







AmazonS3方法简述
我们影像的方式现在修改为了文件服务器的方式存储,使用的是H3C的文件存储,但是没有给对应的说明文档,就是说和AmazonS3的方法一样,于是我们就直接面对开源开发了。
依赖
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk-s3</artifactId>
<version>1.11.415</version>
</dependency>
不是很确定到底会不会有别的依赖,但是至少是应该有这个
基本方法
首先在这里说一下,其实使用方法基本上就是增删改差了,其实对于文件服务器来说我认为增删查就可以了,改的话意义不是很大我认为,就写一下调用增删查的demo了,这个是demo所以大家看的时候业务逻辑自己带入就可以了,增删查,对应的文件服务器的方法就是文件上传,文件删除,文件下载。
首先呢这里有一个需要新建一个连接,新建连接需要元素,akey,skey,endpoint,这三个元素因为是付费服务所以不便于展示
新建连接
String accessKey ="";
String accessKey ="";
String endpoint ="";
AmazonS3ClientBuilder client = AmazonS3ClientBuilder.standard();
ClientConfiguration config = new ClientConfiguration();
config.setProtocol(com.amazonaws.Protocol.HTTPS);
config.setConnectionTimeout(10001);
config.setSignerOverride("S3SignerType");
AWSCredentials acre = new BasicAWSCredentials(accessKey, secretKey);
AWSCredentialsProvider acrep = new AWSStaticCredentialsProvider(acre);
AwsClientBuilder.EndpointConfiguration econfig = new AwsClientBuilder.EndpointConfiguration(endpoint, null);
client.setClientConfiguration(config);
client.setCredentials(acrep);
client.setEndpointConfiguration(econfig);
AmazonS3 build = client.build();
因为保密所以accessKey ,accessKey ,endpoint 三个字段为空,但是你要是真的去使用的话千万不要写空的,经过这一段代码我们就产生了一个AmazonS3对象可以去进行代码的
文件上传
public static void shangchuan(AmazonS3 s3connt){
try {
String bucketname = "";
String upload_key = "1231231235.log";
File file = new File("logging.log");
InputStream input = new FileInputStream(file);
ObjectMetadata objectMetadata = new ObjectMetadata();
objectMetadata.setContentLength(Long.valueOf(input.available()));
objectMetadata.setContentType("plain/text");
PutObjectResult putObjectResult = s3connt.putObject(bucketname, upload_key, input, objectMetadata);
System.out.println(putObjectResult );
} catch (Exception e) {
e.printStackTrace();
}
}
其中bucketname 是桶名,也是一个AmazonS3的一个概念,好像是他们将空间分成一个一个的hash桶然后将文件存储在桶中,文件存储的时候调用的其中一个存储方法,其实存储方法不止一个,但是我在这边只写了这一个方式,putObject方法中需要将桶名传入,需要穿一个文件id,这个文件id是表名文件唯一性的唯一因素,这里只是demo所以我写死了,理论上来说这个应该是要UUID的,然后就是文件流,需要传入文件的文件流InputStream ,然后就是objectMetadata对象,按照我的代码中传递的参数传递一些参数即可。具体执行结果
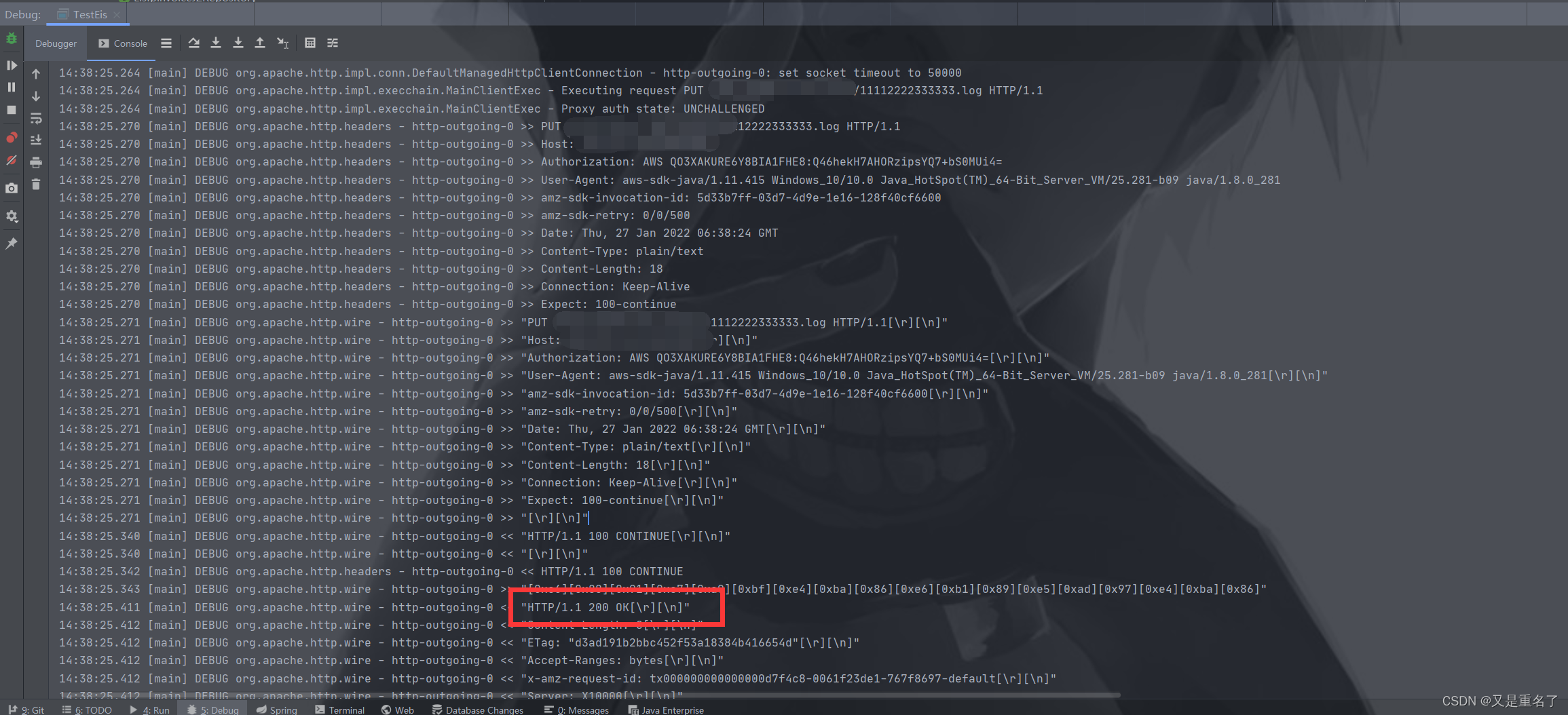
这是本地代码执行结果的日期,我已经将敏感信息屏蔽了,然后可以看到上面是我发出的报文,下面是我收到的报文,具体的情况大概就是我将文件流等信息发了出去,然后上传成功报文返回200,然后文件已经成功上传了。
文件下载
public static void xiazai(AmazonS3 s3connt){
try {
String bucketname = "";
String upload_key = "1231231235.log";
S3Object objData = s3connt.getObject(bucketname, upload_key);
//需要import 对应的类,请注意
S3ObjectInputStream s3ObjectInputStream = objData.getObjectContent();
InputStream inputStream = new BufferedInputStream(s3ObjectInputStream);
File file =new File("1.log");
OutputStream os = new FileOutputStream(file);
int bytesRead = 0;
byte[] buffer = new byte[8192];
while ((bytesRead = inputStream.read(buffer, 0, 8192)) != -1) {
os.write(buffer, 0, bytesRead);
}
} catch (Exception e) {
e.printStackTrace();
}
}
上面就是文件下载的具体代码,getObject方法需要传递参数就是桶名和文件名,文件名是唯一的,使用BufferedInputStream类将返回的流转换成inputstream然后将流的内容导入到本地方法中。
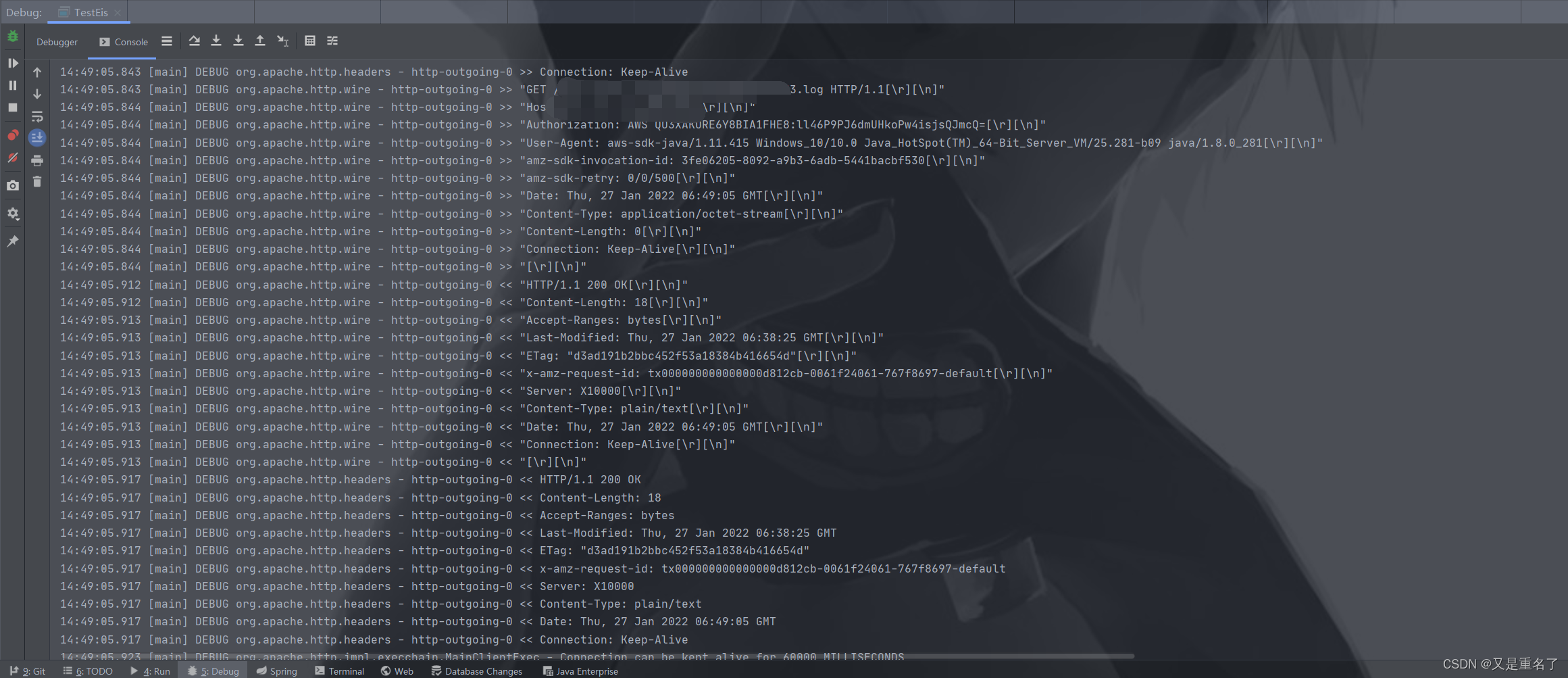
屏蔽关键信息之后执行日志。
文件删除
String bucketname = "";
String upload_key = "1231231235.log";
s3connt.deleteObject(bucketname,upload_key);
deleteObject方法传入桶名和文件名即可实现删除方法,不过很尴尬的一件事就是没有办法可以直接看到删除的结果。在询问了对应人员之后,对方建议这样使用,首先先文件删除接口,删除一个不存在的文件名,查看删除不存在的文件名是否会报错,如果不报错,那我们在调用文件下载接口传入一个不存在的文件名,查看结果,然后删除接口先删除一个已经可以下载的文件,然后调用下载接口,看查看不存在文件名的下载情况和删除文件之后再将此文件下载的情况是否一致
首先验证删除一个不存在的文件名是否有不一样地方
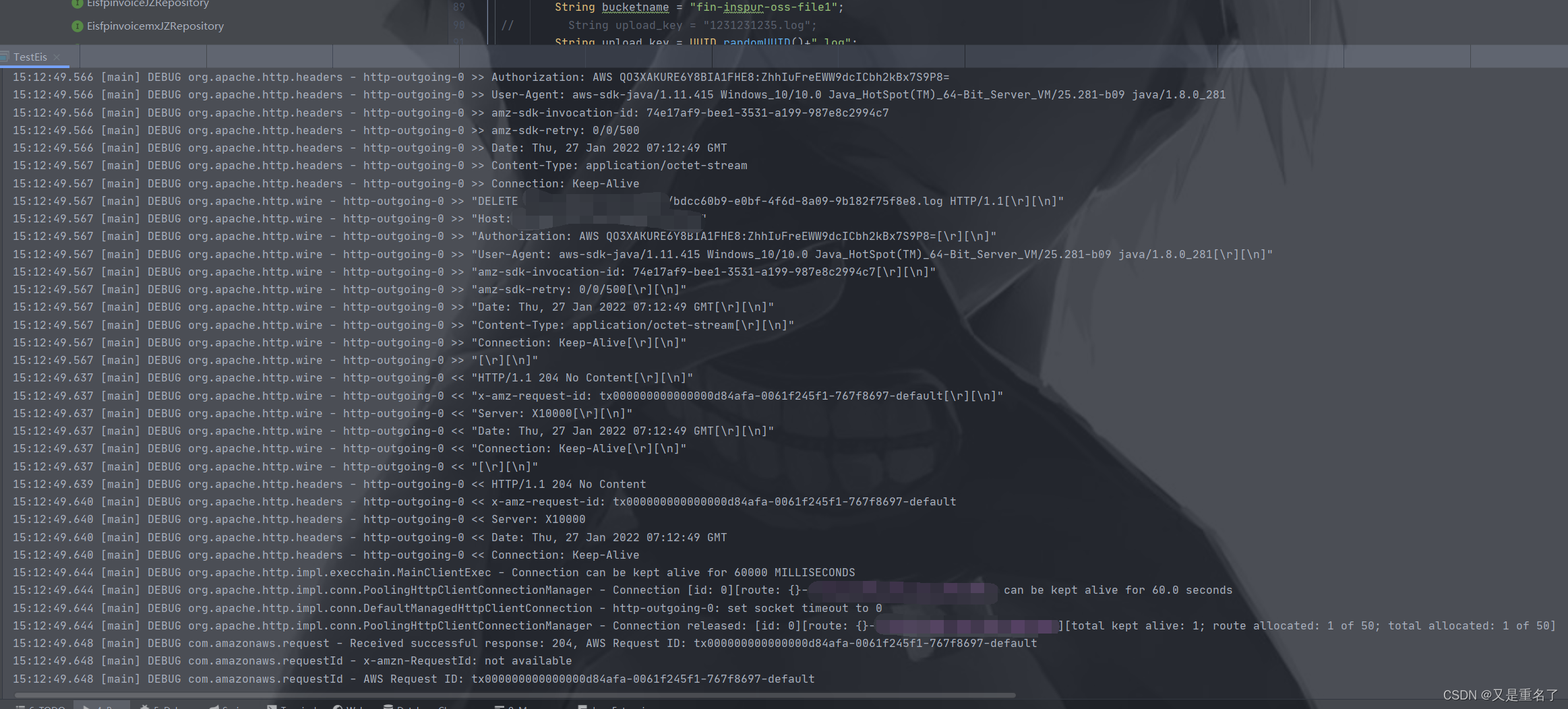
倒是也有不一样的地方,可以看到返回的http状态码是204不是200,那我们在尝试一下执行成功的删除的日志
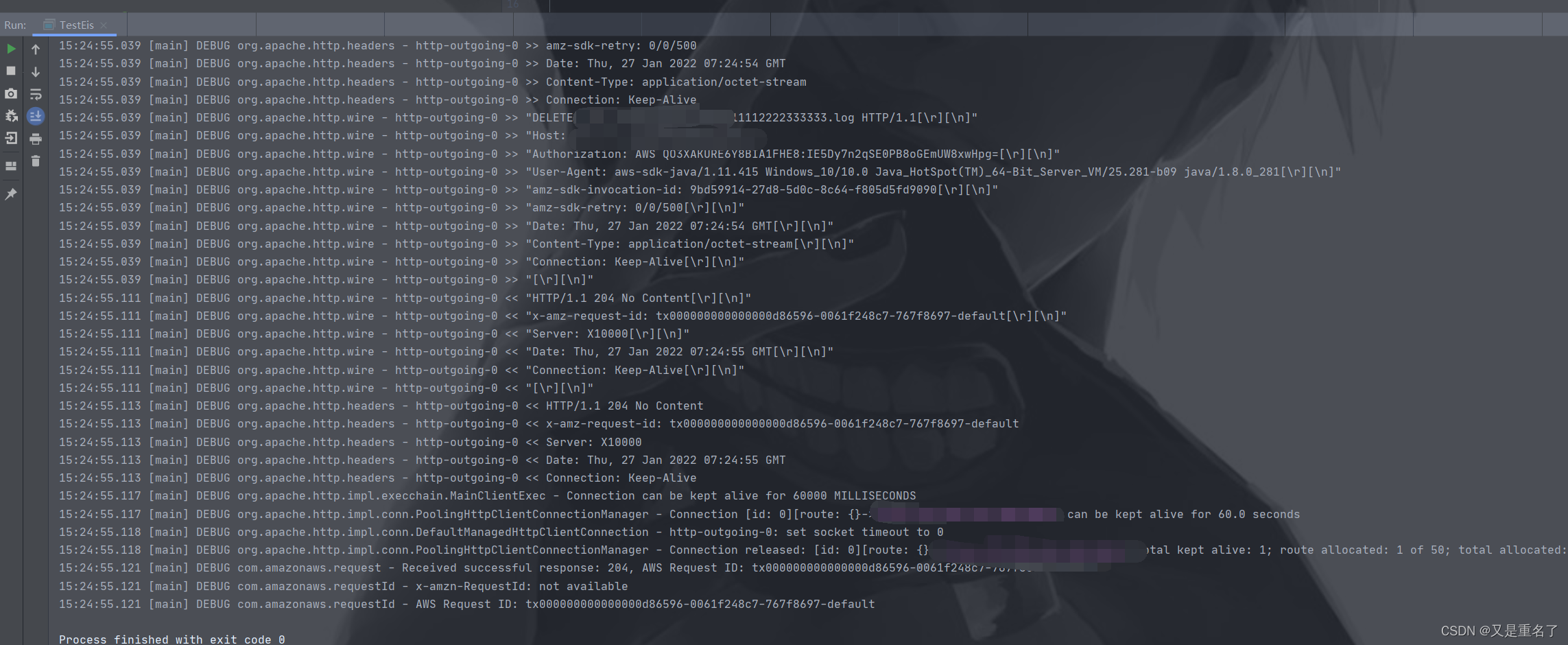
好了我比较了其实结果相差不大。
我们尝试下载一个不存在的文件名看看结果

结果提示404,这是没有这个文件下载文件之后的结果,我们在掉一下删除这个影像之后在调用下载接口之后的结果。
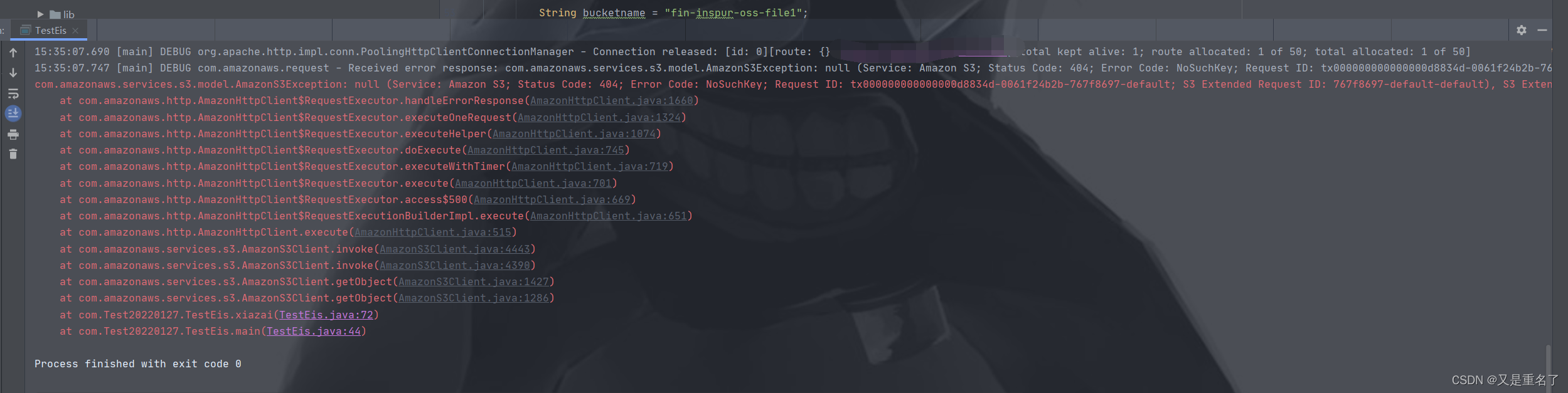
结果相差不多其实感觉,于是我们的删除接口已经测试完成了。
证明了我们的删除接口是成功的。
以上就是AmazonS3的基本使用方法介绍了。


















 1554
1554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











