






目录
一、MapReduce 概述
MapReduce 是一种用于大规模数据集并行处理的编程模型,它具有高效、可靠、易于扩展等特点,被广泛应用于大数据处理领域。
MapReduce 是一种用于大规模数据集并行处理的编程模型,它具有高效、可靠、易于扩展等特点,被广泛应用于大数据处理领域。
1、MapReduce 的起源与发展
- MapReduce 最早由 Google 提出,其诞生源于 Google 面临的大规模数据处理需求。在互联网时代,数据量呈爆炸式增长,传统的数据处理方式已经无法满足需求。Google 为了解决这一问题,开发了 MapReduce 编程模型,以实现高效的大规模数据处理。
- 随着大数据时代的到来,MapReduce 迅速得到了广泛的关注和应用。许多开源软件项目,如 Hadoop,都实现了 MapReduce 编程模型,使得更多的企业和开发者能够利用这一技术进行大数据处理。
- 经过多年的发展,MapReduce 已经成为大数据处理的核心技术之一。它不仅在互联网行业得到了广泛应用,还在金融、医疗、科学研究等领域发挥着重要作用。
2、MapReduce 的核心思想
- 将复杂的计算任务分解为 Map 和 Reduce 两个阶段,这是 MapReduce 的核心设计理念。这种分解方式使得大规模数据处理变得更加简单和高效。
- 在 Map 阶段,输入数据被分割成多个小的数据集,每个数据集被分配给一个 Map 任务。Map 任务会对输入数据进行处理,将其转换为键值对的形式。通常,键是某个特定的属性,值是与该属性相关的数据。例如,对于文本处理任务,Map 任务可以将每个单词作为键,将单词出现的次数作为值。
- 在 Reduce 阶段,接收来自 Shuffle 阶段的键值对,对相同键的值进行合并和处理。Reduce 任务会对每个键的值进行聚合操作,例如求和、求平均值等。最终,Reduce 任务会生成输出结果,通常是一个键值对的集合。
- 通过分布式计算实现高效的数据处理。MapReduce 利用分布式计算的优势,将数据分布在多个节点上进行并行处理。这种方式可以大大提高数据处理的速度和效率,尤其是对于大规模数据集的处理。同时,MapReduce 还具有良好的容错性,即使某个节点出现故障,也不会影响整个作业的执行。
二、MapReduce 实现过程
1、Map 阶段
- Mapper 的参数
(1)KEYIN:map 阶段输入的 key 的类型。
(2)VALUEIN:map 阶段输入的 value 的类型。
(3)KEYOUT:map 阶段输出的 key 的类型。
(4)VALUEOUT:map 阶段输出的 value 的类型。 - map 函数
(1)重写关键所在。写入具体的业务逻辑,根据输入的键值对进行特定处理,生成新的键值对作为输出。
(2)使用 context.write (key, value) 完成数据传递,将处理后的键值对输出到下一个阶段(通常是 Shuffle 阶段)。 - Context
(1)当前环境的抽象概念,提供对环境相关信息的访问和管理能力。
(2)如读取输入数据、输出数据、报告进度、获取配置信息等。
(3)具体如 context.write 将键值对输出到下一个阶段(reduce 阶段)。 - run 方法
(1)先执行 setup,再循环(每次执行一遍 map),最后 cleanup。
(2)setup:在每个 Map 任务开始时执行一次,用于初始化工作,如打开文件、建立数据库连接等。
(3)循环中执行具体的 map 逻辑,对输入数据进行处理并输出键值对。
(4)cleanup:当所有输入数据都处理完毕后,调用 cleanup 方法进行清理工作,如关闭文件、断开数据库连接等。
2、Shuffle 阶段
- 作用与重要性
(1)负责将 Map 阶段生成的键值对进行重新组合和排序。
(2)为后续的 Reduce 阶段提供高效的数据处理基础。 - 具体过程
(1)根据键进行分区,将相同键的键值对分配到同一个分区中。
(2)对每个分区中的键值对按照键进行排序。
3、Reduce 阶段
- Reducer 的参数
(1)KEYIN:reduce 阶段输入的 key 的类型,与 Mapper 输出的 key 类型相对应。
(2)VALUEIN:reduce 阶段输入的 value 的类型,通常是一个可迭代的集合,包含了所有具有相同 key 的值。
(3)KEYOUT:reduce 阶段输出的 key 的类型。
(4)VALUEOUT:reduce 阶段输出的 value 的类型。 - reduce 函数
(1)重写关键所在。接收来自 Shuffle 阶段的键值对,对相同 key 的值进行合并和处理。
(2)根据具体的业务需求进行聚合操作,如求和、求平均值等。
(3)使用 context.write (key, value) 输出处理后的键值对。 - Context
与 Mapper 中的 Context 类似,用于输出数据、报告进度等操作。 - run 方法
(1)先执行 setup,进行一些初始化工作。
(2)然后对于每个输入的键值对,调用 reduce 函数进行处理。
(3)最后执行 cleanup,进行清理工作。
4、Driver 阶段
- 设置作业配置
(1)设置输入输出路径,指定输入数据的来源和输出结果的存储位置。
(2)设置 Map 和 Reduce 任务的数量,根据数据规模和集群资源进行合理配置。
(3)设置其他相关参数,如数据格式、压缩方式等。 - 启动任务
(1)创建 Job 对象,用于表示一个 MapReduce 作业。
(2)设置 Mapper、Reducer、输入输出格式等作业的各个组件。
(3)提交作业到集群,启动 Map 和 Reduce 任务的执行。 - 监控任务执行状态
(1)通过查询作业的状态信息,了解作业的执行进度。
(2)处理作业失败的情况,进行错误处理和重试。
(3)确保作业能够顺利完成,或者在出现问题时及时采取措施。
三、案例分析
某中学一次月考后,有一份某年级学生的成绩表,现要求统计本次月考各科目平均成绩,其中部分内容和平均成绩如下所示:
表1:部分学生成绩和全年级最终平均成绩
| Sno | Course | Grade | Sno | Course | Grade | → | Course | Avg_grade |
| 202101 | 语文 | 96 | 202102 | 语文 | 109 | 语文 | 59 | |
| 202101 | 数学 | 149 | 202102 | 数学 | 118 | 数学 | 75 | |
| 202101 | 英语 | 130 | 202102 | 英语 | 141 | 英语 | 69 | |
| 202101 | 物理 | 90 | 202102 | 物理 | 78 | 物理 | 50 | |
| 202101 | 化学 | 44 | 202102 | 化学 | 99 | 化学 | 74 | |
| 202101 | 生物 | 99 | 202102 | 生物 | 70 | 生物 | 53 |
1、Map 阶段
- 对于输入的CSV文件的每一行,Map 任务根据CSV文件特性是用split方法以“,”形式将其分割成三部分,分别是学号、学科、分数存储到一个col数组里,并生成键值对,其中键是学科,值是 分数。
- 例如,对于输入的文本行 “202100001,语文,73”,Map 任务会生成键值对:(“语文”, 73) 。
package com.hadoop.mapreduce.averagescore;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class AvgScoreMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outkey = new Text();
private IntWritable outvalue = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] col = line.split(",");
//202100001 语文 73
outkey.set(col[1]);
outvalue.set(Integer.parseInt(col[2]));
context.write(outkey, outvalue);
}
}2、Shuffle 阶段
- 将 Map 阶段生成的键值对进行重新组合和排序。
- 相同键的键值对分配到同一个分区中,并按照键进行排序。
3、Reduce 阶段
- Reduce 任务接收来自 Shuffle 阶段的键值对,对相同键的值进行合并和处理。
- 对每个学生的同一学科分数求和,生成最终的输出结果。
- 例如,对于键 “语文”,Reduce 任务会接收多个键值对,如 (“语文”, 73)、(“语文”, 110)、(“语文”, 106) 等,然后将这些值进行求和,并除以总数,得到最终的输出结果 (“语文”, 59)。
package com.hadoop.mapreduce.averagescore;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class AvgScoreReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable outvalue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
int avg = 0;
for (IntWritable value : values) {
sum += value.get();
count++;
}
avg = sum / count;
outvalue.set(avg);
context.write(key, outvalue);
}
}
4、Driver 阶段
- 设置作业的配置参数,如输入输出路径、Map 和 Reduce 任务的数量等。
- 启动 MapReduce 作业,并监控作业的执行状态,确保作业能够顺利完成。
package com.hadoop.mapreduce.averagescore;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class AvgScoreDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置jar路径
job.setJarByClass(AvgScoreDriver.class);
//3.关联mapper和reducer
job.setMapperClass(AvgScoreMap.class);
job.setReducerClass(AvgScoreReduce.class);
//4.设置map输出的key、value类型,前面WordCountMap里的后2个参数Text, IntWritable
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.设置最终输出的key、value类型,前面WordCountReduce里的后2个参数Text, IntWritable
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\hsn\\java\\Hadoop\\MapReduce\\averagescore\\input"));//输出文本test.txt所在的windows路径
FileOutputFormat.setOutputPath(job, new Path("D:\\hsn\\java\\Hadoop\\MapReduce\\averagescore\\output\\output1"));//输出结果所在的windows路径
//7.提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
查看part-r-00000文件,语数英物化生平均分最终结果截图如下: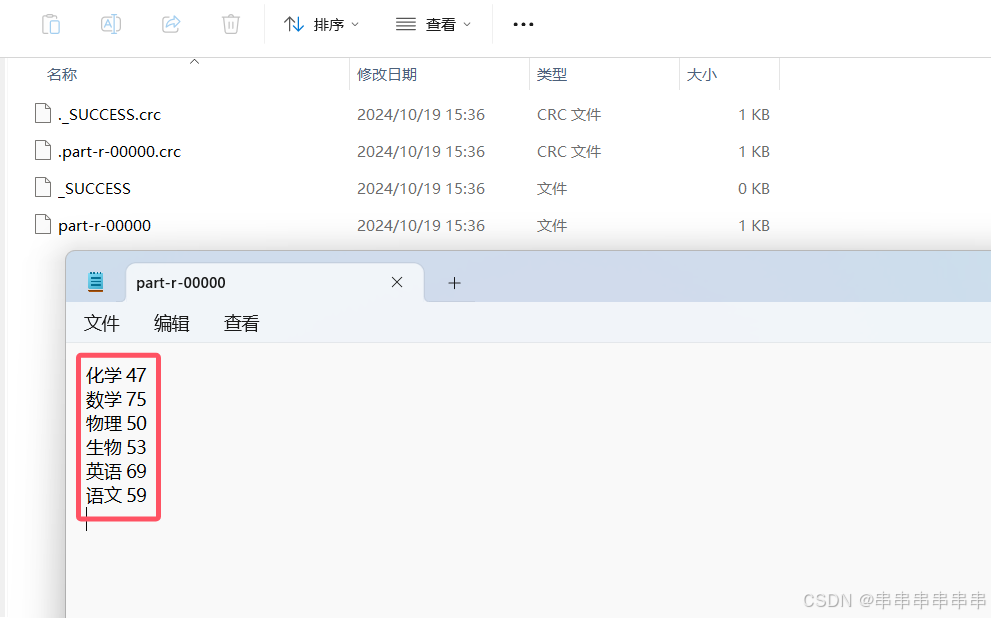
图1:案例结果截图
通过这个案例,我们可以看到 MapReduce 如何将一个复杂的计算任务分解为多个简单的阶段,并通过并行处理来提高计算效率。在实际应用中,MapReduce 可以用于处理各种大规模数据集的问题,例如数据分析、机器学习、搜索引擎等。
写在最后,MapReduce 是一种强大的编程模型,它能够帮助我们高效地处理大规模数据集。通过理解 MapReduce 的概念、实现过程以及继承 Mapper、Reducer、Driver 等类的方法,我们可以更好地应用 MapReduce 来解决实际问题。

















 1853
1853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









