






 本文介绍了Scrapy,一个开源的网络爬虫框架,详细阐述了其在数据获取、处理、存储和高级特性的应用,包括跟踪链接、频率限制、数据清洗、错误处理以及持久化存储,为高效数据抓取提供全面支持。
本文介绍了Scrapy,一个开源的网络爬虫框架,详细阐述了其在数据获取、处理、存储和高级特性的应用,包括跟踪链接、频率限制、数据清洗、错误处理以及持久化存储,为高效数据抓取提供全面支持。
在互联网的海洋中,数据是无处不在的。如何有效地获取并处理这些数据,一直是许多研究人员和开发者所关注的问题。Scrapy,作为一个强大的网络爬虫框架,为我们在处理这个问题时提供了全新的解决方案。
一、Scrapy简介
Scrapy是一个开源的、用于抓取网页并从中提取数据的架构。它具有强大的可扩展性,能适应各种复杂的情况。Scrapy的主要目标是让数据采集变得简单、快速且高效。
对于课本上、网上稍微繁杂的流程图,这里结合了一个简单的案例重构了一遍流程图,方便理解流程和案例。如下图1所示:
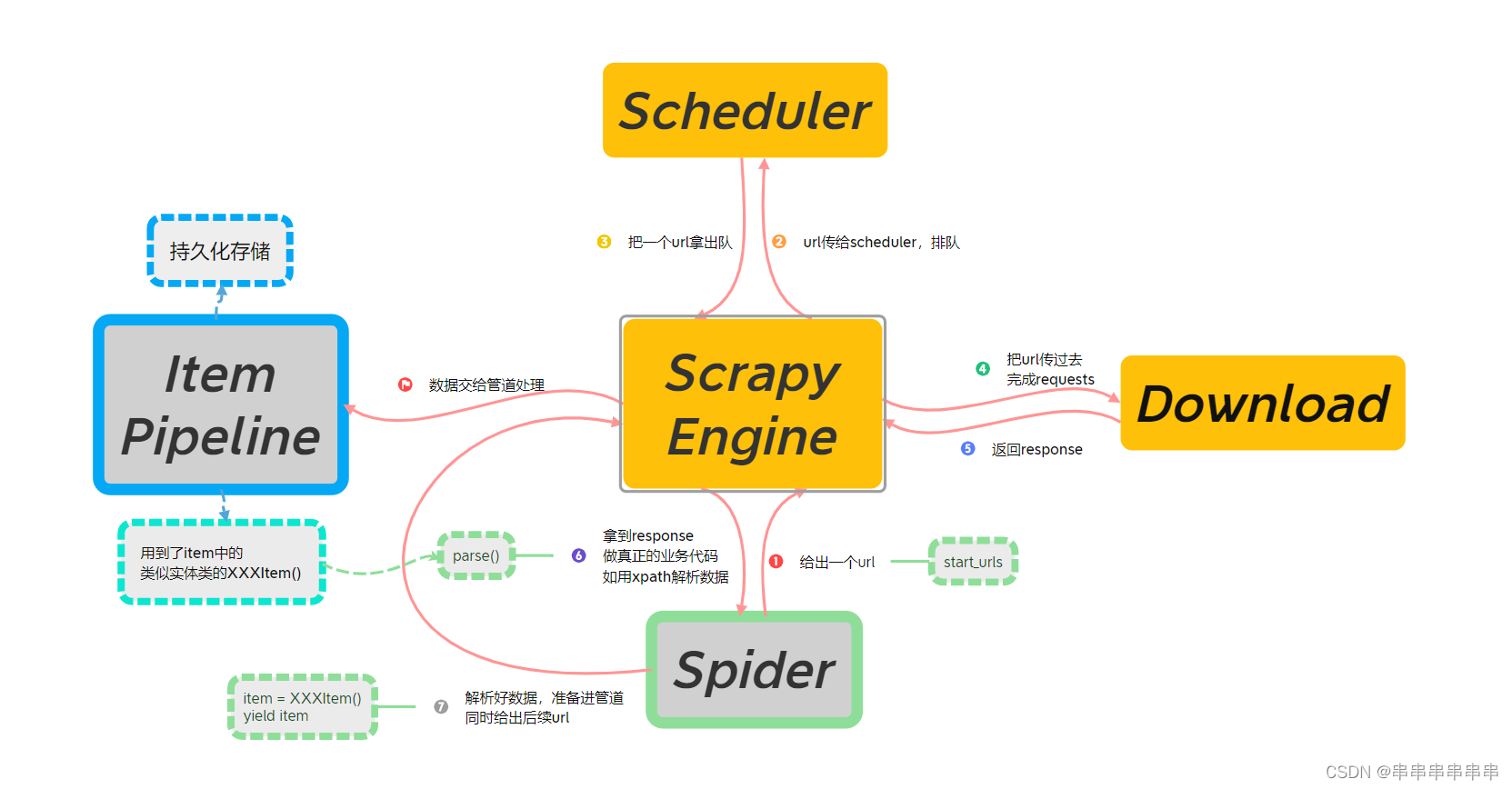
图1:Scrapy框架结合章节练习案例代码联动解析
对于现阶段入门学习,一个简单的scrapy项目我们暂时不需要管橙色部分结构,像Scheduler调度器、Download下载器、Scrapy Engine引擎还有未标出来的中间件,在课本和网上都有大量解释,此处不再赘述。当前我们只要关心绿色部分的爬虫Spider,还有蓝色部分实体类Item和管道Pipeline。以下是结合我们第一次Scrapy项目进行的流程+代码分析:
1、在Item部分:我们确定好爬取需求后,先完成实体类的构造。
2、在Spider部分:在爬虫文件里,我们向start_urls数组放入要爬取的url连接,框架就会经过引擎、调度器、下载器等一系列操作,再会返回一个response结果回到Spider的解析函数里,我们只需要对返回结果进行数据解析,解析完成的数据通过实体类传向管道。
3、在Pipeline部分:对传送过来的数据进行持久化存储,包括进行本地文件存储(txt、json等文件格式存储)、数据库存储(如连接mongodb进行存储)
二、Scrapy的使用流程
使用Scrapy进行数据采集主要分为以下步骤:
1、安装Scrapy:在Windows 11操作系统瞎,(已经安装了Python和pip)通过打开CMD运行pip install scrapy命令来安装Scrapy。
2、创建Scrapy项目:通过运行scrapy startproject projectname命令来创建一个新的Scrapy项目。但是,在此之前我们需要使用cd命令,先进入到我们python项目常用的文件路径,再用前面的命令创建项目。
3、创建Spider爬虫:在Scrapy项目中,Spider是用来定义如何从一个或多个网站中抓取数据的工具。我们仍然是先用cd命令,从前面的项目路径,进入到scrapy项目里的Spider文件夹里,再通过运行scrapy genspider spidername domainname命令来创建一个新的Spider爬虫文件。
4、修改实体类文件:类似JAVA实体类,我们往item.py文件里写入需要的item类字段,供spider调用。
5、配置Spider:在Scrapy项目的Spider文件夹中,可以找到一个名为spider.py的文件。在这个文件中,你可以定义Spider的行为,比如要抓取哪些URL,如何解析响应等。
6、修改管道文件:可以对数据进行持久化存储,可以对爬取数据进行本地文件存储(如txt、excel等格式存储),或者连接数据库进行存储(如连接mongodb进行存储)。
7、修改setting文件:见表2,在表2进行部分常用字段分析,包括显示日志、开启管道等。
8、执行Spider:通过在命令行中输入scrapy crawl spidername命令来运行Spider。或者创建start.py启动文件,然后输入以下2行代码,并右键运行star.py在pycharm中启动程序:
from scrapy import cmdline
cmdline.execute("scrapy crawl spidername".split())对以上流程进行简单总结,归纳为4大步骤,如下表所示:
表1:Sprapy项目的创建步骤
| 步骤 | 详细操作 | CMD命令\说明 |
| 创建scrapy项目 | 进入项目所在路径 创建scrapy项目 | cd C:\Users\Administrator\PycharmProjects scrapy startproject demo |
| 在pycharm里打开 | (也验证了我们创建成功了) | |
| 创建爬虫 | 进入spiders文件夹 创建爬虫 | cd demo/demo/spiders scrapy genspider itcasthsn "itcast.cn" |
| 修改实体类文件 item.py | (item.py文件,类似定义实体类) name = scrapy.Field() | |
| 修改爬虫文件itcasthsn.py | (itcasthsn.py文件parse方法里,主要使用xpath等方法) | |
| 数据处理 | 修改管道文件pipelines.py | 此处采取的是本地txt文件存储方案 |
| 修改配置文件setting.py | 开启管道等,详见表2 | |
| 执行爬虫 | 输入爬取指令 | start.py文件启动爬虫 |
表2:setting.py的一些设置
| 变量字段 | 备注 |
| ROBOTSTXT_OBEY | ROBOTSTXT_OBEY = True,默认为True,即遵守robots协议; |
| LOG_LEVEL | 添加LOG_LEVEL = ‘ERROR’,显示指定类型的日志,表示错误类型 |
| USER_AGENT | 修改自己的USER_AGENT="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"设置user_agent |
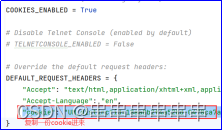
| COOKIES_ENABLED 和 DEFAULT_REQUEST_HEADER |
默认是False,设置成COOKIES_ENABLED = True 并如图去掉DEFAULT_REQUEST_HEADERS的注释,开启请求头 |
| ITEM_PIPELINES |
去掉注释,开启管道 |
| DOWNLOAD_DELAY | 设置download延时,降低网页访问速度,防止反爬。如,设置成DOWNLOAD_DELAY = 2 |
以下给出本次scrapy项目的相关代码:
item部分:
import scrapy
class DemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 用于存储
name = scrapy.Field()
title = scrapy.Field()
info = scrapy.Field()spider部分:
import scrapy
from demo.items import DemoItem
# 获取讲师数据
class ItcasthsnSpider(scrapy.Spider):
name = "itcasthsn"
# allowed_domains = ["itcast.cn"]
# start_urls = ["https://itcast.cn"]
start_urls = ["https://www.itcast.cn/channel/teacher.shtml#ajavaee"]
def parse(self, response):
# items = [] /html/body/div[1]/div[6]/div/div[2]/div[6]/div/div[2]/div[1]/ul/li/div
list = response.xpath('/html/body/div[1]/div[6]/div/div[2]/div[6]/div/div[2]/div[1]/ul/li/div')
for each in list:
# extract可以将selector对象中的data参数存储的字符串提取出来
name = each.xpath("h3/text()").extract()
title = each.xpath("h4/text()").extract()
info = each.xpath("p/text()").extract()
item = DemoItem() # 实例初始化
item["name"] = name[0] # 实例set
item["title"] = title[0]
item["info"] = info[0]
# print(item)
yield item # yield生成器类似return,区别是yield写在循环里,多次提交给管道pipelines的process_item
# print(items)
# return itemsPipeline部分:
from pymongo import MongoClient
class DemoPipeline:
f = None
# 重写open_spider方法,该方法只在爬虫开始时,被调用一次
def open_spider(self, spider):
print("开始爬取")
self.f = open('./teacher1.txt', 'w', encoding='utf-8')
# 专门用于处理item对象
# 接收爬虫文件提交过来的item对象
# 每接收到一个item对象,就会被调用一次
def process_item(self, item, spider):
name = item["name"]
title = item["title"]
info = item["info"]
# print(name, info, title)
self.f.write(name + ":" + title + ":" + info + "\n")
return item # 会传递给下一个管道类,如下面的mongodbPipeline
# 重写close_spider,也只调用一次
def close_spider(self, spider):
print("结束爬虫")
self.f.close()显示结果:

三、Scrapy的高级特性
Scrapy除了基本的数据采集功能外,还具有许多高级特性。例如:
跟踪链接:Scrapy可以跟踪网页中的链接,从而抓取嵌套的页面。
限制抓取频率:在抓取数据时,可以设置等待时间以避免对目标网站造成过大的负载。
数据清洗:Scrapy提供了强大的数据清洗工具,可以帮助你从抓取的数据中提取所需的信息。
错误处理:当遇到错误时,Scrapy可以自动重试,并可以配置为在失败时发送电子邮件通知。
持久化:Scrapy可以将数据存储在数据库中,方便后续查询和使用。
四、结语
Scrapy是一个功能强大的网络爬虫框架,可以帮助我们快速、高效地抓取网络数据。通过使用Scrapy,我们可以轻松地从一个或多个网站中提取所需的信息,为我们的研究和工作提供有力的支持。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









