







文章目录
一、字符串
1.1 前言
字符串对象是 Redis 中最基本的数据类型,也是我们工作中最常用的数据类型。redis中的键都是字符串对象,而且其他几种数据结构都是在字符串对象基础上构建的。字符串对象的值实际可以是字符串、数字、甚至是二进制,最大不能超过512MB。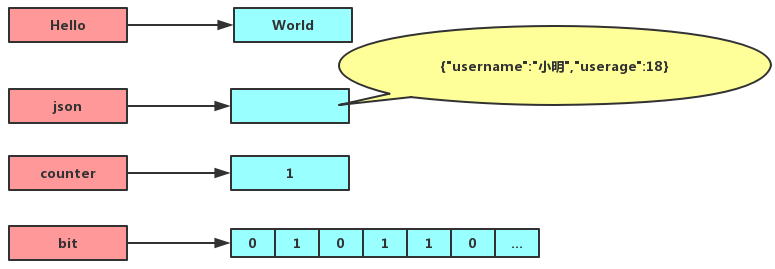
1.2 内部实现
Redis字符串对象底层的数据结构实现主要是 int 和 简单动态字符串SDS (这个字符串,和我们认识的C字符串不太一样,了解具体请看图解Redis之数据结构篇——简单动态字符串SDS),其通过不同的编码方式映射到不同的数据结构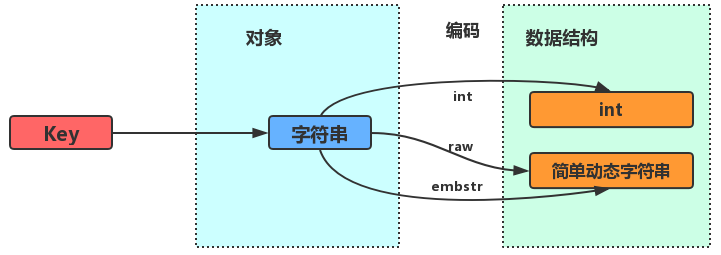
字符串对象的内部编码有3种 :int、raw 和 embstr。Redis会根据当前值的类型和长度来决定使用哪种编码来实现
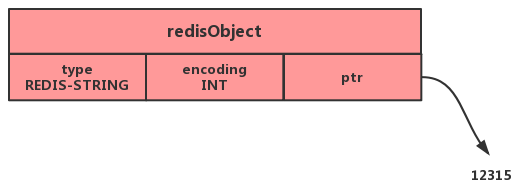
- 如果一个字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成1ong),并将字符串对象的编码设置为int
- 如果字符串对象保存的是一个字符串值,并且这个字符串值的长度大于32字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为raw。
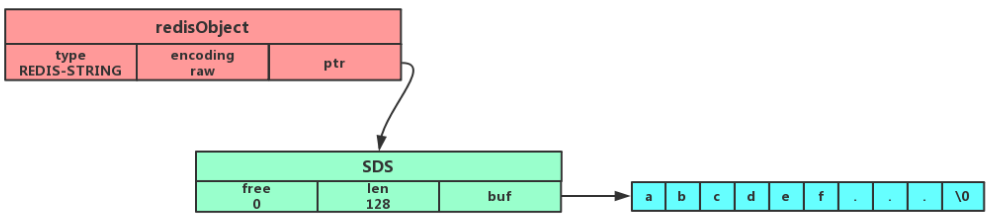
- 如果字符串对象保存的是一个字符串值,并且这个字符申值的长度小于等于32字节,那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串值,并将对象的编码设置为embstr

embstr编码是专门用于保存短字符串的一种优化编码方式,我们可以看到embstr和raw编码都会使用SDS来保存值,但不同之处在于embstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS。而raw编码会通过调用两次内存分配函数来分别分配两块空间来保存redisObject和SDS。Redis这样做会有很多好处。
- embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次
- 释放 embstr编码的字符串对象同样只需要调用一次内存释放函数
- 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用CPU缓存提升性能
Redis中根据数据类型和长度来使用不同的编码和数据结构存储存在于Redis中的每一种对象类型上。其这种小细节上的优化令我叹服不止,后续我们会看到Redis中到处都是这种内存与性能上的小细节优化!
1.3 常用指令(略)
1.4 常用场景
redis 字符串的使用场景应该是最为广泛的,甚至有些对redis其它几种对象不太熟悉的人,基本所有场景都会使用字符串(序列化一下直接扔进去)。在众多的使用场景中总结一下大概分以下几种。
1.4.1 作为缓存层
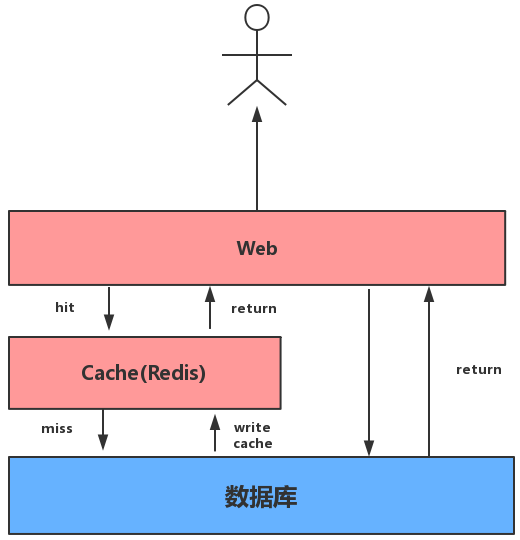
如上图,Redis经常作为缓存层,来缓存一些热点数据。来加速读写性能从而降低后端的压力。一般在读取数据的时候会先从Redis中读取,如果Redis中没有,再从数据库中读取。在Redis作为缓存层使用的时候,必须注意一些问题,如:缓存穿透、雪崩以及缓存更新问题…
1.4.2 计数器\限速器\分布式系统ID
计数器\限速器\分布式ID等主要是利用Redis字符串自增自减的特性。
- 计数器:经常可以被用来做计数器,如微博的评论数、点赞数、分享数,抖音作品的收藏数,京东商品的销售量、评价数等。
- 限速器:如验证码接口访问频率限制,用户登陆时需要让用户输入手机验证码,从而确定是否是用户本人,但是为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,例如一分钟不能超过5次。
- 分布式ID:由于Redis自增自减的操作是原子性的因此也经常在分布式系统中用来生成唯一的订单号、序列号等。
1.4.3 分布式系统共享session
通常在单体系统中,Web服务将会用户的Session信息(例如用户登录信息)保存在自己的服务器中。但是在分布式系统中,这样做会有问题。因为分布式系统通常有很多个服务,每个服务又会同时部署在多台机器上,通过负载均衡机制将将用户的访问均衡到不同服务器上。这个时候用户的请求可能分发到不同的服务器上,从而导致用户登录保存Session是在一台服务器上,而读取Session是在另一台服务器上因此会读不到Session。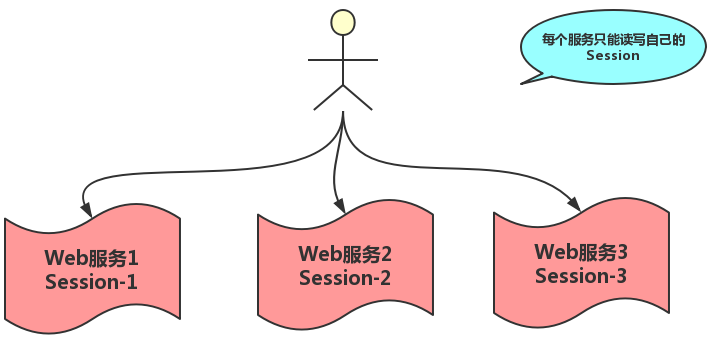
这种问题通常的做法是把Session存到一个公共的地方,让每个Web服务,都去这个公共的地方存取Session。而Redis就可以是这个公共的地方。(数据库、memecache等都可以各有优缺点)。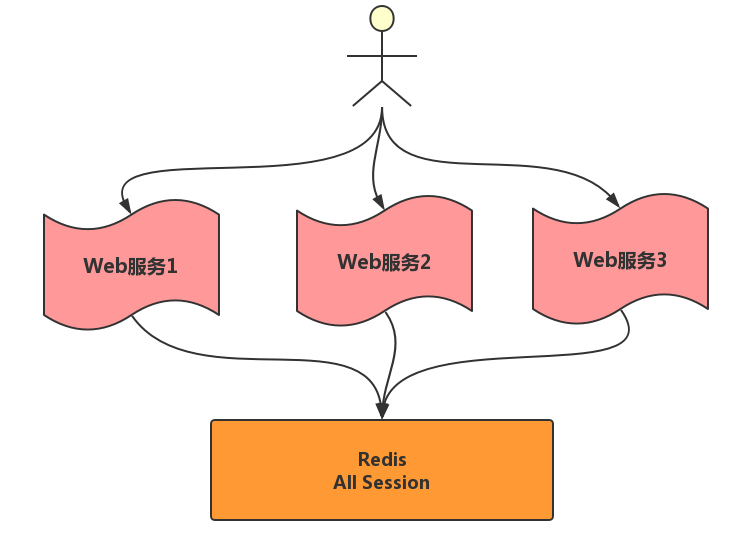
1.4.4 二进制存储
由于Redis字符串可以存储二进制数据的特性,因此也可以用来存储一些二进制数据。如图片、 音频、 视频等。
二、哈希(Hash)
哈希在很多编程语言中都有着很广泛的应用,而在Redis中也是如此,在redis中,哈希类型是指Redis键值对中的值本身又是一个键值对结构,形如value=[{field1,value1},…{fieldN,valueN}],其与Redis字符串对象的区别如下图所示: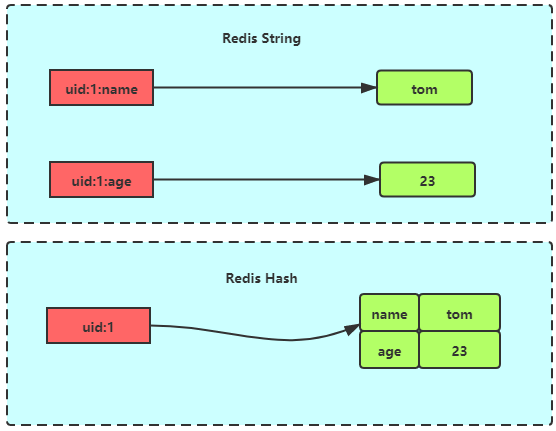
2.1 内部编码
哈希类型的内部编码有两种:ziplist(压缩列表),hashtable(哈希表)。只有当存储的数据量比较小的情况下,Redis 才使用压缩列表来实现字典类型。具体需要满足两个条件:
- 当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)
- 所有值都小于hash-max-ziplist-value配置(默认64字节) ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。 有关ziplist和hashtable这两种redis底层数据结构的具体实现可以参考我的另外两篇文章。
Redis数据结构——压缩列表
Redis数据结构——字典。
2.2 常用命令(略)
2.3 适用场景
2.3.1 存储对象
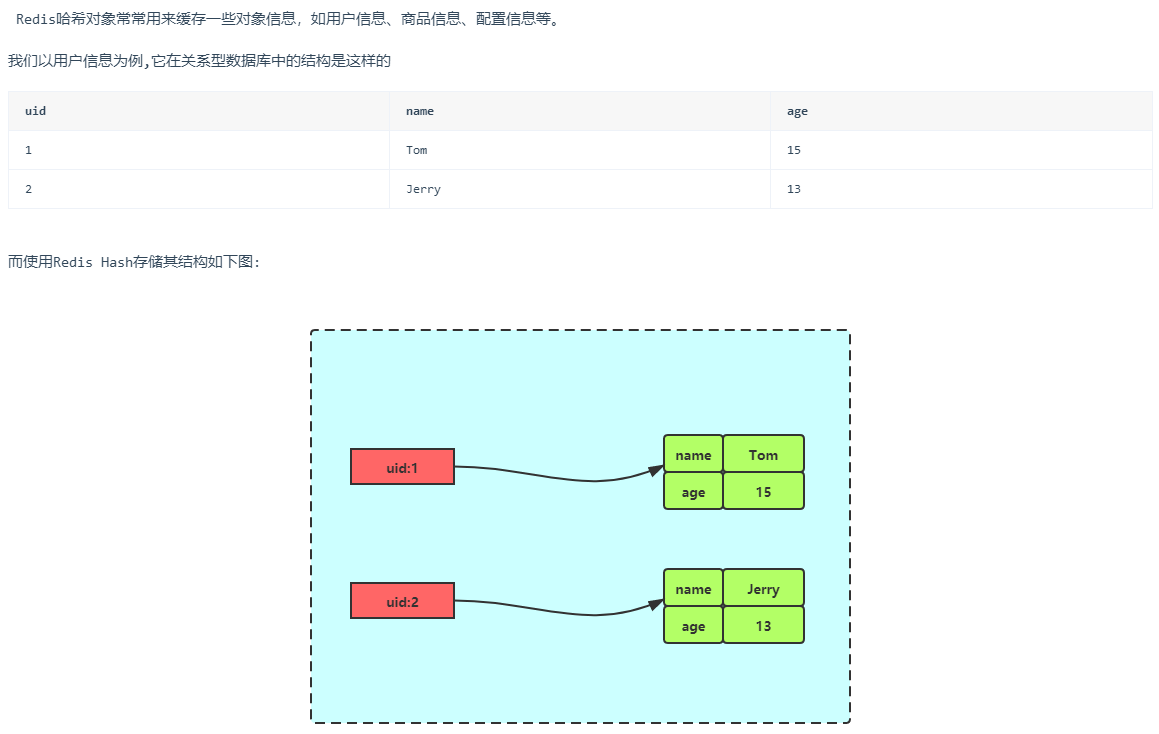


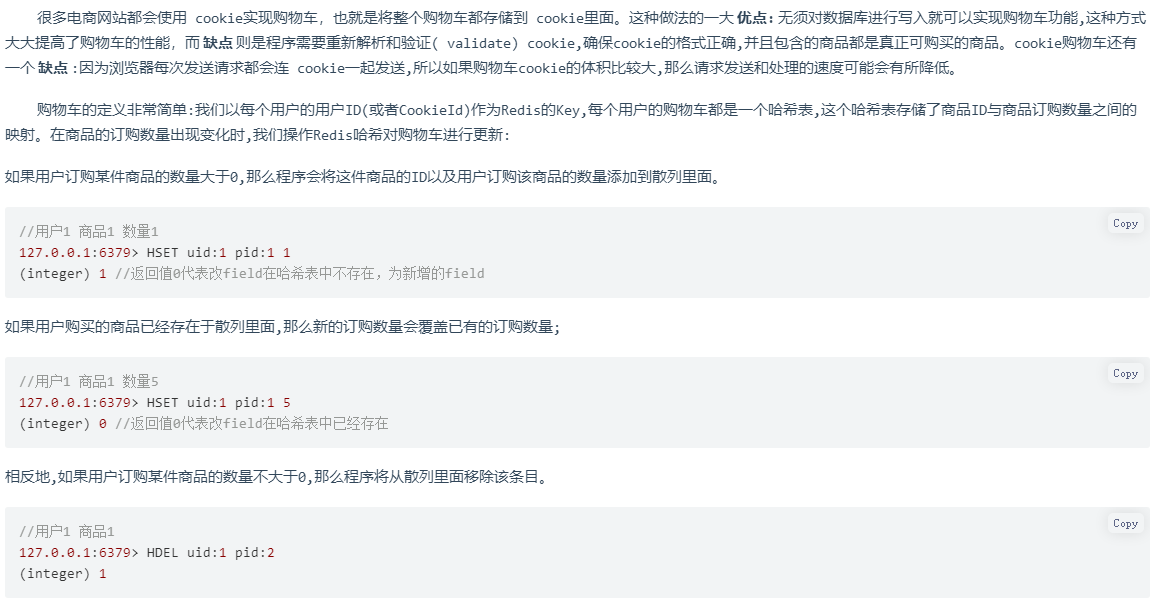
2.3.2 购物车
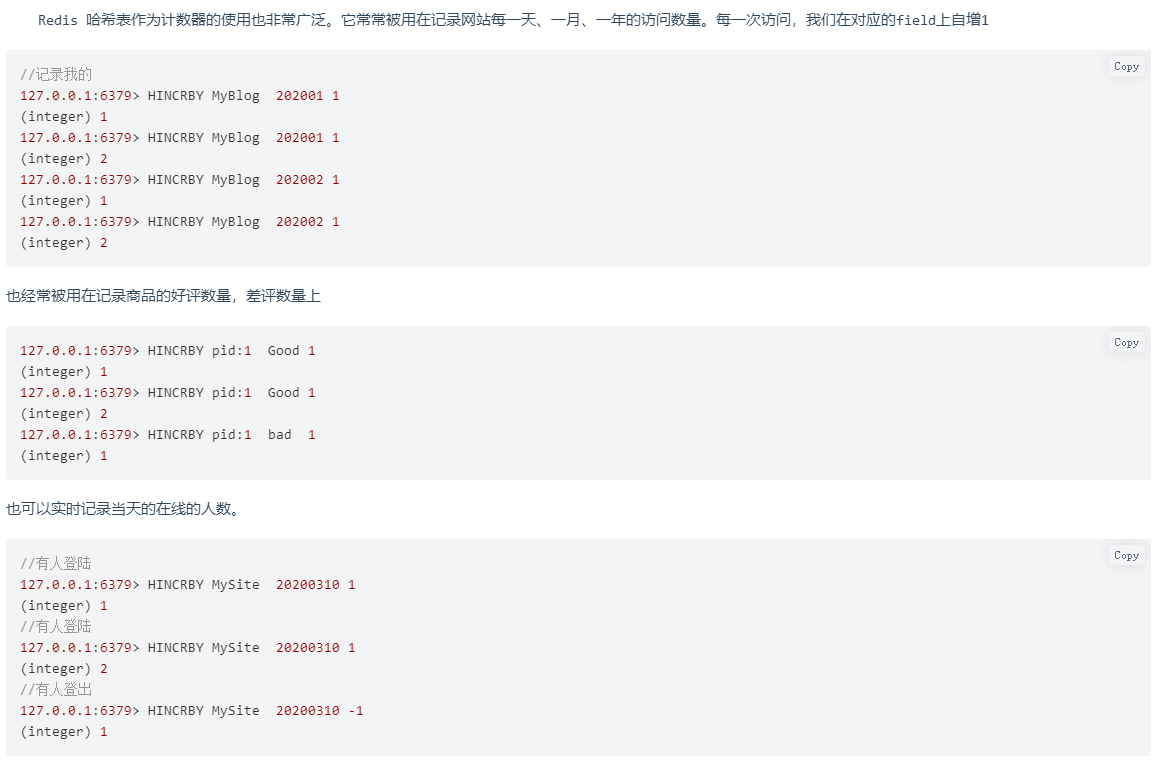
2.3.3 计数器
2.4 小结
本篇文章我们总结了Redis 哈希对象的内部实现、常用命令以及常用的一些场景。
三、列表
列表(list)类型是用来存储多个有序的字符串,列表中的每个字符串称为元素(element),一个列表最多可以存储232-1个元素。在Redis中,可以对列表两端插入(push)和弹出(pop),还可以获取指定范围的元素列表、获取指定索引下标的元素等。列表是一种比较灵活的数据结构,它可以充当栈和队列的角色,在实际开发上有很多应用场景。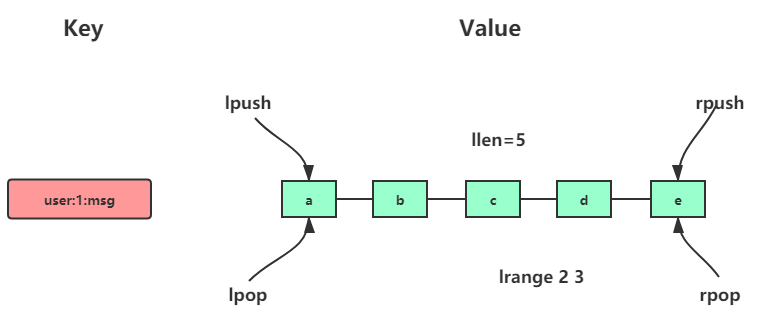
列表类型有两个特点:
- 列表中的元素是有序的,这就意味着可以通过索引下标获取某个元素或者某个范围内的元素列表。
- 列表中的元素可以是重复的.
3.1 内部实现
在Redis3.2版本以前列表类型的内部编码有两种。
- ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置(默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时(默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使用。
- linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
而在Redis3.2版本开始对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist
关于这三种底层数据结构可以查看我的另外三篇文章
Redis数据结构——链表
Redis数据结构——压缩列表
Redis数据结构——quicklist
3.2 常用命令(略)
3.3 使用场景
3.3.1 消息队列
列表类型可以使用 rpush 实现先进先出的功能,同时又可以使用 lpop 轻松的弹出(查询并删除)第一个元素,所以列表类型可以用来实现消息队列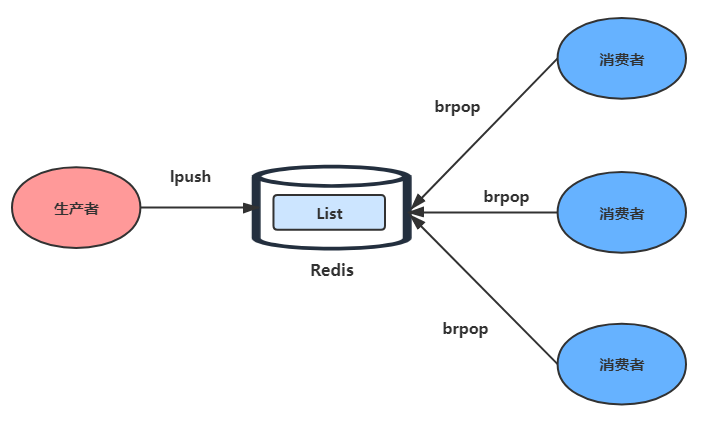
3.3.2 文章(商品等)列表
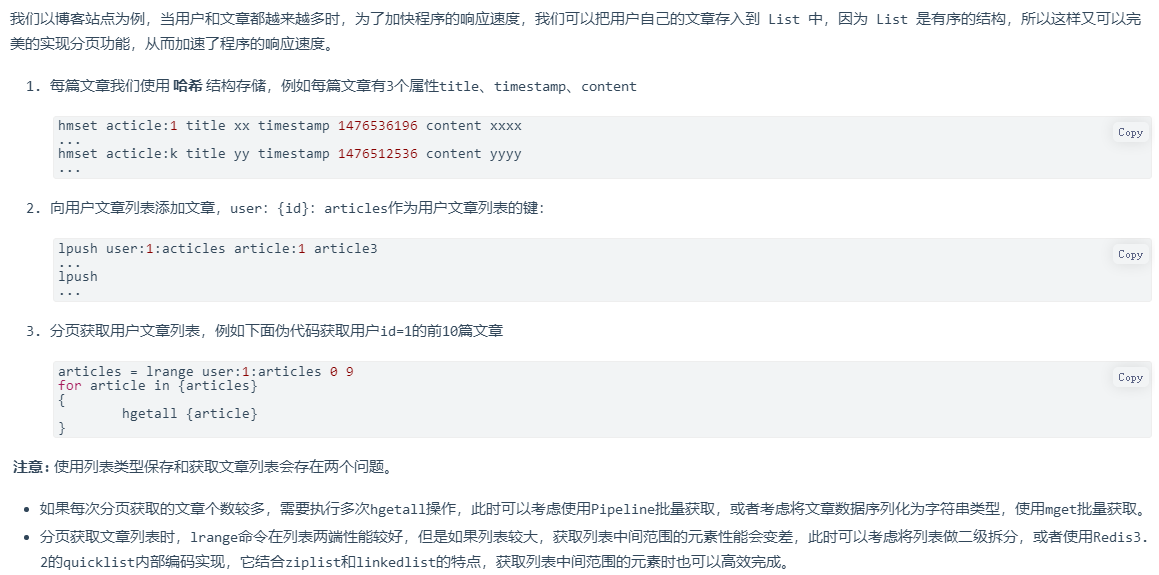

3.4 小结
本篇文章我们总结了Redis 列表对象的内部实现、常用命令以及常用的一些场景。
四、集合
- 集合类型 (Set) 是一个无序并唯一的键值集合。它的存储顺序不会按照插入的先后顺序进行存储。
- 集合类型和列表类型的区别如下:
- 列表可以存储重复元素,集合只能存储非重复元素;
- 列表是按照元素的先后顺序存储元素的,而集合则是无序方式存储元素的。
- 一个集合最多可以存储232-1个元素。Redis除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集,合理地使用好集合类型,能在实际开发中解决很多实际问题。
4.1 内部实现
集合类型的内部编码有两种:
- intset(整数集合):当集合中的元素都是整数且元素个数小于set-maxintset-entries配置(默认512个)时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用。
- hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
有关intset和hashtable这两种redis底层数据结构的具体实现可以参考我的另外两篇文章。
Redis数据结构——整数集合
Redis数据结构——字典。
4.2 常用命令(略)
4.3 使用场景
通过上文,我们可以知道集合的主要几个特性,无序、不可重复、支持并交差等操作。因此集合类型比较适合用来数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等,当我们存储的数据是无序并且需要去重的情况下,比较适合使用集合类型进行存储。
4.3.1 标签系统
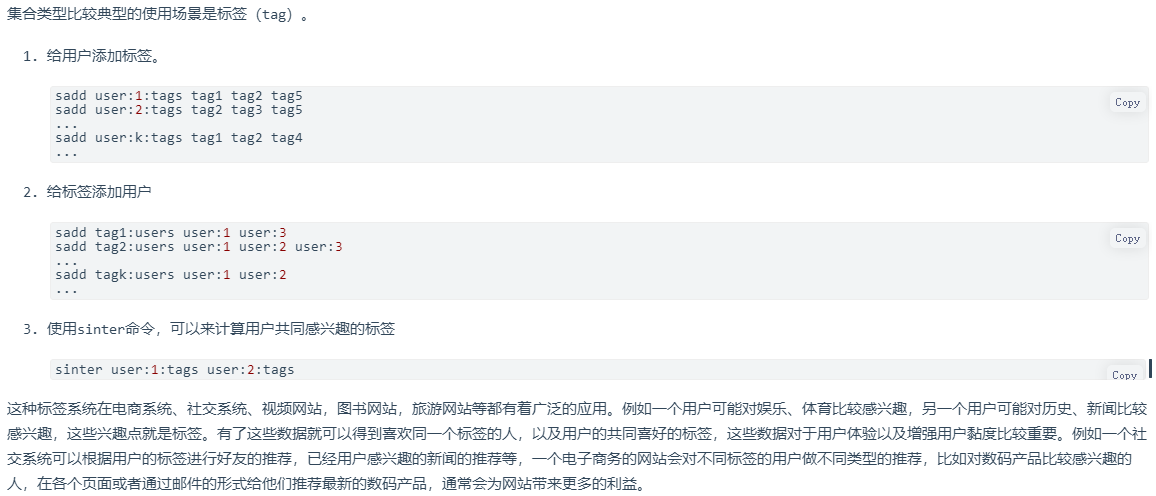
4.3.2 抽奖系统
Redis集合的 SPOP(随机移除并返回集合中一个或多个元素) 和 SRANDMEMBER(随机返回集合中一个或多个元素) 命令可以帮助我们实现一个抽奖系统 如果允许重复中奖,可以使用SRANDMEMBER 命令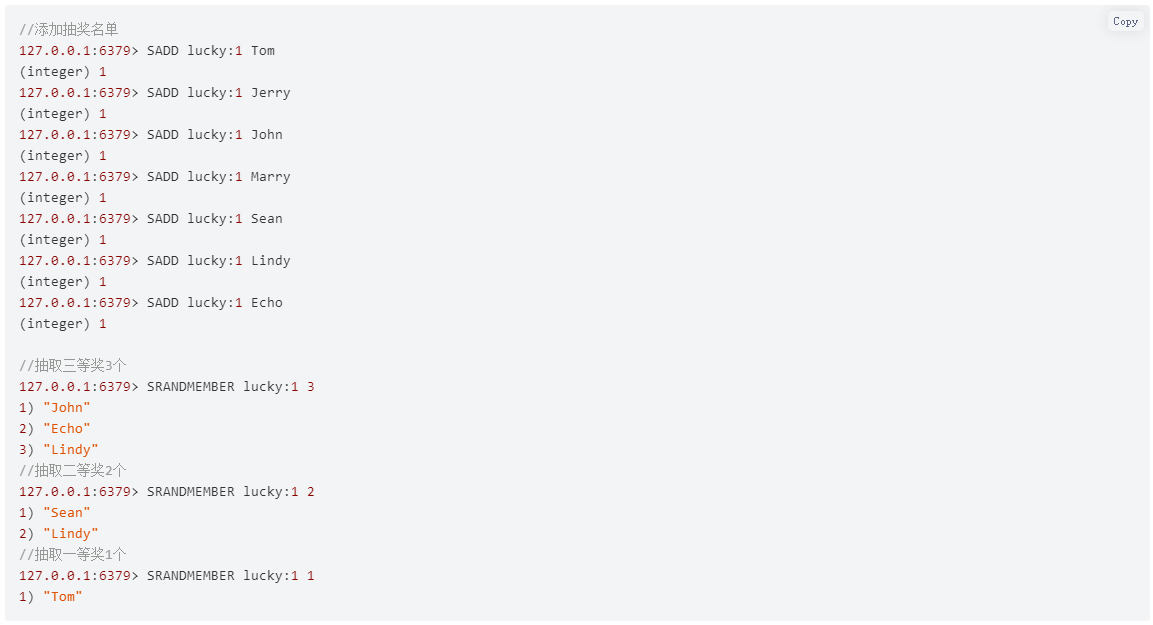
如果不允许重复中奖,可以使用 SPOP 命令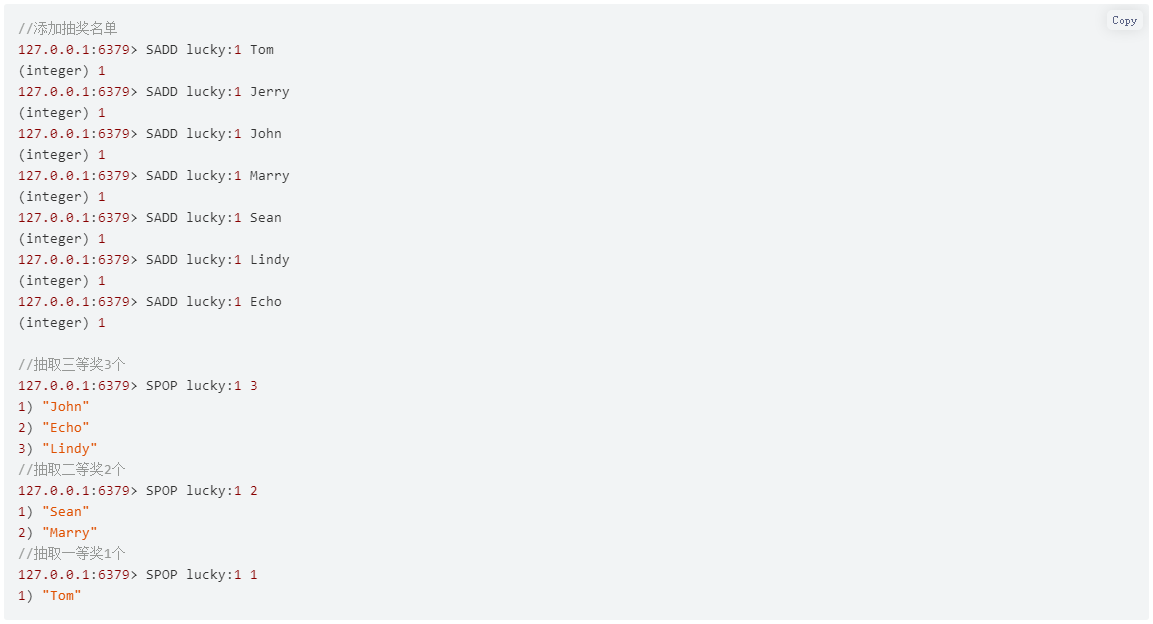
注意:
- Redis 2.6版本开始SRANDMEMBER命令支持Count参数。
- Redis 3.2版本开始SRANDMEMBER命令支持Count参数。
- 其余低版本一次只能获取一个随机元素
4.4 小结
本篇文章我们总结了Redis 集合对象的内部实现、常用命令以及常用的一些场景。
五、有序集合
有序集合类型 (Sorted Set或ZSet) 相比于集合类型多了一个排序属性 score(分值),对于有序集合 ZSet 来说,每个存储元素相当于有两个值组成的,一个是有序结合的元素值,一个是排序值。有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。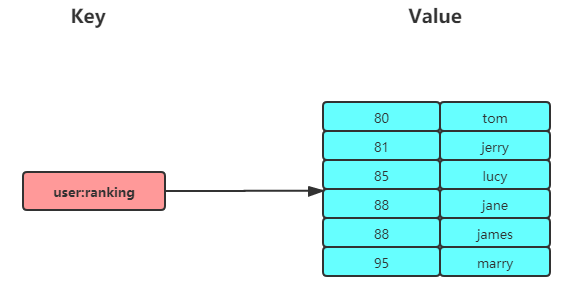
5.1 内部实现
- 有序集合是由 ziplist (压缩列表) 或 skiplist (跳跃表) 组成的。
- 当数据比较少时,有序集合使用的是 ziplist 存储的,有序集合使用 ziplist 格式存储必须满足以下两个条件:
- 有序集合保存的元素个数要小于 128 个;
- 有序集合保存的所有元素成员的长度都必须小于 64 字节。
如果不能满足以上两个条件中的任意一个,有序集合将会使用 skiplist 结构进行存储。
- 有关ziplist 和skiplist 这两种redis底层数据结构的具体实现可以参考我的另外两篇文章。
Redis数据结构——压缩列表
Redis数据结构——跳跃表。
5.2 常用命令(略)
5.3 使用场景
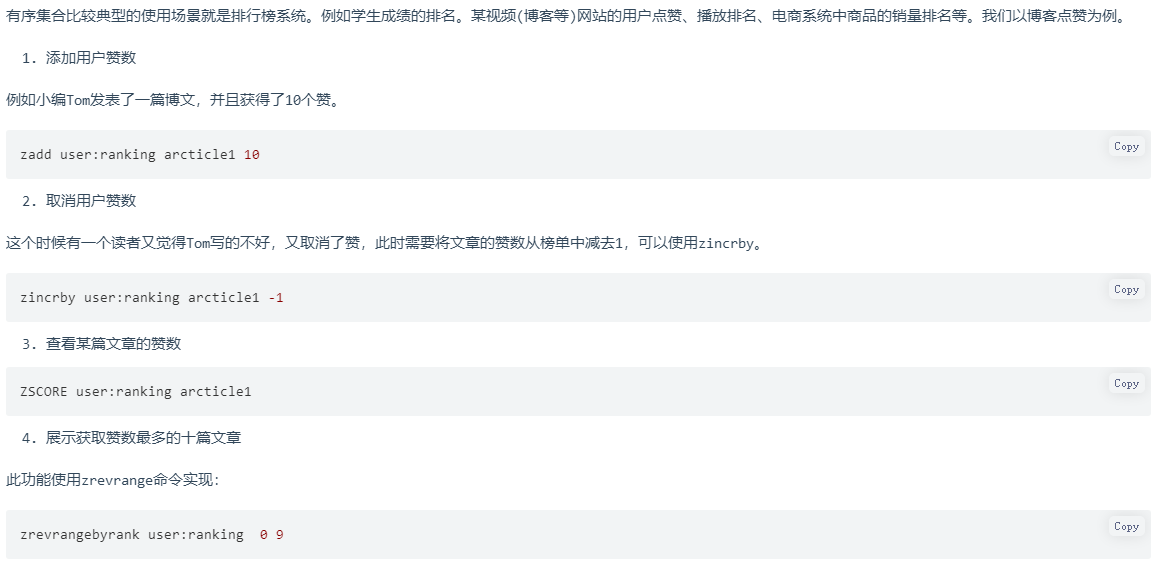
5.3.1 排行榜系统
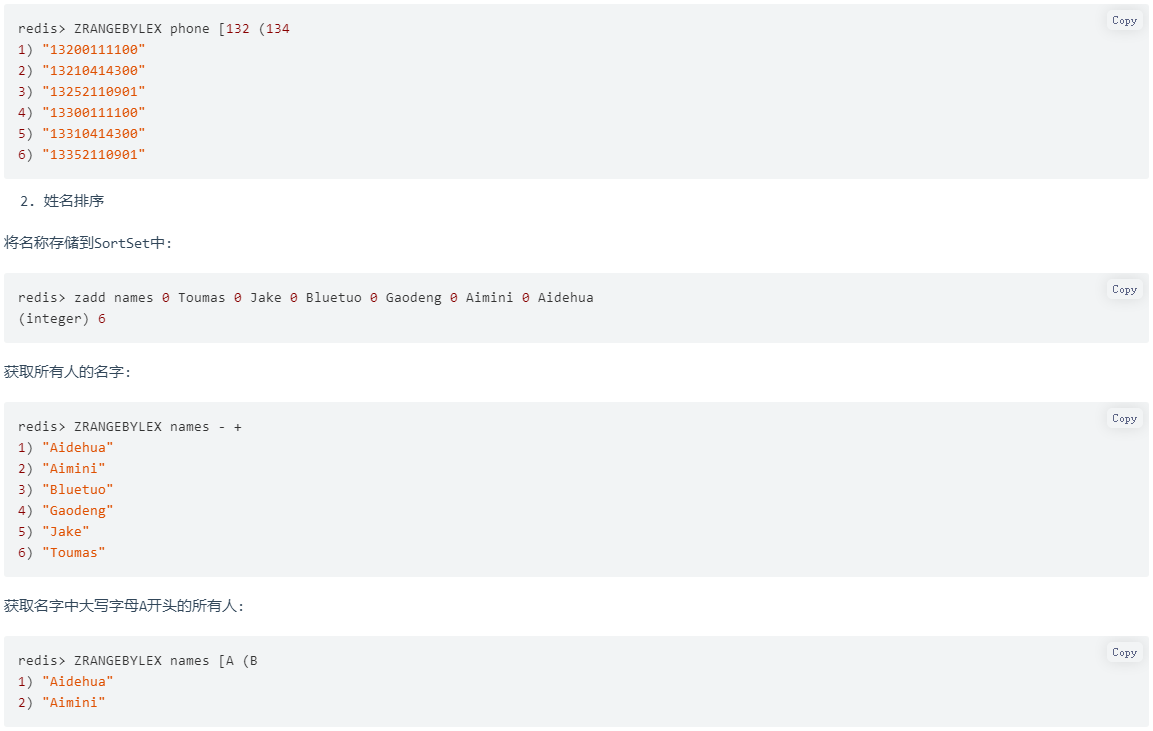
5.3.2 电话号码(姓名)排序
使用有序集合的ZRANGEBYLEX(点击可查看该命令详细说明)或ZREVRANGEBYLEX可以帮助我们实现电话号码或姓名的排序,我们以ZRANGEBYLEX为例 注意:不要在分数不一致的SortSet集合中去使用 ZRANGEBYLEX和 ZREVRANGEBYLEX 指令,因为获取的结果会不准确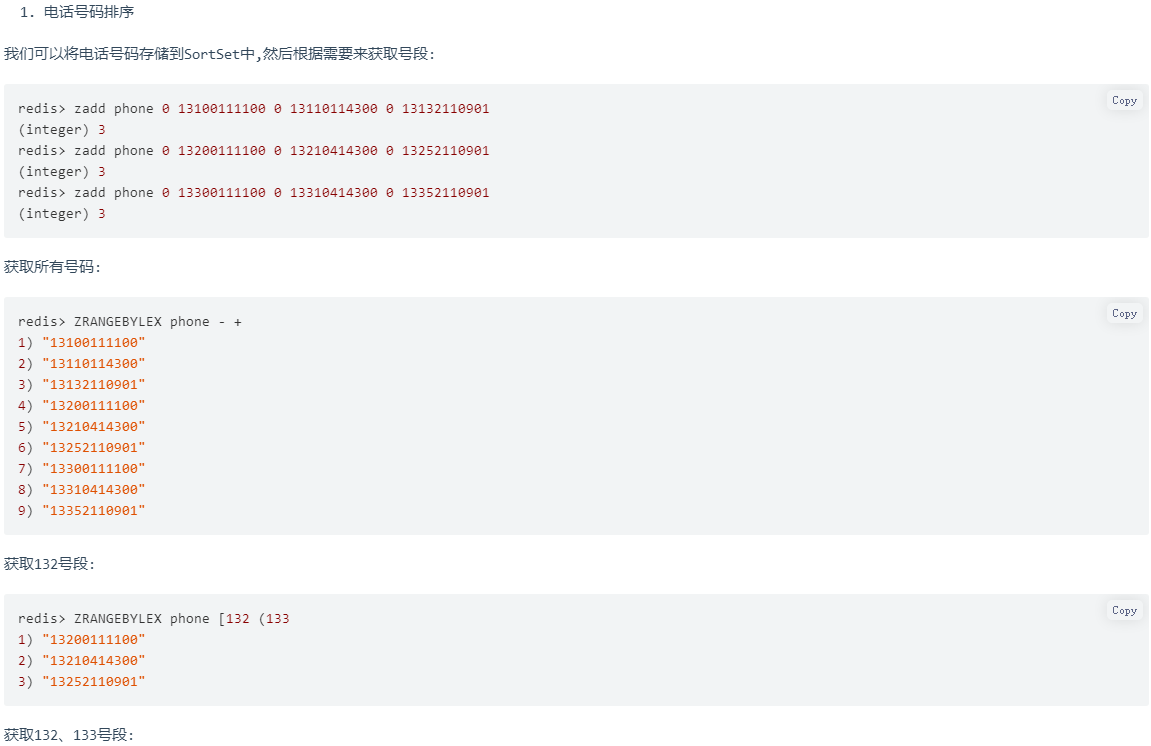

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









