










这道题思路很简单~依然用到并查集
首先,我们执行所有相等的约束条件,也就是说将为1的操作提前。我们合并输入的那两个数字xi xj所在的集合,执行完所有为1的操作以后,我们再执行所有为0的操作,如果发现xi,xj在同一个集合,则可以判断这个程序的约束条件不满足,输出NO,如果执行所有为0的操作以后,都不会出现xi,xj在同一个集合。则输出YES
就题目中的样例我们来解释一下~
我们截取一部分~
4
1 2 1
2 3 1
3 4 1
1 4 0
有4个约束条件,首先执行前面三个,集合合并以后就是这样。

然后执行最后一个约束条件 1 4 0,发现1 4在一个集合此时不满足。
思路是不是很简单呢?但是这道题目的数据量有点大,xi xj达到了10^9
我们不可能去开一个这么大的数组去存储并查集,一般数组100W最大了,10^9肯定会爆掉。所以我们要 离散化 ~关于离散化不会的 请点击这里
这道题采用离散化是为了能够开一个有限的数组空间去使用并查集操作~
对于一些数字,如果我们并不关心他的实际大小,只需要关心他们的相对大小,我们只需要找到相对大小关系即可。就比如有这些数字
100 500 300 90000
这些数字比较大小实际上等价于 1 3 2 4 这四个数字比较大小,我们并不关心数字本身是什么样的,我们只关心他们相对大小就可以了。换言之,如果对于一个并不关心实际大小,而是相对大小。我们就可以将其转换为另外一种形式,使他们的相对大小不变~
对于题目的输入,比如有这些数据
3
7982 6230 1
8231 5233 0
4296 9926 1
我们可以使其等价于
3
4 3
5 2
1 6
他们相对大小关系不变,我们完全可以用这些小的数字来代替上面的很大的数字。
方法也很简单,只需要使用lower_bound+unique这个两个STL即可。
对于unique这个要理解的话最好看一下STL的源码~
ForwardIt unique(ForwardIt first, ForwardIt last)
{
if (first == last)
return last;
ForwardIt result = first;
while (++first != last) {
if (!(*result == *first)) {
*(++result) = *first;
}
}
return ++result;
}
上面就是unique的源码
用a数组保存原来的数据,用b数组保存使用unique以后的数据


最后返会的结果就是result所指的地址
**可以看到,结合上面的源码和执行结果可以得到上面去重的原理是将不重复的移到前面来,但是我看到很多博主解释成了重复的移到后面去 **
去重以后就可以求他们的相对值了~
对于不重复元素的个数是cnt=result-b-1
for(int i=1;i<=8;i++)
{
a[i]=lower_bound(b+1,b+cnt+1,a[i])-b
]
上面代码的意思就是对于a数组中的每一个元素a[i],我们找到他在b数组中第一个大于等于a[i]的位置,对于a中的任意一个元素,用这种方式去查找得到的地址再减去b就是他在b数组中的位置了,因为b数组已经从小到大排好序了,所以他得到的位置用来更新a[i],可以使得更新后a数组中元素各个值相较于原a数组中值的相对大小不变~
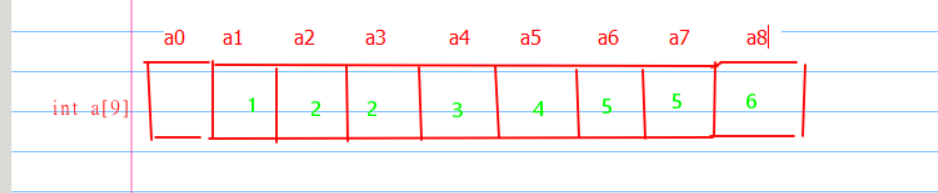
更新以后a数组的值是
下面是AC代码~
#include <iostream>
#include <algorithm>
#define Max 100005
using namespace std;
int par[Max];
struct Node
{
int x,y,w;
};
bool cmp(Node a,Node b);
int find_par(int x);
void unions(int x,int y);
Node a[Max];
int b[Max<<2];//用来求离散的数组
int main()
{
int t,n;
cin>>t;
bool flag;
while(t--)
{
cin>>n;
int j=0;
for(int i=1;i<=n;i++)
{
cin>>a[i].x>>a[i].y>>a[i].w;
b[++j]=a[i].x;
b[++j]=a[i].y;
}
sort(b+1,b+j+1); //从小到大排序
int num=unique(b+1,b+j+1)-b-1; //去重顺便求去重以后的大小
for(int i=1;i<=n;i++)
{
a[i].x=lower_bound(b+1,b+1+num,a[i].x)-b;
a[i].y=lower_bound(b+1,b+num+1,a[i].y)-b;
}
sort(a+1,a+n+1,cmp);
for(int i=1;i<=num;i++) //这里改成num 不是n
{
par[i]=i;
}
flag=true; //判断是否符合程序
for(int i=1;i<=n;i++)
{
if(a[i].w==1)
{
unions(find_par(a[i].x),find_par(a[i].y));
}
else
{
if(find_par(a[i].x)==find_par(a[i].y))
{
flag=false;
break;
}
}
}
if(flag)
{
cout<<"YES"<<endl;
} else{
cout<<"NO"<<endl;
}
}
return 0;
}
bool cmp(Node a,Node b)
{
return a.w>b.w; //由大到小排序
}
int find_par(int x)
{
return x==par[x] ? x:par[x]=find_par(par[x]);
}
void unions(int x,int y)
{
par[find_par(x)]=find_par(y);
}















 1510
1510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









