







Redis 基础入门
一、安装
- 创建挂载文件
mkdir -p /mydata/redis/conf
touch /mydata/redis/conf/redis.conf
- 启动 redis 容器
docker run -p 6379:6379 --name redis -v /mydata/redis/data:/data \
-v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf \
-d redis redis-server /etc/redis/redis.conf
- 测试安装
进入 redis-cli
docker exec -it redis redis-cli
我们输入简单的 get set 指令,查看 redis 是否能成功执行

此时,虽然 redis 是可以运行的,但是数据都没有持久化,一旦重启,数据就消失了,所以需要添加配置
- 进入下面的网址,添加 redis 的自描述文件
将信息复制到我们的 redis.conf 文件夹中
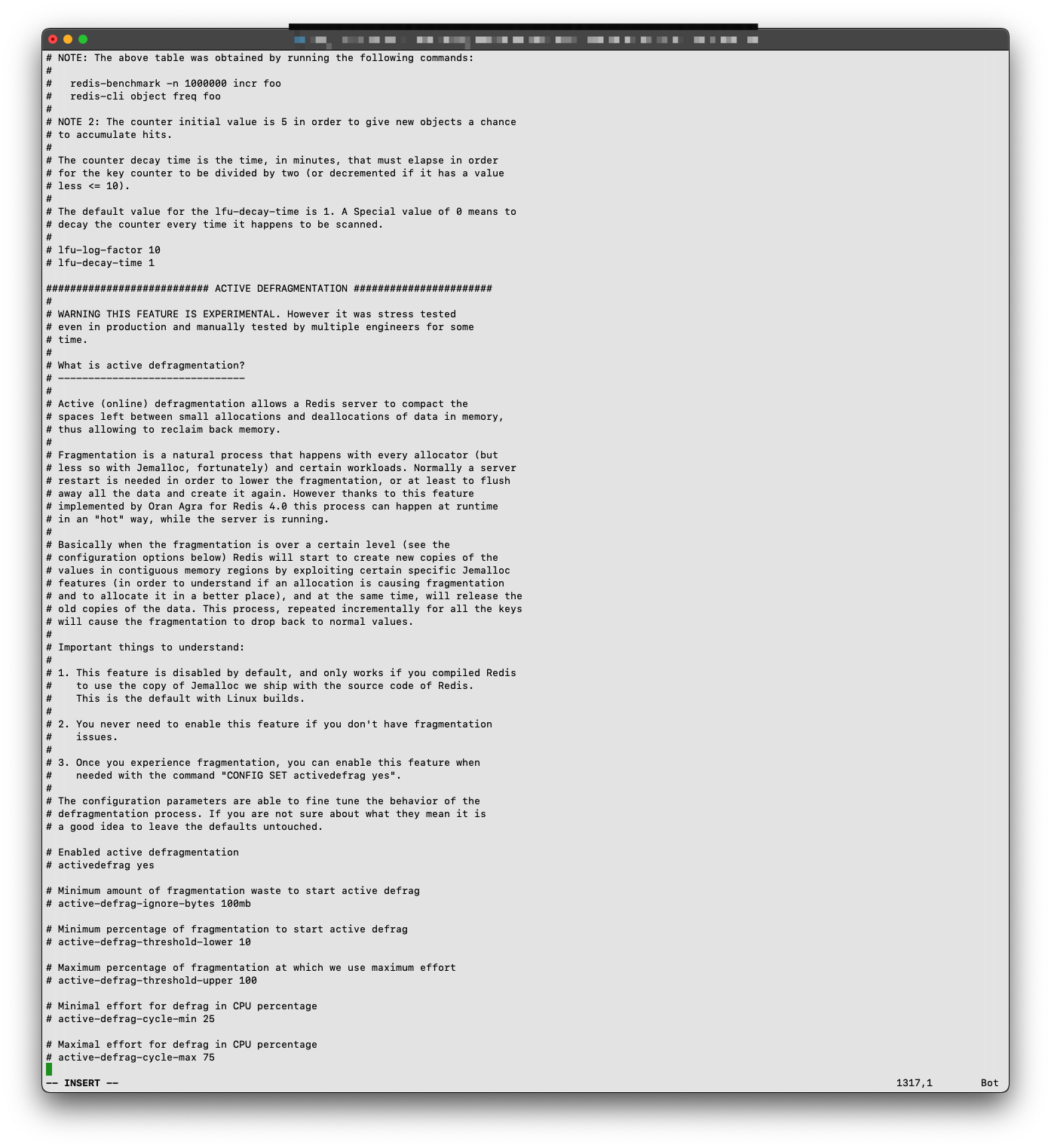
找到 appendonly,将后面的 no 改为 yes (即开启 AOP 持久化策略)
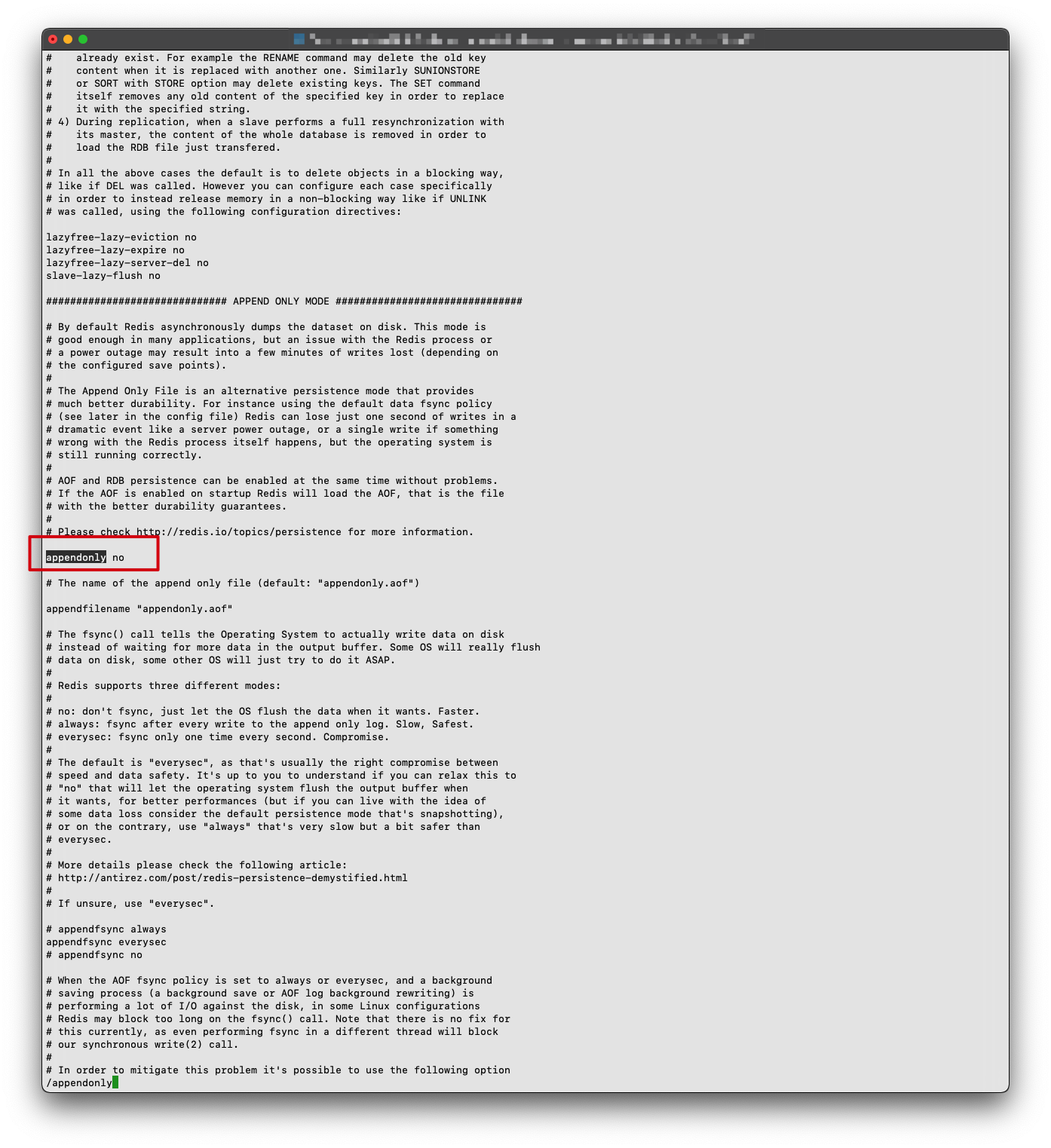
我们再进行测试
- 安装可视化管理程序
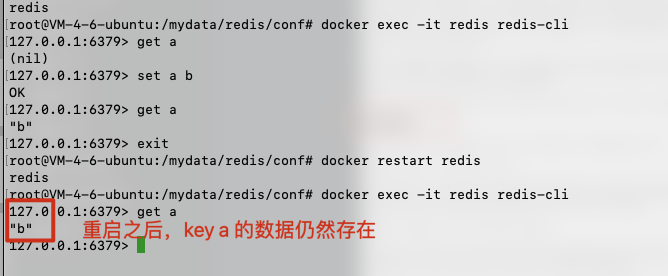
首先必须将 conf 文件中的 bind 数据进行修改
要将 bind 127.0.0.1 改成 bind 0.0.0.0
(标签:阿里云、腾讯云远程连接 redis失败,RDM)
安装 RDM ,填写 redis 所在的宿主机的 ip username password 即可
二、基础数据类型
基础数据类型的操作,可以参考下面这个链接:https://www.runoob.com/redis/redis-strings.html
这里就不再赘述了
1、String
String 使用 get set 进行设置,可以设置定时删除、步长增加,因为 redis 单线程的缘故,所以 incr decr 的操作是原子性的
其底层数据结构很简单,和 java 中的 ArrayList 类似:

如图中所示,内部为当前字符串实际分配的空间capacity一般要高于实际字符串长度len。当字符串长度小于1M时,扩容都是加倍现有的空间,如果超过1M,扩容时一次只会多扩1M的空间。需要注意的是字符串最大长度为512M
2、list
list 底层数据结构是双向链表:

正因如此,list 有左插右插的操作
3、set
redis 中的 set 和 java 中的 HashSet 类似,可以自动排重,并提供判断元素是否在 set 中的接口
4、hash
redis 中的 hash 和 java 中的 map 类似
使用 hash 可能是出于下面这样的考量,比如我们想要存储用户的数据,有下面几个方案:
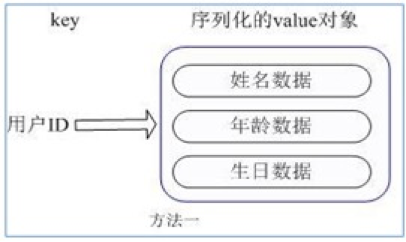
- 方案1:
对象序列化后存储,要使用的时候再提取并反序列化
- 方案2:
用冗余的 id+用户信息数据进行存储
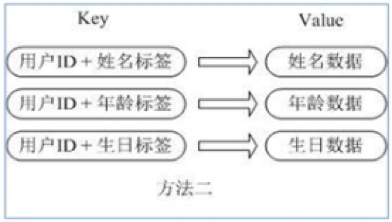
这种方案还不如第一种方案
- 方案3:
借助 hash 进行存储
通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题
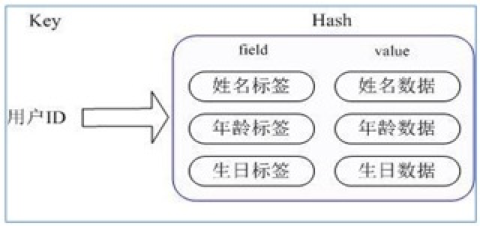
使用 方案3 的话,当我们希望获取用户的某个字段的信息,就不需要像 方案1 那样,将整个对象的信息提取出来再序列化了,提高了信息获取的效率
不过在实际开发中,这种实现方式除非在系统非优化到这步才使用,不然多数情况下为了图方便,我们还是使用 方案1
5、zset
相较于 set ,zset 为每个数据添加了 score 字段,所有元素会默认根据 score 的大小,从小到大排序
因为这种特性,遇到热榜排行、商城信息排行等业务,使用 zset 就显得分外方便
这里我们模拟一个热销榜:

在像用户展示之前,我们获取的数据顺序如下:
可以看到,排序是按照分数递增的
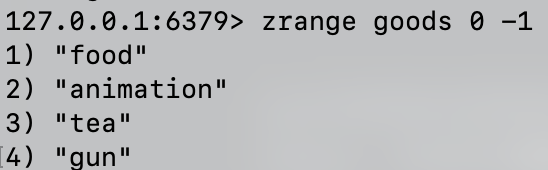
如果哪件商品的热度下降了,我们可以通过修改其 score 值实现排名的降低:

zset 的底层实现是跳表,跳表简单来说,就是为了解决链表这种数据结构定位慢的问题(O(N)),可以将链表定位的时间复杂度降为 O(logn),其使用的额外空间无限接近与原链表的大小
关于跳表的细节,可以点击下面这个链接去了解:
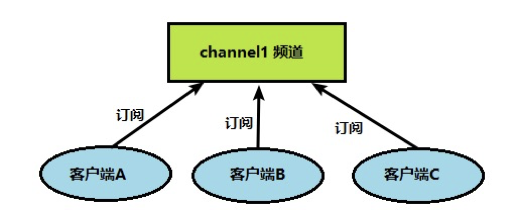
三、发布/订阅模式
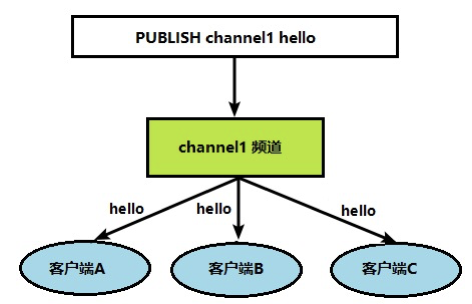
订阅者在订阅指定频道后,发布者在对应频道发布信息,所有订阅该频道的 redis 进程都会受到发布者发布的消息
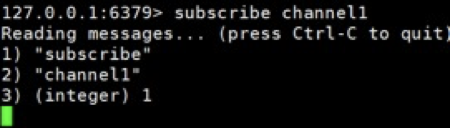
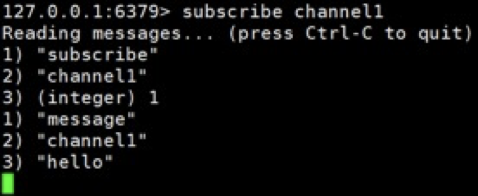
- 打开一个客户端,订阅 channel1:
- 打开另一个客户端,作为发布者向 channel1 中发布信息 hello:

- 可以看到,订阅者收到了信息:
四、Redis 新数据类型
1、Bitmap
在我们平时的开发过程中,会有一些boolean型数据需要存取,比如用户一年的签到记录,签了是1,没签是0,要记录365天。如果使用普通的key/value,每个用户要记录365个,当用户数上亿的时候,需要的存储空间是惊人的。
为了解决这个问题,redis提供了位图数据结构,这样每天的签到记录只占据一个位,365天就是365个位,46个字节(一个稍长一点的字符串)就可以完全容纳下,这就大大节约了存储空间。位图的最小单位是比特(bit),每个bit的取值只能是0或1。
1)使用
这里我们设置一个场景,使用 Bitmap 记录一款应用当天的用户登录情况
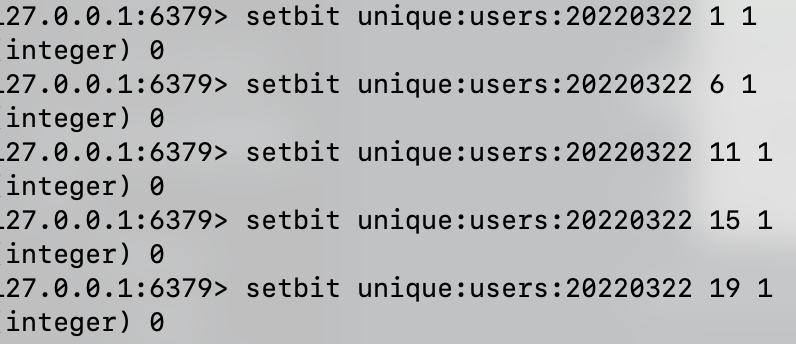
- setbit:
假设 2022年3月22日,1、6、11、15、19号用户登录了应用
这里我们要注意,有些情况下,为用户设置的 id 头几位可能有重复数,比如 1号用户为 100001,2号用户为100002,如果直接将用户 id 作为参数存入 bitmap 中,那么 bitmap 的偏移量会很大,导致初始化时间过长,进而使得 redis 产生阻塞
对于这种情况,我们应该在将数据存入 bitmap 之前,去除所有数字头部重复的部分
- getbit:
为了了解某个用户在某天有无登录,可以使用 gitbit 获取bitmap 数据
1号用户在 2022年3月22日进行了登录操作:

- bitcount:
为了统计某天的用户月活,我们可以使用 bitcount 统计 bitmap 中 1 的个数
2022年3月22日日活人数为 5:

- bitop:
bitop 可以对两个 bitmap 进行与、或、非、异或操作,并将操作结果存入一个新的 bitmap 中
统计 20220327 和 20220328 都在线的人数:
对于这个请求,我们可以对这两天的 bitmap 进行与操作
结果存入新的 bitmap users:and:20220327_28 中
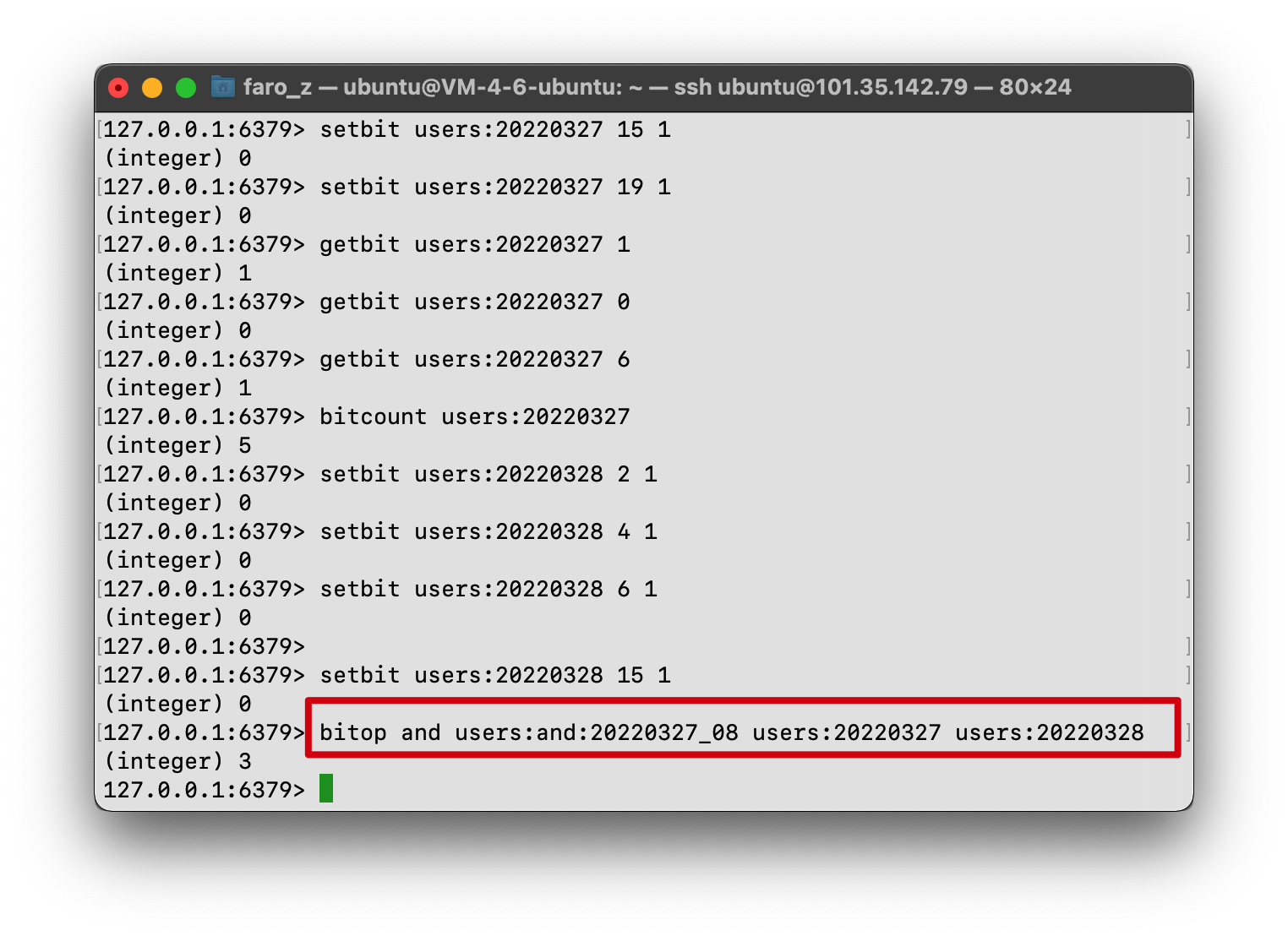
统计两日都在线人数,只需要对新的 bitmap 进行 bitcount 操作即可

2)实际应用场景
除了上面介绍的统计日活月活外,涉及到大量用户、长时间统计的业务,都可以考虑使用 bitmap
比如签到业务,使用 uid 做 key,单个 bitmap 统计用户从注册开始的签到状态。这样,在3亿用户的前提下,一年的数据使用量是
300000000*365/8/1024/1024/1024 = 12.74 GB,还是很划算的
3)bitmap 与 set 比较
乍看之下,好像使用 bitmap 必定会比 set 节省空间
我们以统计日活做例子
- 假设网站注册用户数为 1亿,日活 5千万,单个用户 id 占据 64bit
那么单日空间消耗为:
bitmap 占用空间:1 0000 0000 /8/1024/1024/1024 = 0.01 GB
set 占用空间:5000 0000 * 64 /8 /1024/1024/1024 = 0.32GB
一年下来空间消耗为:
Bitmap: 3.65GB
Set : 116.8 GB
可以发现,bitmap 节省的空间还是十分客观的
但是,假设网站虽然有很高的注册量,但是有大量僵尸粉,情况就大不相同了
- 假设网站还是 1亿注册量,但是日活只有 10 万
单日空间消耗:
bitmap 占用空间:1 0000 0000 /8/1024/1024/1024 = 0.01 GB
set 占用空间:10 0000 * 64 /8 /1024/1024/1024 = 0.0007GB
一年下来的空间消耗:
Bitmap: 3.65GB
Set : 0.26 GB
所以说,是否使用 Bitmap,还是要依照业务量来的
2、hyperLogLog
1)介绍
实际业务中,我们有统计 PV(PageView)即页面观看数的需求,方便后续对业务做出调整,这个功能我们可以很方便的使用 redis 的 incr,incrby 统计
但是,像 UV(unique visiter) 即独立访客,在统计访问量的基础上,还需要进行去重,这时候单纯的使用 incr ,incrby 就不好使了,对于这样的业务需求,可以归于一种基数统计需求。所谓基数统计,即假设一个数据集 {1,1,2,2,3},则其基数集是其去重后的集合,即{1,2,3},则其基数统计的结果为 3
对于这个问题,解决方案有很多:
(1)使用 mysql 存储单个 ip 的访问记录
(2)使用 set bitmap 这些数据结构进行存储
但是对于亿级的用户,方案**(1)**自不必说,浪费大量不必要的空间的同时,数据库还有很大的概率寄,为了这么小一个功能耗费这么多资源显然不值当
方案 (2) 中的 set 因为占用量大也不合适,而 bitmap 虽然对空间已经做到尽可能压缩了,但是相对于功能的重要程度,其占用的空间还是大了一些,bitmap 长度为 2^32 ,对于类似 google 搜索页面要统计每日访问的独立 IP的数量,单就 几十亿级别的搜索次数,少说每日资源开销就是几百 mb,累计下来资源消耗还是蛮哈人的
其实对于十几亿级的统计需求,几十亿和几十亿零几百万的区别是不大的,这个时候,我们就需要一种精度可以不是很高,但是空间消耗一定要小的算法,HyperLogLog 边应运而生
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
2)使用
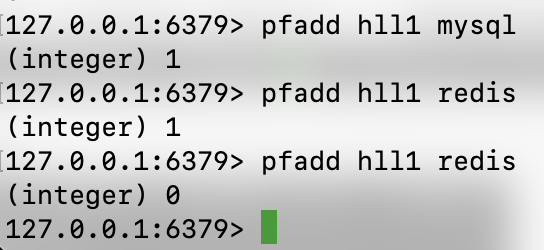
- pfadd:
向 hll 中"添加"元素,并使用指定算法去重统计元素个数
- pfcount
返回基数
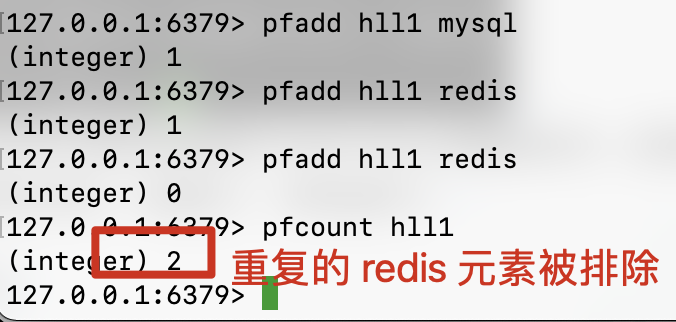
pfcount 除了统计单个 hll 外,也可以同时统计多个 hll
假设我们想要统计两日的 UV 数据:
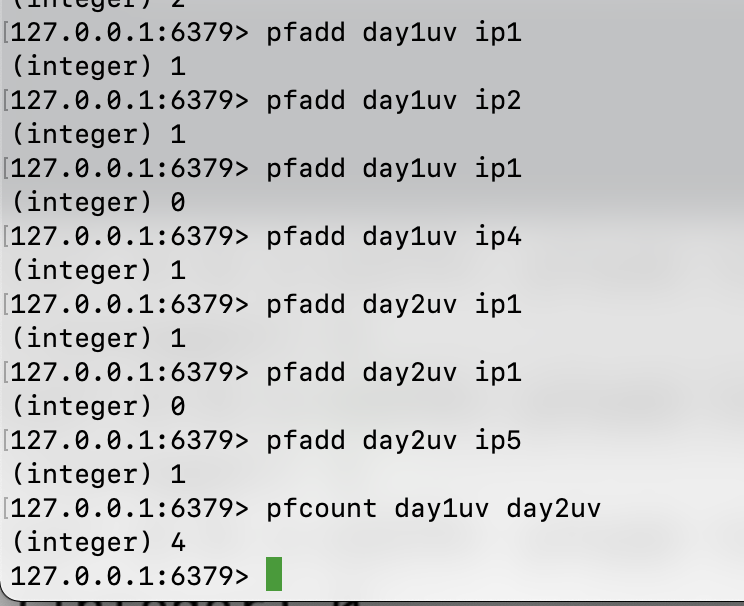
day1 访问基数集合为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1607
1607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











