







贪婪算法(又称贪心算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。- 贪婪算法不是对所有问题都能得到整体最优解,关键是贪婪策略的选择,选择的贪婪策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关。
1. 问题描述
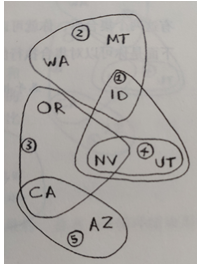
如下图所示,有5个广播台,以及8个州,每个广播台的覆盖范围只有几个州,现需要求得:最少需要那几个广播台能实现州的全覆盖
2. 工作原理
- 每次找出当前能覆盖州数最多的广播台(只注重当前最佳方案,是贪婪算法的核心)
- 那么本题的核心是:遍历当前模型,先找出一个当前能覆盖的州数最多的广播台
- 毫无疑问第一个被找出的广播台是kone,它覆盖了三个当前未被覆盖的州,分别是ID,NV,UT,于是kone被选中。
- 剩下的未被覆盖的州是:WA,MT,OR,CA,AZ
- 接着遍历,到了ktwo,它覆盖了两个当前未被覆盖的州,分别是WA,MT,在当前剩余的广播台中没有广播台比其覆盖当前未被覆盖的州数多了,那么接下来被选中的是ktwo
- 剩下的未被覆盖的州是:OR,CA,AZ
- 同理,接下来第三次循环,被选中的是kthree,它覆盖了两个当前未被覆盖的州,分别是OR,CA
- 剩下的未被覆盖的州是:AZ
- 然后,关键第四次循环了,按流程,下一次到kfour了,但是,其覆盖当前未被覆盖的州数为0,kfive覆盖当前未被覆盖的州数为1,此时kfive覆盖当前未被覆盖的州数目最多,于是剩下的被选中的广播台是kfive
- 算法执行结束
3. 建立模型
stations = {}
stations["kone"] = set(["id","nv","ut"]) #广播一
stations["ktwo"] = set(["wa","mt","id"]) #广播二
stations["kthree"] = set(["or","ca","nv"]) #广播三
stations["kfour"] = set(["nv","ut"]) #广播四
stations["kfive"] = set(["ca","az"]) #广播五
4. 创建数据
states_needed = set(["mt","wa","or","id","nv","ut","ca","az"]) #所有需要覆盖的州
5. 算法实现
final_stations = set() #最终选择的广播台集合
while states_needed: #当所有的州都被覆盖后终止循环
best_station = None #记录当前覆盖未被覆盖的州数目最多的广播台
states_covered = set() #记录某广播台覆盖(覆盖当前未被覆盖的州)的最大数目,理解类似于冒泡排序中的当前最大值
for station,states in stations.items(): #遍历上面的广播台覆盖模型,station对应广播台,states对应该广播台覆盖的所有州
covered = states_needed & states #求当前还未覆盖的州与此广播台覆盖的州的交集,便于后面求出当前覆盖的州最多的广播台
if(len(covered)>len(states_covered)): #如果当前州覆盖的还未覆盖的州数目大于此轮循环覆盖最大的州数
best_station = station #更新当前覆盖最多未覆盖州数目的广播台
states_covered = covered #更新当前覆盖的州
states_needed -= states_covered #当前未被覆盖的州
final_stations.add(best_station) #将被选择的州填入最终的广播台集合
6. 执行结果
print(final_stations) #打印最终选择的广播台
{'kfive', 'kthree', 'ktwo', 'kone'}
这里按照算法,填入final_stations的顺序应该是:kone,ktwo,kthree,kfive (由于python的set集合会自动排序,故输出结果按照上图所示)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









