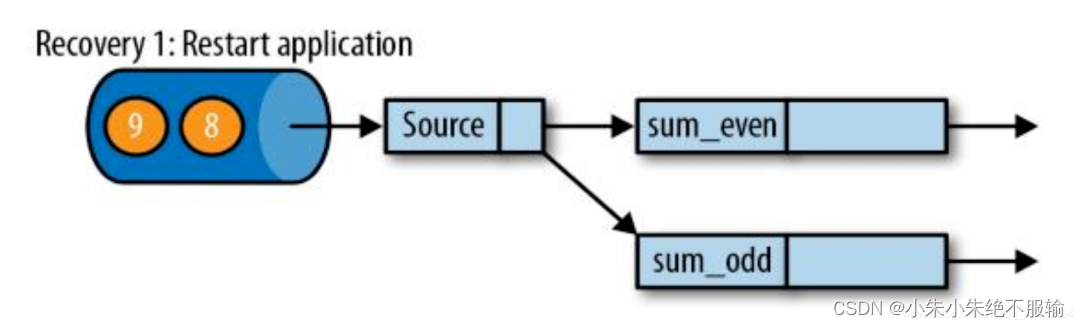
恢复步骤1:重启应用
恢复步骤2:从检查点重置任务状态
第一步我们需要先重启整个应用,恢复到最原始的状态。
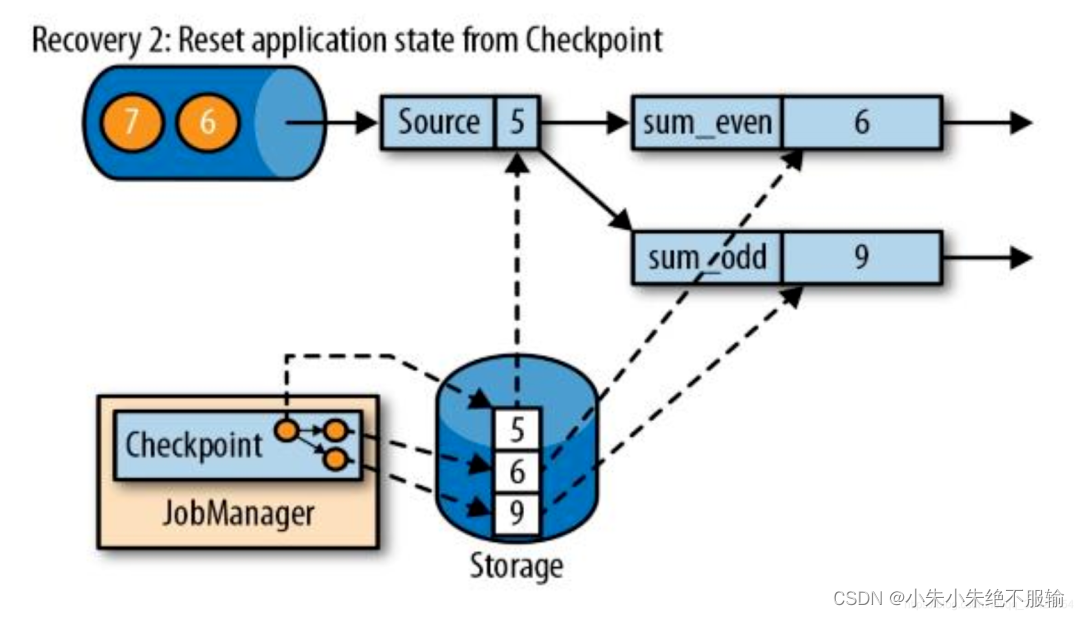
紧接着从检查点的快照信息中读取出输入源的偏移量以及算子计算的结果,进行状态的恢复。
恢复步骤3:继续处理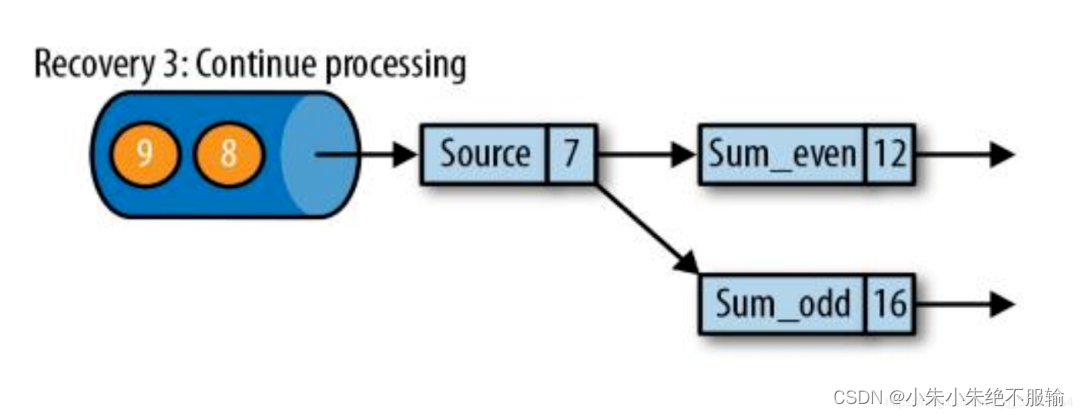
状态恢复完成后,继续Checkpoints恢复的位置开始继续处理。
从检查点恢复后,它的内部状态会和生成检查点的时候完全一致,并且会紧接着重新处理那些从之前检查点完成开始,到发生系统故障之间已经处理过的数据。虽然这意味着Flink会重复处理部分消息,但上述机制仍然可以实现精确一次的状态一致性,因为所有的算子都会恢复到那些数据处理之前的时间点。
但这个机制仍然面临一些问题,因为Checkpoints和恢复机制仅能重置应用内部的状态,而应用所使用的Sink可能在恢复期间将结果向下游系统(如事件日志系统、文件系统或数据库)重复发送多次。
为了解决这个问题,对于某些存储系统,Flink提供的Sink函数支持精确一次输出(在检查点完成后才会把写出的记录正式提交)。另一种方法则是适用于大多数存储系统的幂等更新。
2.3 生成策略
Flink中的Checkpoints是基于Chandy-Lamport分布式快照算法实现的,该算法不会暂停整个应用,而是会将生成Checkpoints的过程和处理过程分离,这样在部分任务持久化状态的过程中,其他任务还可以继续执行。
在介绍生成策略之前,首先需要介绍一下Checkpoints barrier(屏障)这一种特殊记录。
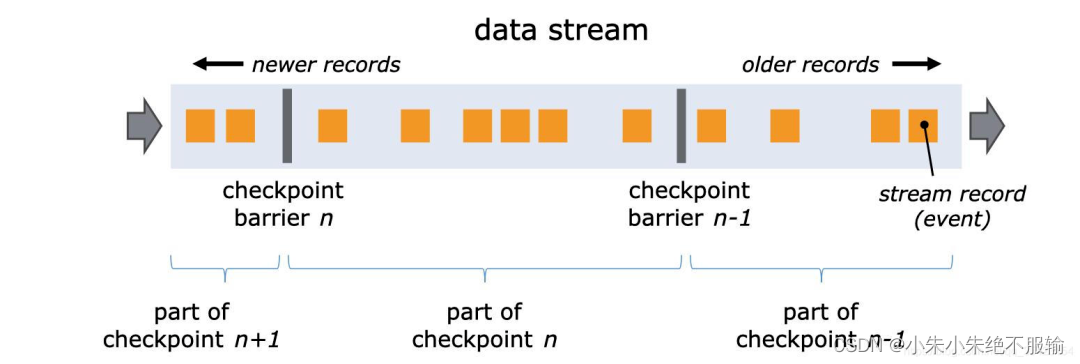
如上图,与水位线相同,Flink会在Source中间隔性地生成barrier,通过barrier把一条流上的数据划分到不同的Checkpoints中,在barrier之前到来的数据导致的状态更改,都会被包含在当前所属的Checkpoints中;而基于barrier之后的数据导致的所有更改,就会被包含在之后的Checkpoints中。
拥有两个有状态的Source,两个有状态的任务,以及两个无状态Sink的流式应用
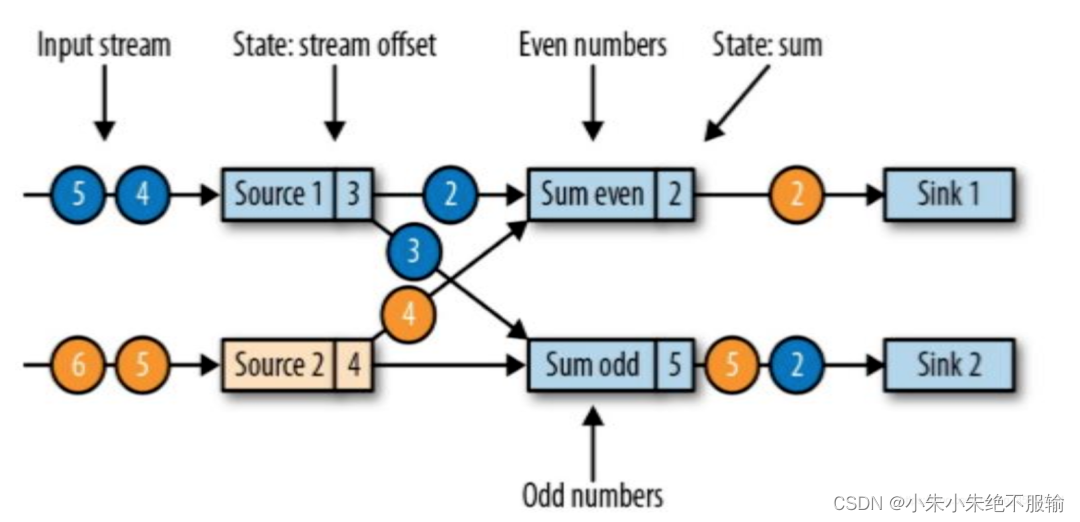
- 假设当前有两个Source任务,各自消费一个递增的数字流(1、2、3、4……),读取到的数据会分为奇数流和偶数流,求和算子的两个任务会分别对它们进行求和,并将结果值更新至下游Sink。
JobManager通过向所有Source发送消息来启动Checkpoints生成流
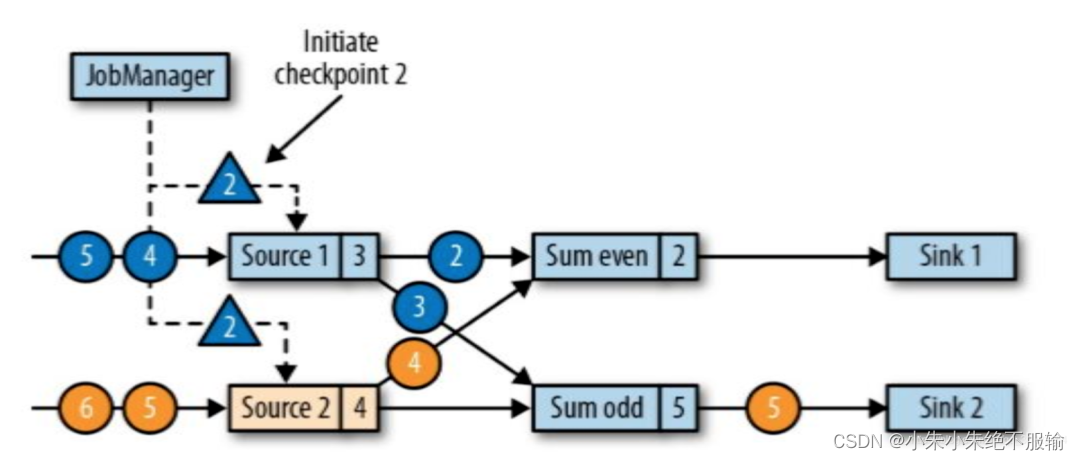
- 此时JobManager向每一个Source任务发送一个新的Checkpoints编号,以此启动Checkpoints生成流程。
Source为状态生成Checkpoints并发出Checkpoints barrier
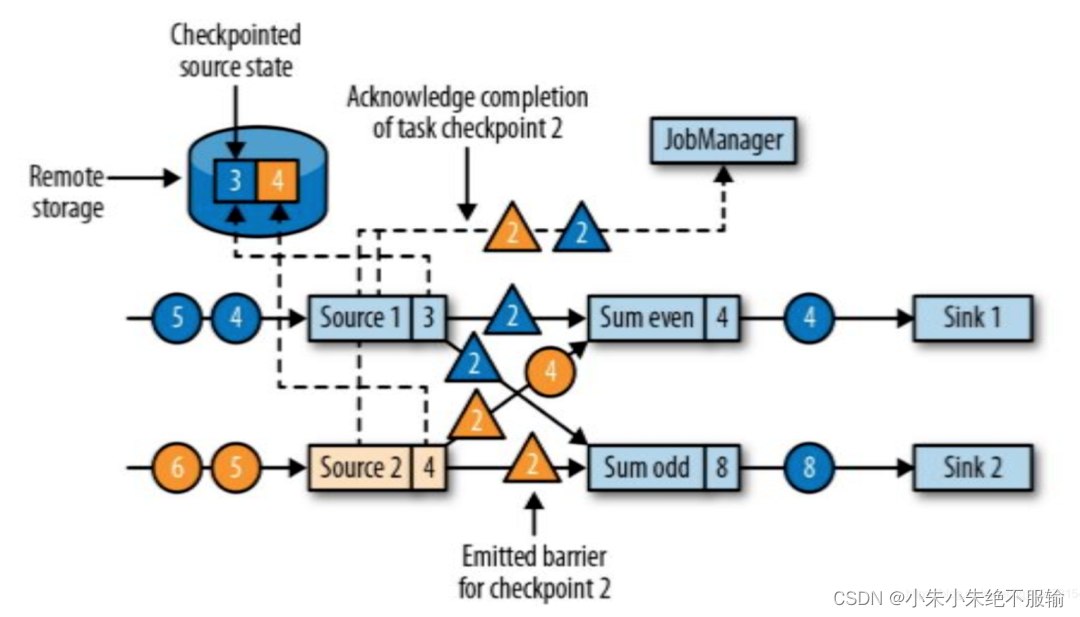
- 在Source任务收到消息后,会暂停发出记录,紧接着利用状态后端生成本地状态的Checkpoints,并把barrier连同编号广播给所有传出的数据流分区。
- 状态后端在状态存入Checkpoints后通知Source任务,并向JobManager发送确认消息。
- 在所有barrier发出后,Source将恢复正常工作。
任务等待接受所有输入分区的barrier,来自己接受barrier输入分区的记录会被缓存,其他记录按照常规处理
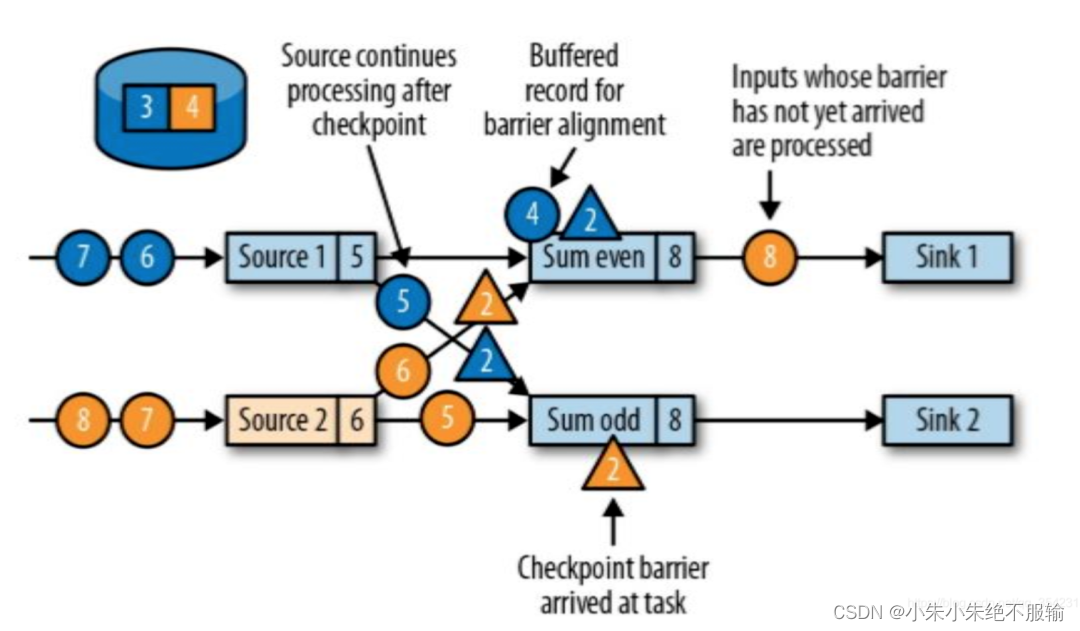
- Source任务会广播barrier至所有与之相连的任务,确保这些任务能从它们的每个输入都收到一个barrier
- 在等待过程中,对于barrier未到达的分区,数据会继续正常处理。而barrier已经到达的分区,它们新到来的记录会被缓冲起来,不能处理。这个等待所有barrier到来的过程被称为barrier对齐
任务在收到全部barrier后将状态存入Checkpoints,然后向下游转发Checkpoints barrier
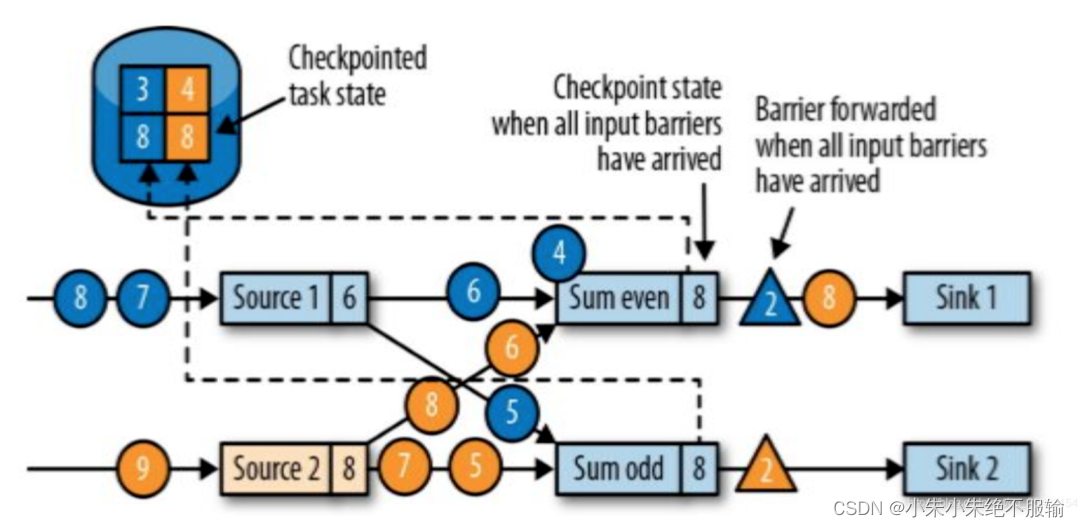
任务中收齐全部输入分区发送的barrier后,就会通知状态后端开始生成Checkpoints,同时继续把Checkpoints barrier广播转发到下游相连的任务。
任务在转发Checkpoints barrier后继续进行常规处理
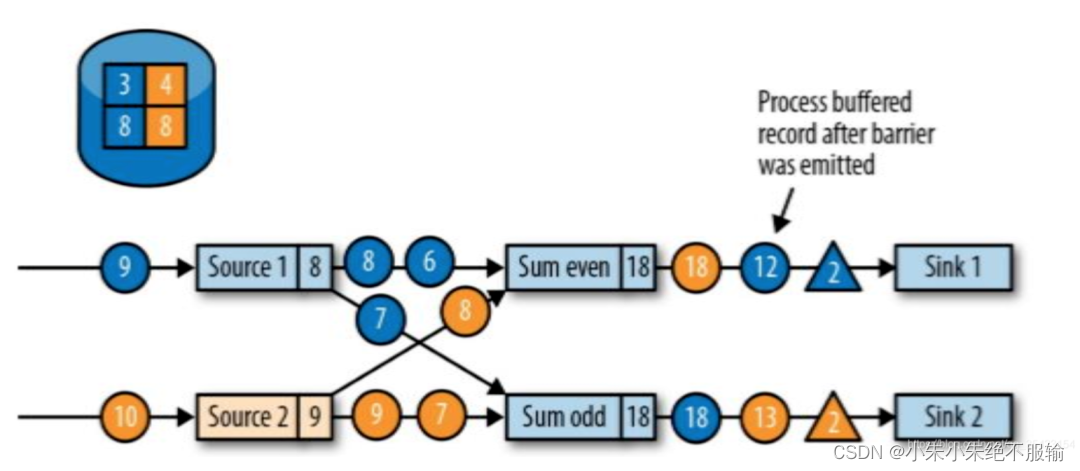
- 任务在发出所有的Checkpoints barrier后就会开始处理缓冲的记录。等到所有缓冲记录处理完后,任务就会继续处理Source。
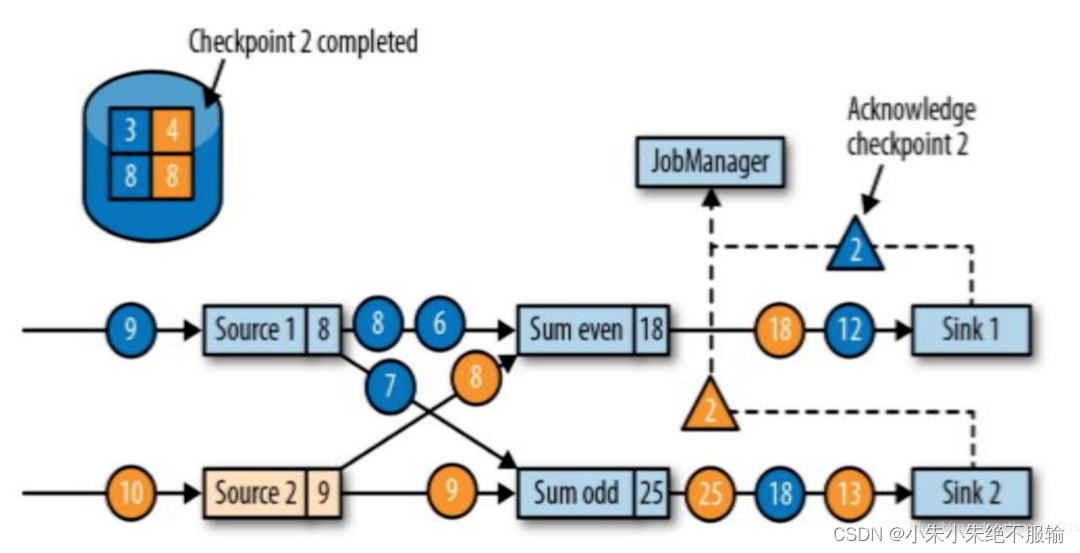
Sink任务向JobManager确认收到Checkpoints barrier,在所有任务成功将自身状态存入Checkpoints后整个应用的Checkpoints才算完成。
- Sink任务在收到分隔符后会依次进行barrier对齐,然后将自身状态写入Checkpoints,最终向JobManager发送确认信息。
- JobManager在接收到所有任务返回的Checkpoints确认信息后,就说明此次Checkpoints生成结束。
3. Savepoints(保存点)
- 由于Cheakpoints是周期性自动生成的,但有些时候我们需要手动的去进行镜像保存功能,于是Flink同时还为我们提供了Savepoints来完成这个功能,Savepoints不仅可以做到故障恢复,还可以用于手动备份、版本迁移、暂停或重启应用等。
- Savepoints是Checkpoints的一种特殊实现,底层也是使用Checkpoint机制,因此Savepoints可以认为是具有一些额外元数据的Checkpoints。
- Savepoints的生成和清理都无法由Flink自动进行,因此都需要用户自己来显式触发。
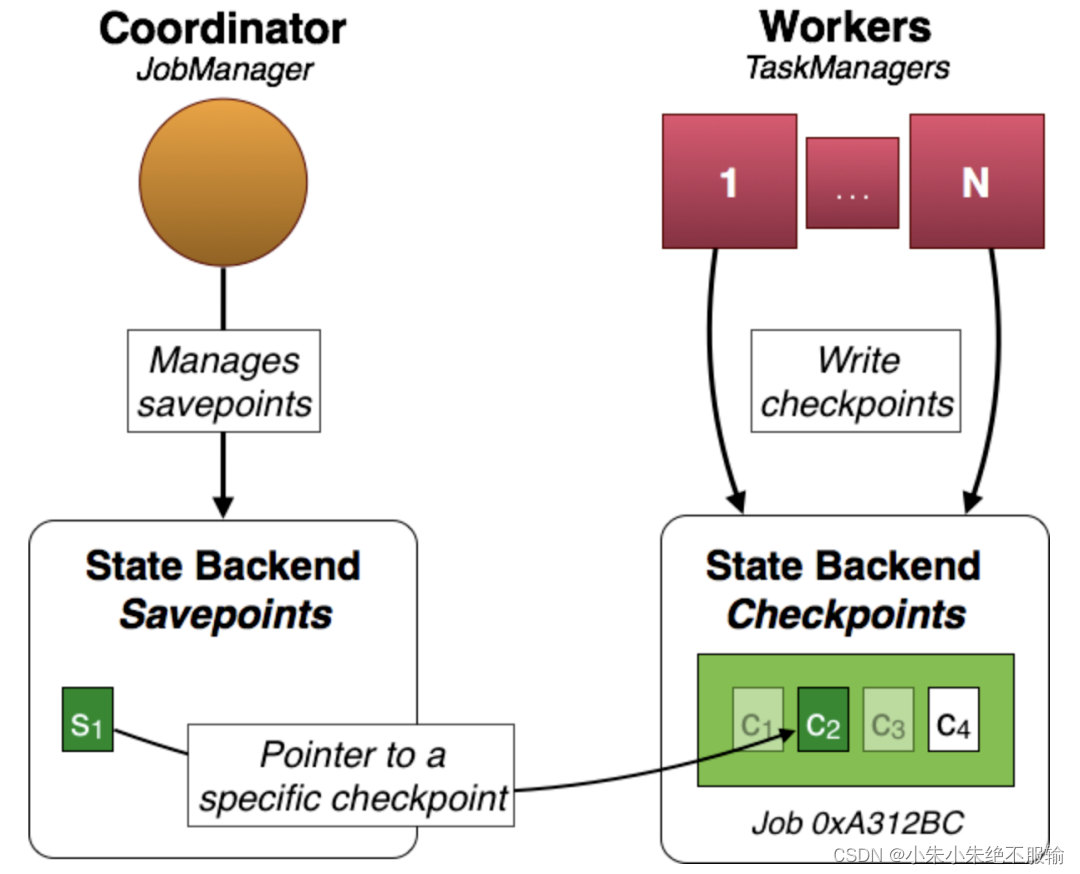
总结一下Checkpoint和Savepoint的区别和联系:
- checkpoint的侧重点是“容错”,即Flink作业意外失败并重启之后,能够直接从早先打下的checkpoint恢复运行,且不影响作业逻辑的准确性。而savepoint的侧重点是“维护”,即Flink作业需要在人工干预下手动重启、升级、迁移或A/B测试时,先将状态整体写入可靠存储,维护完毕之后再从savepoint恢复现场。
- savepoint是“通过checkpoint机制”创建的,所以savepoint本质上是特殊的checkpoint。
- checkpoint面向Flink Runtime本身,由Flink的各个TaskManager定时触发快照并自动清理,一般不需要用户干预;savepoint面向用户,完全根据用户的需要触发与清理。
- checkpoint的频率往往比较高(因为需要尽可能保证作业恢复的准确度),所以checkpoint的存储格式非常轻量级,但作为trade-off牺牲了一切可移植(portable)的东西,比如不保证改变并行度和升级的兼容性。savepoint则以二进制形式存储所有状态数据和元数据,执行起来比较慢而且“贵”,但是能够保证portability,如并行度改变或代码升级之后,仍然能正常恢复。
- checkpoint是支持增量的(通过RocksDB),特别是对于超大状态的作业而言可以降低写入成本。savepoint并不会连续自动触发,所以savepoint没有必要支持增量。
4. 两阶段提交
假设一种场景,从Kafka Source拉取数据,经过一次窗口聚合,最后将数据发送到Kafka Sink,如下图:
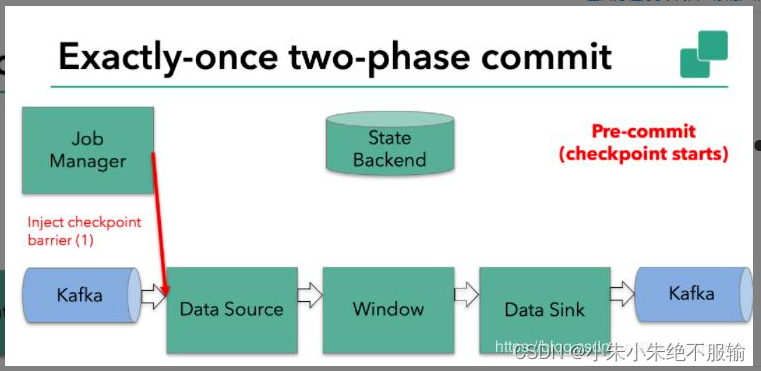
- JobManager向Source发送Barrier,开始进入pre-Commit阶段,当只有内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些已定义的状态变量即可。当chckpoint成功时Flink负责提交这些写入,否则就终止取消掉它们。
- 当Source收到Barrier后,将自身的状态进行保存,后端可以根据配置进行选择,这里的状态是指消费的每个分区对应的offset。然后将Barrier发送给下一个Operator。
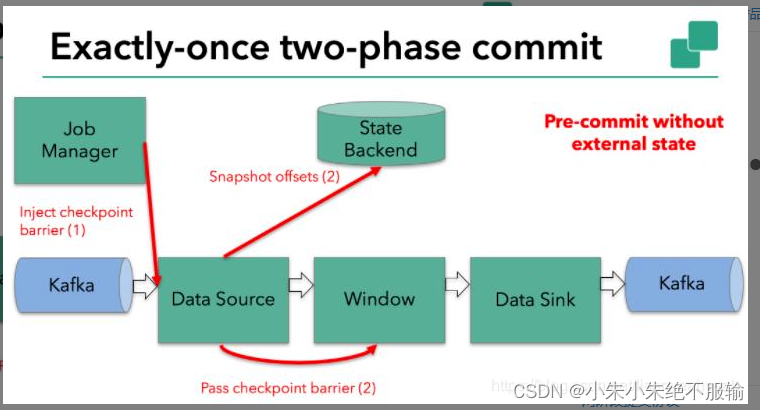
3. 当Window这个Operator收到Barrier之后,对自己的状态进行保存,这里的状态是指聚合的结果(sum或count的结果),然后将Barrier发送给Sink。Sink收到后也对自己的状态进行保存,之后会进行一次预提交。
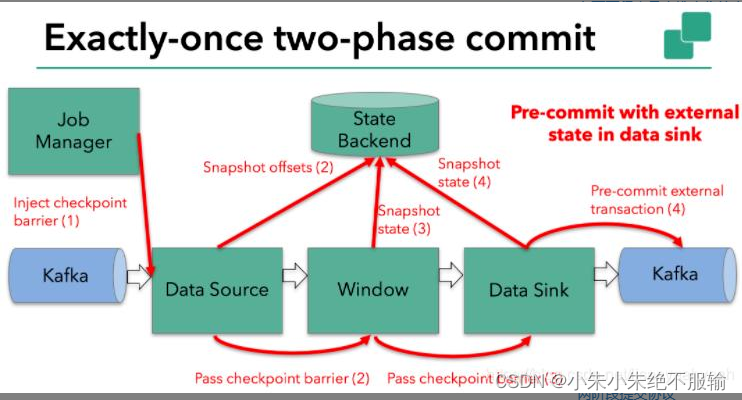
4. 预提交成功后,JobManager通知每个Operator,这一轮检查点已经完成,这个时候,会进行第二次Commit。
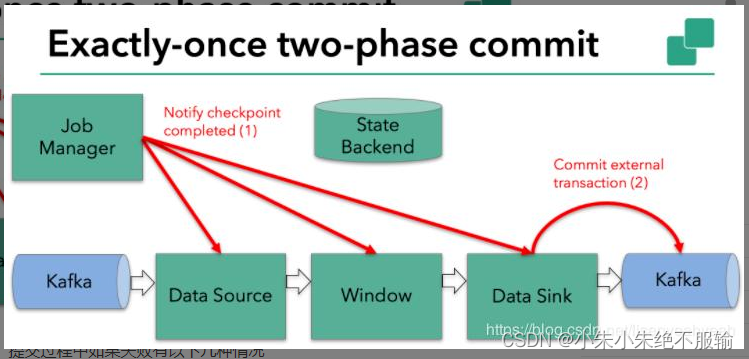
以上便是两阶段的完整流程,提交过程中如果失败有以下几种情况:
- pre-commit失败,将恢复到最近一次CheckPoint位置
- 一旦pre-commit完成,必须要确保commit也要成功
因此,所有opeartor必须对checkpoint最终结果达成共识:即所有operator都必须认定数据提交要么成功执行,要么被终止然后回滚。
5. CheckPoint调优
对于Flink Checkpoint的优化至关重要。我们常见的优化 Checkpoint的手段如下:
5.1 设置最小时间间隔
当Flink应用开启Checkpoint功能,并配置Checkpoint时间间隔,应用中就会根据指定的时间间隔周期性地对应用进行Checkpoint操作。
默认情况下Checkpoint操作都是同步进行,也就是说,当前面触发的Checkpoint动作没有完全结束时,之后的Checkpoint操作将不会被触发。在这种情况下,如果Checkpoint过程持续的时间超过了配置的时间间隔,就会出现排队的情况。如果有非常多的Checkpoint操作在排队,就会占用额外的系统资源用于Checkpoint,此时用于任务计算的资源将会减少,进而影响到整个应用的性能和正常执行。
在这种情况下,如果大状态数据确实需要很长的时间来进行Checkpoint,那么只能对Checkpoint的时间间隔进行优化,可以通过Checkpoint之间的最小间隔参数进行配置,让Checkpoint之间根据Checkpoint执行速度进行调整,前面的Checkpoint没有完全结束,后面的Checkpoint操作也不会触发。
streamExecutionEnvironment.getCheckpointConfig().setMinPauseBetweenCheckpoints(milliseconds)
通过最小时间间隔参数配置,可以降低Checkpoint对系统的性能影响,但需要注意的事,对于非常大的状态数据,最小时间间隔只能减轻Checkpoint之间的堆积情况。如果不能有效快速地完成Checkpoint,将会导致系统Checkpoint频次越来越低,当系统出现问题时,没有及时对状态数据有效地持久化,可能会导致系统丢失数据。
因此,对于非常大的状态数据而言,应该对Checkpoint过程进行优化和调整,例如采用增量Checkpoint的方法等。
用户也可以通过配置CheckpointConfig中setMaxConcurrentCheckpoints()方法设定并行执行的checkpoint数量,这种方法也能有效降低checkpoint堆积的问题,但会提高资源占用。同时,如果开始了并行checkpoint操作,当用户以手动方式触发savepoint的时候,checkpoint操作也将继续执行,这将影响到savepoint过程中对状态数据的持久化。
5.2 预估状态容量
除了对已经运行的任务进行checkpoint优化,对整个任务需要的状态数据量进行预估也非常重要,这样才能选择合适的checkpoint策略。对任务状态数据存储的规划依赖于如下基本规则:
- 正常情况下应该尽可能留有足够的资源来应对频繁的反压。
- 需要尽可能提供给额外的资源,以便在任务出现异常中断的情况下处理积压的数据。这些资源的预估都取决于任务停止过程中数据的积压量,以及对任务恢复时间的要求。
- 系统中出现临时性的反压没有太大的问题,但是如果系统中频繁出现临时性的反压,例如下游外部系统临时性变慢导致数据输出速率下降,这种情况就需要考虑给予算子一定的资源。
- 部分算子导致下游的算子的负载非常高,下游的算子完全是取决于上游算子的输出,因此对类似于窗口算子的估计也将会影响到整个任务的执行,应该尽可能给这些算子留有足够的资源以应对上游算子产生的影响。
5.3 异步Snapshot
默认情况下,应用中的checkpoint操作都是同步执行的,在条件允许的情况下应该尽可能地使用异步的snapshot,这样将大幅度提升checkpoint的性能,尤其是在非常复杂的流式应用中,如多数据源关联、co-functions操作或windows操作等,都会有较好的性能改善。
Flink提供了异步快照(Asynchronous Snapshot)的机制。
- 当实际执行快照时,Flink可以立即
向下广播Checkpoint Barrier,表示自己已经执行完自己部分的快照。 - 同时,Flink启动一个后台线程,它创建本地状态的一份拷贝,这个线程用来将本地状态的拷贝同步到State Backend上,一旦数据同步完成,再给Checkpoint Coordinator发送确认信息。
- 拷贝一份数据肯定占用更多内存,这时可以利用
写入时复制(Copy-on-Write)的优化策略。Copy-on-Write指:如果这份内存数据没有任何修改,那没必要生成一份拷贝,只需要有一个指向这份数据的指针,通过指针将本地数据同步到State Backend上;如果这份内存数据有一些更新,那再去申请额外的内存空间并维护两份数据,一份是快照时的数据,一份是更新后的数据。
在使用异步快照需要确认应用遵循以下两点要求:
- 首先必须是Flink托管状态,即使用Flink内部提供的托管状态所对应的数据结构,例如常用的有ValueState、ListState、ReducingState等类型状态。
- StateBackend必须支持异步快照,在Flink1.2的版本之前,只有RocksDB完整地支持异步的Snapshot操作,从Flink1.3版本以后可以在heap-based StateBackend中支持异步快照功能。
5.4 压缩状态数据
Flink中提供了针对checkpoint和savepoint的数据进行压缩的方法,目前Flink仅支持通过用snappy压缩算法对状态数据进行压缩,在未来的版本中Flink将支持其他压缩算法。
在压缩过程中,Flink的压缩算法支持key-group层面压缩,也就是不同的key-group分别被压缩成不同的部分,因此解压缩过程可以并发执行,这对大规模数据的压缩和解压缩带来非常高的性能提升和较强的可扩展性。Flink中使用的压缩算法在ExecutionConfig中进行指定,通过将setUseSnapshotCompression方法中的值设定为true即可。
5.5 观察checkpoint延迟时间
checkpoint延迟启动时间并不会直接暴露在客户端中,而是需要通过以下公式计算得出。如果改时间过长,则表明算子在进行barrier对齐,等待上游的算子将数据写入到当前算子中,说明系统正处于一个反压状态下。checkpoint延迟时间可以通过整个端到端的计算时间减去异步持续的时间和同步持续的时间得出。
5.6 Checkpoint相关配置
默认情况下,Checkpoint机制是关闭的,需要调用env.enableCheckpointing(n)来开启,每隔n毫秒进行一次Checkpoint。Checkpoint是一种负载较重的任务,如果状态比较大,同时n值又比较小,那可能一次Checkpoint还没完成,下次Checkpoint已经被触发,占用太多本该用于正常数据处理的资源。增大n值意味着一个作业的Checkpoint次数更少,整个作业用于进行Checkpoint的资源更小,可以将更多的资源用于正常的流数据处理。同时,更大的n值意味着重启后,整个作业需要从更长的Offset开始重新处理数据。
此外,还有一些其他参数需要配置,这些参数统一封装在了CheckpointConfig里:
val cpConfig: CheckpointConfig = env.getCheckpointConfig
默认的Checkpoint配置是支持Exactly-Once投递的,这样能保证在重启恢复时,所有算子的状态对任一条数据只处理一次。用上文的Checkpoint原理来说,使用Exactly-Once就是进行了Checkpoint Barrier对齐,因此会有一定的延迟。如果作业延迟小,那么应该使用At-Least-Once投递,不进行对齐,但某些数据会被处理多次。
// 使用At-Least-Once
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE)
如果一次Checkpoint超过一定时间仍未完成,直接将其终止,以免其占用太多资源:
// 超时时间1小时
env.getCheckpointConfig.setCheckpointTimeout(3600*1000)
如果两次Checkpoint之间的间歇时间太短,那么正常的作业可能获取的资源较少,更多的资源被用在了Checkpoint上。对这个参数进行合理配置能保证数据流的正常处理。比如,设置这个参数为60秒,那么前一次Checkpoint结束后60秒内不会启动新的Checkpoint。这种模式只在整个作业最多允许1个Checkpoint时适用。
// 两次Checkpoint的间隔为60秒
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(60*1000)
默认情况下一个作业只允许1个Checkpoint执行,如果某个Checkpoint正在进行,另外一个Checkpoint被启动,新的Checkpoint需要挂起等待。
// 最多同时进行3个Checkpoint
env.getCheckpointConfig.setMaxConcurrentCheckpoints(3)
如果这个参数大于1,将与前面提到的最短间隔相冲突。
Checkpoint的初衷是用来进行故障恢复,如果作业是因为异常而失败,Flink会保存远程存储上的数据;如果开发者自己取消了作业,远程存储上的数据都会被删除。如果开发者希望通过Checkpoint数据进行调试,自己取消了作业,同时希望将远程数据保存下来,需要设置为:
// 作业取消后仍然保存Checkpoint
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
RETAIN_ON_CANCELLATION模式下,用户需要自己手动删除远程存储上的Checkpoint数据。
默认情况下,如果Checkpoint过程失败,会导致整个应用重启,我们可以关闭这个功能,这样Checkpoint失败不影响作业的运行。
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
参考:
















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









