






pandas
所需数据以及代码
gitee地址:https://gitee.com/yu-min-guo/python13/tree/master/nodebooks
GitHub地址:https://github.com/kinderkk/Python13/tree/master/nodebooks
1、预备知识-python核心用法常用数据分析库
概述
Python 是当今世界最热门的编程语言,而它最大的应用领域之一就是数据分析。在python众多数据分析工具中,pandas是python中非常常用的数据分析库,在数据分析,机器学习,深度学习等领域经常被使用。使用 Pandas 我们可以 Excel/CSV/TXT/MySQL 等数据读取,然后进行各种清洗、过滤、透视、聚合分析,也可以直接绘制折线图、饼图等数据分析图表,在功能上它能够实现自动化的对大文件处理,能够实现 Excel 的几乎所有功能并且更加强大。
本实验将通过实战的方式,介绍pandas数据分析库的基本使用,让大家在短时间内快速掌握python的数据分析库pandas的使用,为后续项目编码做知识储备
实验环境
- Python 3.7
- PyCharm
任务一:环境安装与配置
【实验目标】
本实验主要目标为在Windows操作系统中,完成本次实验的环境配置任务,本实验需要的软件为PyCharm+Python 3.7
【实验步骤】
1、安装Python 3.7
2、安装Pycharm
3、安装jupyter、pandas、numpy、notebook
打开CMD,并输入以下命令,安装jupyter、notebook、pandas和numpy
pip install jupyter notebook pandas numpy
安装完成后会有类似如下文字提示:
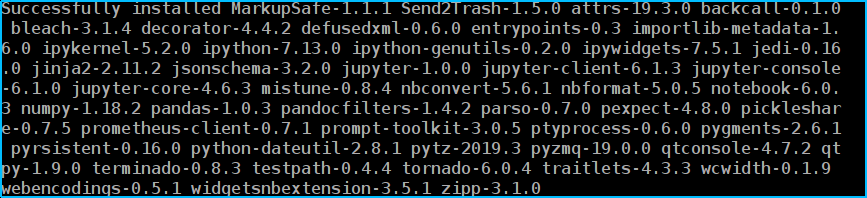
以上步骤完成后,实验环境配置工作即已完成,关闭CMD窗口
任务二:Pandas数据分析实战
【任务目标】
本任务主要目标为使用pandas进行数据分析实战,在实战过程中带大家了解pandas模块的一下功能:
- 准备工作
- 检查数据
- 处理缺失数据
- 添加默认值
- 删除不完整的行
- 删除不完整的列
- 规范化数据类型
- 重命名列名
- 保存结果
【任务步骤】
1、打开CMD,执行如下命令,开启jupyter
jupyter notebook
成功执行以上命令后,系统将自动打开默认浏览器,如下图所示:
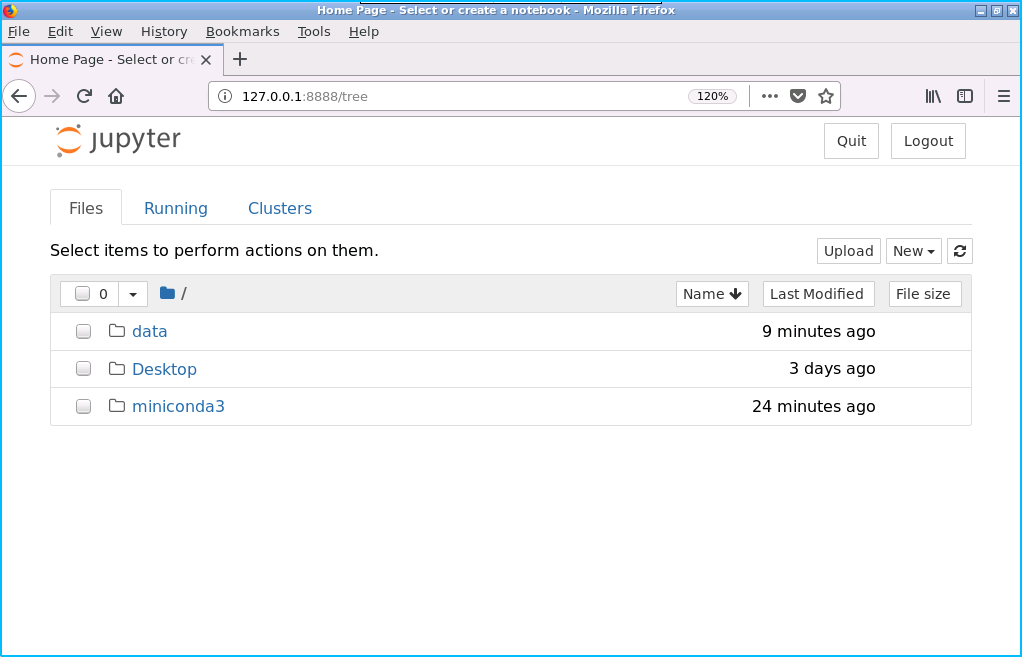
成功打开浏览器后,按如下流程创建 notebook 文件
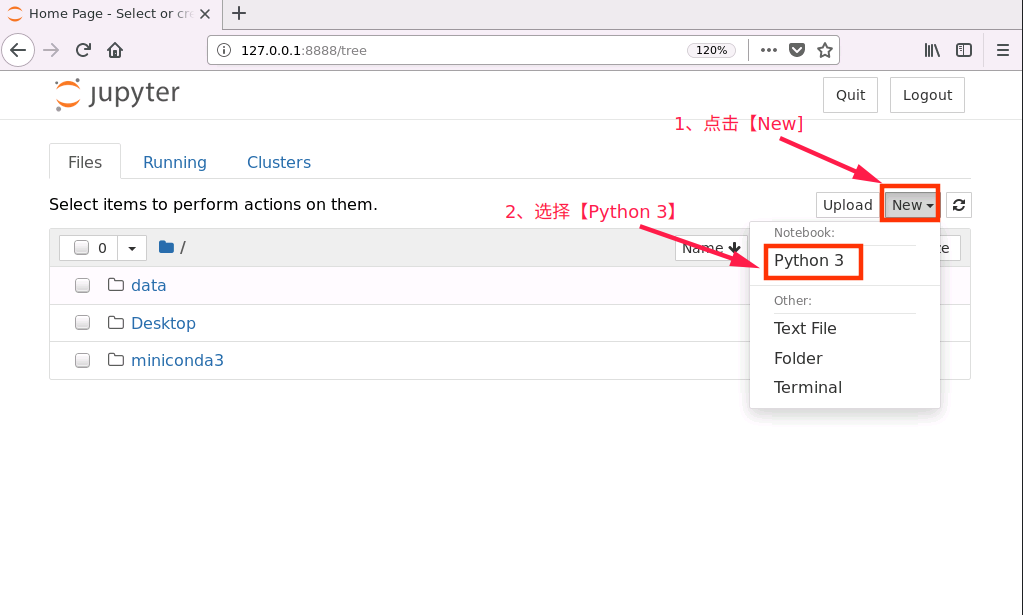
对新建notebook进行重命名操作
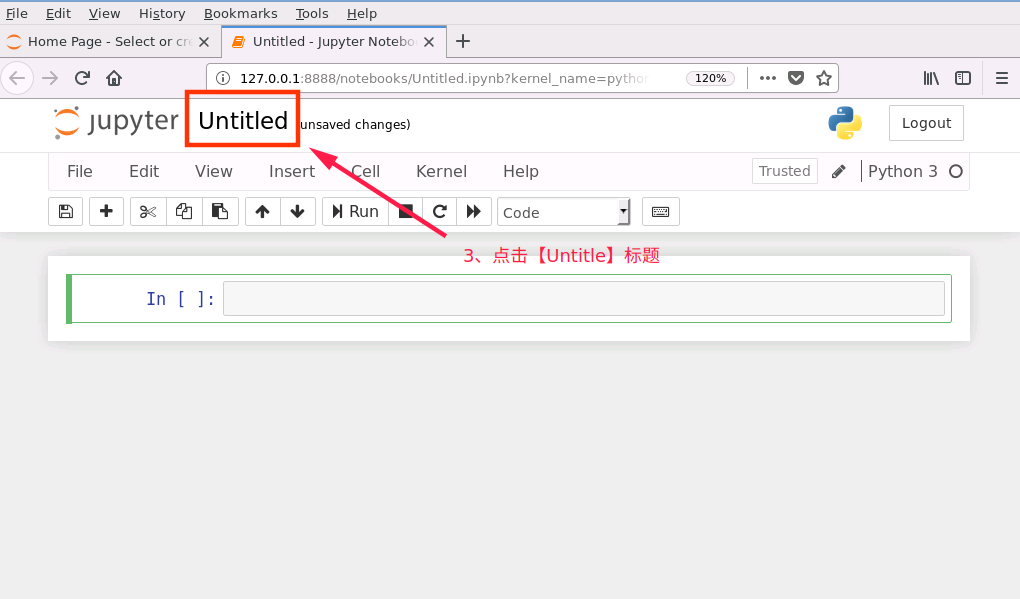
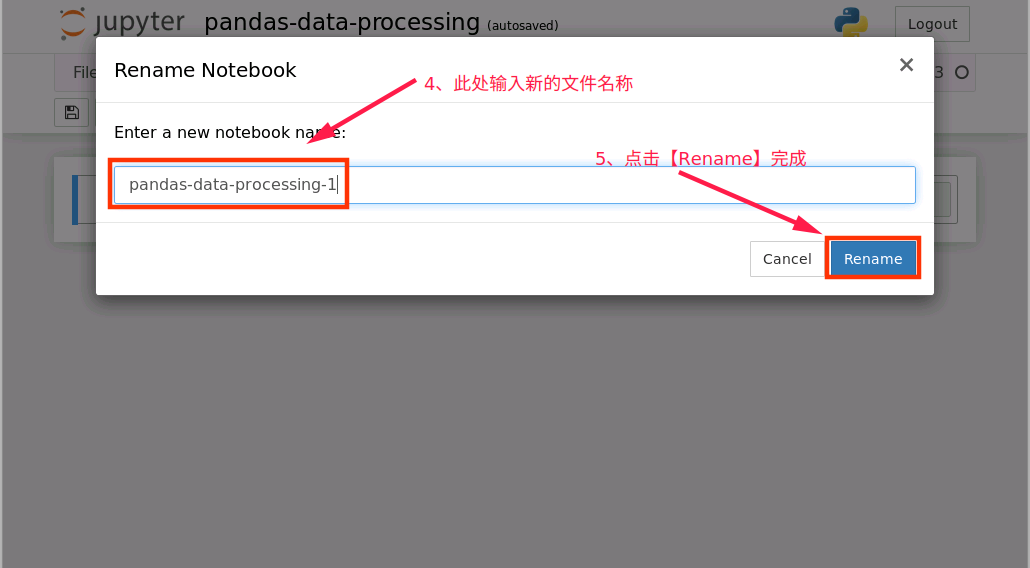
2、notebook 文件新建完成后,接下来在新建的 notebook 中编写代码
导入 Pandas 到我们的代码中,代码如下
import pandas as pd
小提示:输入完成代码后,按下【Shift + Enter】组合键即可运行该单元格中的代码,后面输入完每个单元格的代码后都需要进行类似操作,代码才会运行
加载数据集,代码如下:
data = pd.read_csv('./data/movie_metadata.csv')
3、检查数据
查看数据集前5行
data.head()
运行结果如下图所示:
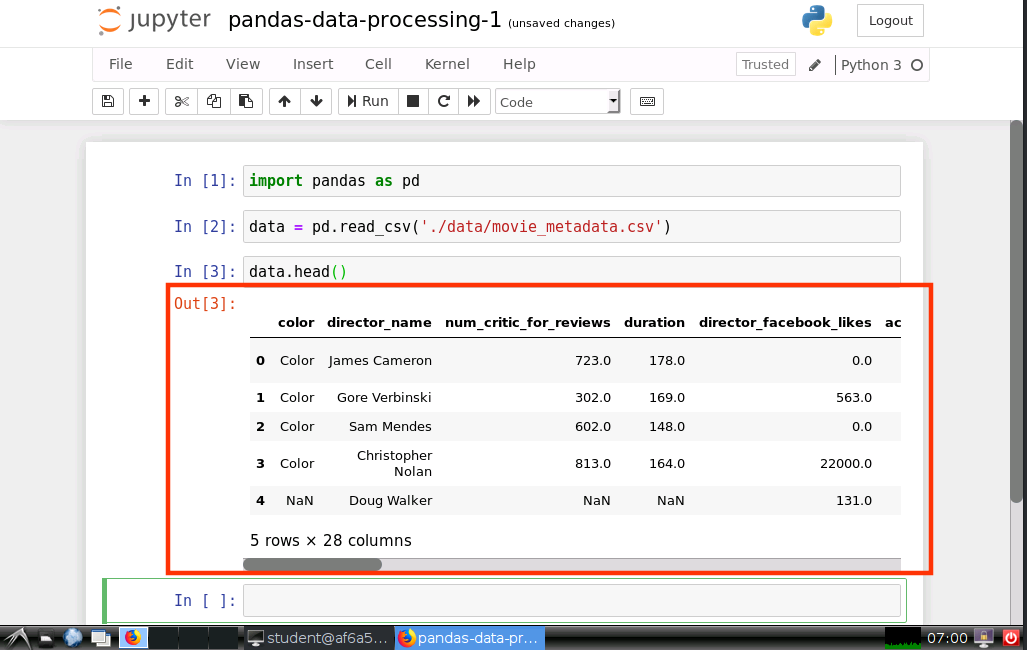
我们可以通过上面介绍的 Pandas 的方法查看数据,也可以通过传统的 Excel 程序查看数据
Pandas 提供了一些选择的方法,这些选择的方法可以把数据切片,也可以把数据切块。下面我们简单介绍一下:
- 查看一列的一些基本统计信息:data.columnname.describe()
- 选择一列:data[‘columnname’]
- 选择一列的前几行数据:data[‘columnsname’][:n]
- 选择多列:data[[‘column1’,‘column2’]]
- Where 条件过滤:data[data[‘columnname’],condition]
4、处理缺失数据
缺失数据是最常见的问题之一。产生这个问题有以下原因:
- 从来没有填正确过
- 数据不可用
- 计算错误
无论什么原因,只要有空白值得存在,就会引起后续的数据分析的错误。下面介绍几个处理缺失数据的方法:
- 为缺失数据赋值默认值
- 去掉/删除缺失数据行
- 去掉/删除缺失率高的列
4.1、添加默认值
使用空字符串来填充country字段的空值
data.country= data.country.fillna('')
使用均值来填充电影时长字段的空值
data.duration = data.duration.fillna(data.duration.mean())
4.2、删除不完整的行
data.dropna()
运行结果如下(由于输出内容给较多,结果中省略了中间部分数据,只显示开头和结尾部分):
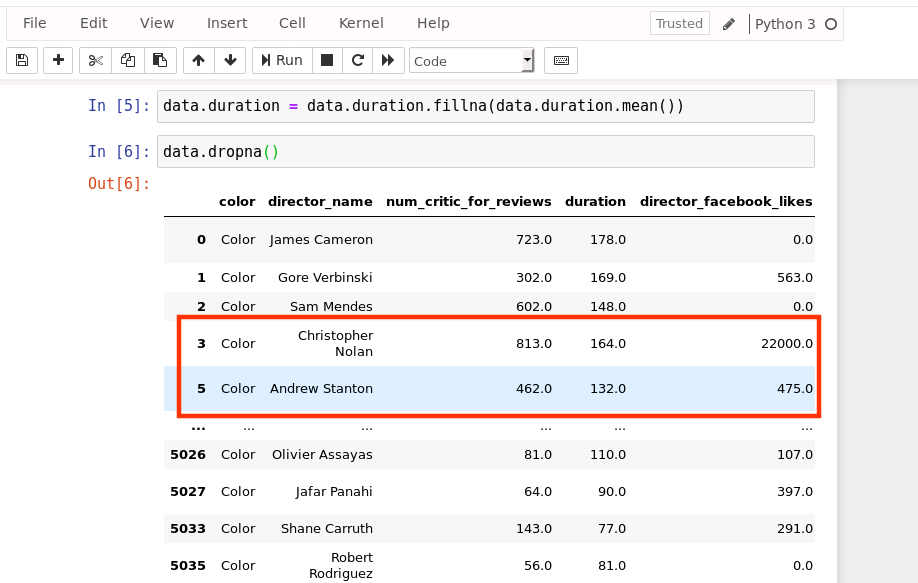
由上图可以看出,由于第4行数据存在缺失值,因此被删除
提示:dropna操作并不会在原始数据上做修改,它修改的是相当于原始数据的一个备份,因此原始数据还是没有变
删除一整行的值都为 NA:
data.dropna(how='all')// all 这一行全部为空才会被删除// any 一行中任意一个为空,就会被删除
运行结果如下:
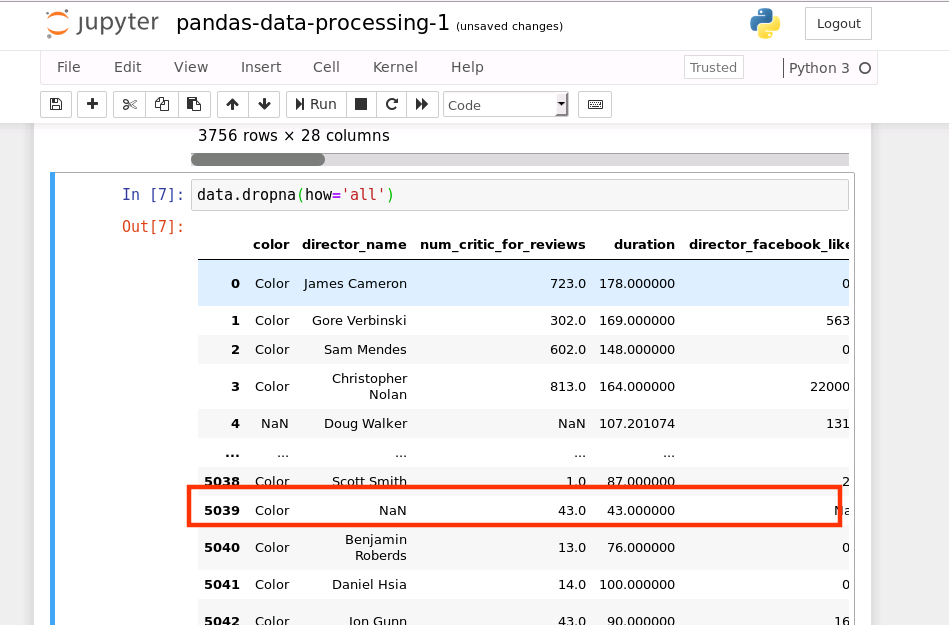
从上图可知,由于限定条件为:删除一整行都为NA的数据,因此不满足此条件的数据行还是会被保留
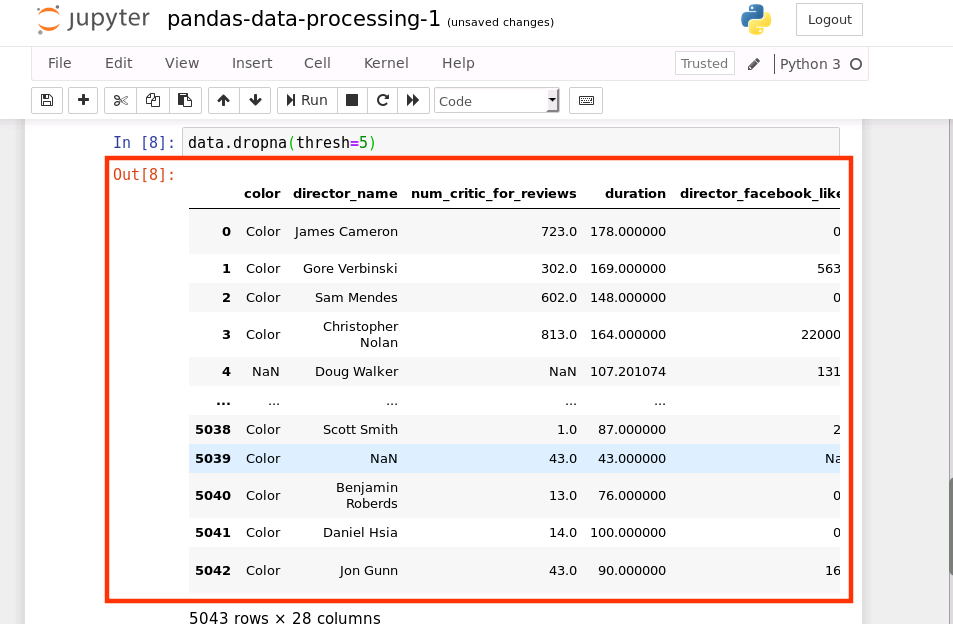
我们也可以增加一些限制,dropna(thresh=n) 保留至少有 n 个非 NA 数的行(在下面的代码中,行数据中至少要有 5 个非空值)
data.dropna(thresh=5)
运行结果如下:
也可指定需要删除缺失值的列
我们以 title_year 这一列为例,首先查看 title_year 这一列中存在的缺失值:
data['title_year'].isnull().value_counts()
结果如下:
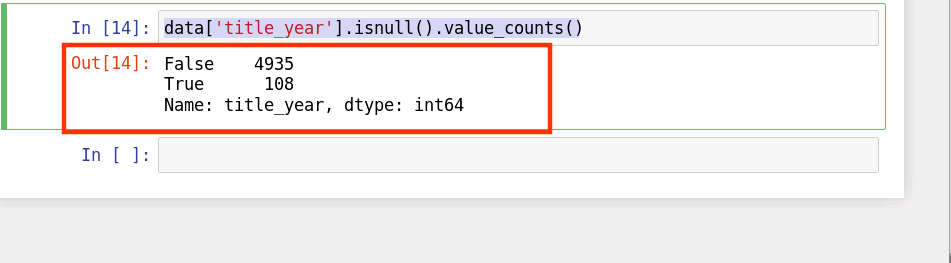
由上图可知,title_year 这一列中存在108个缺失值
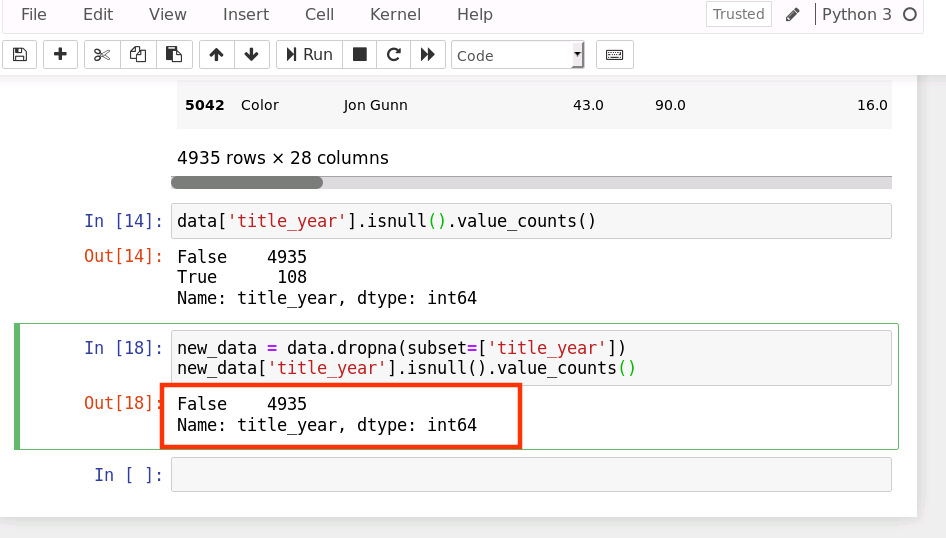
接下来查看 title_year 删除完缺失值后的情况
dropna(subset=[‘title_year’]),丢弃’title_year’这一列中有缺失值的行
new_data = data.dropna(subset=['title_year'])new_data['title_year'].isnull().value_counts()
上面的 subset 参数允许我们选择想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
运行结果如下:
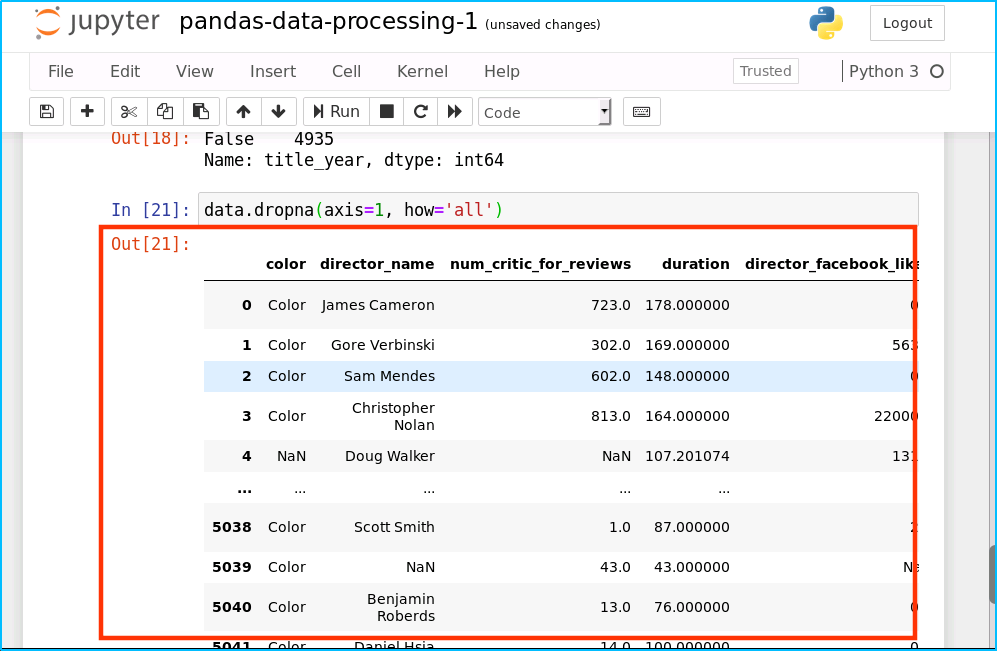
4.3、删除不完整的列
我们可以上面的操作应用到列上。我们仅仅需要在代码上使用 axis=1 参数。这个意思就是操作列而不是行。(我们已经在行的例子中使用了 axis=0,因为如果我们不传参数 axis,默认是axis=0)
删除一整列为 NA 的列:
data.dropna(axis=1, how='all')
运行结果如下:
删除任何包含空值的列:
data.dropna(axis=1,how='any')
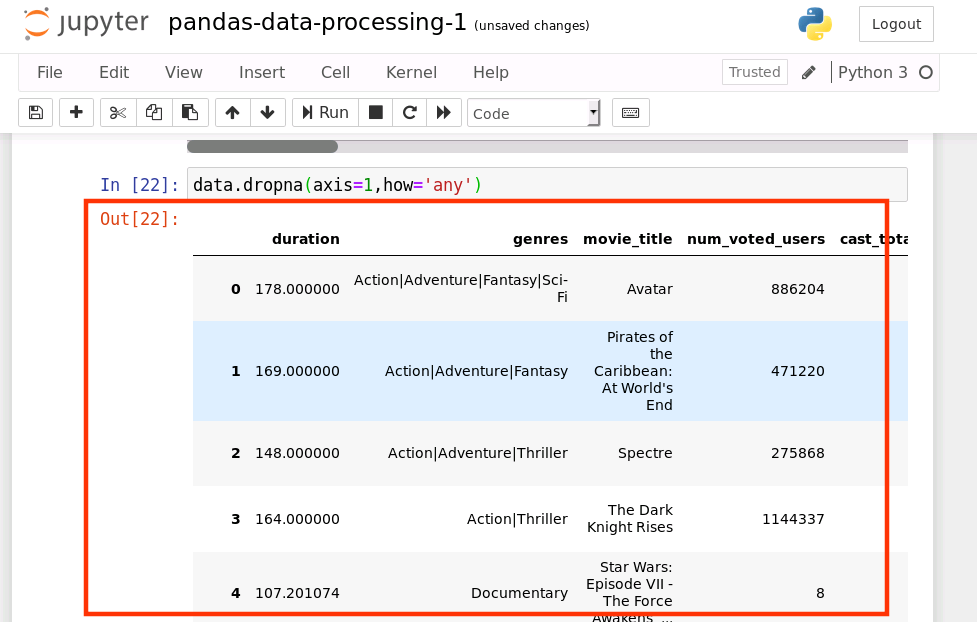
这里也可以使用像上面一样的 threshold 和 subset
5、规范化数据类型
加载数据集时指定字段数据类型dtype={‘title_year’:str})
data = pd.read_csv('./data/movie_metadata.csv', dtype={'title_year':str})
这就是告诉 Pandas ‘duration’列的类型是数值类型。查看加载后各数据列的类型
data.info()
运行结果如下:
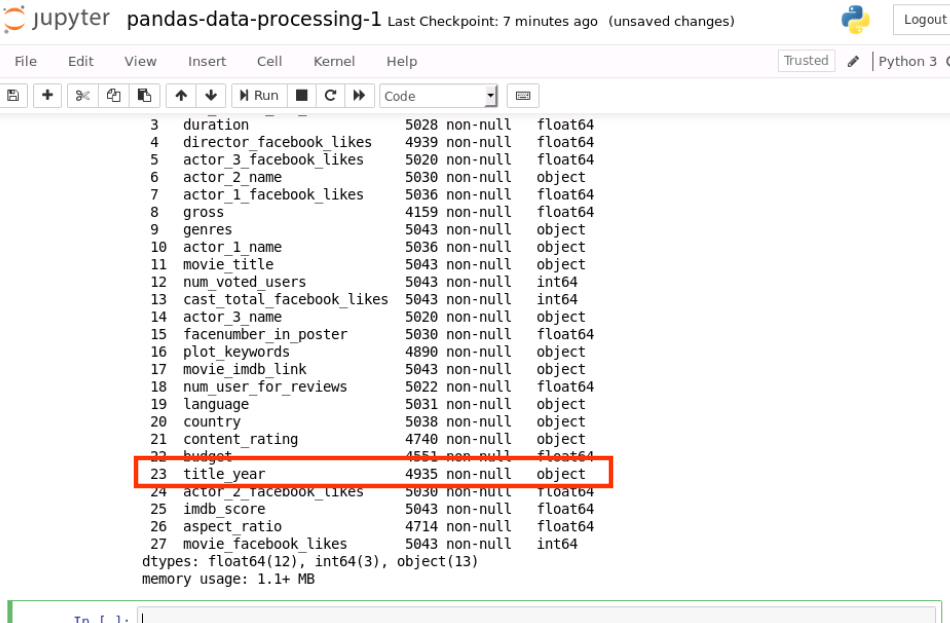
object 即代表数据类型为字符串类型
6、必要的变换
人工录入的数据可能都需要进行一些必要的变换,例如:
- 错别字
- 英文单词时大小写的不统一
- 输入了额外的空格
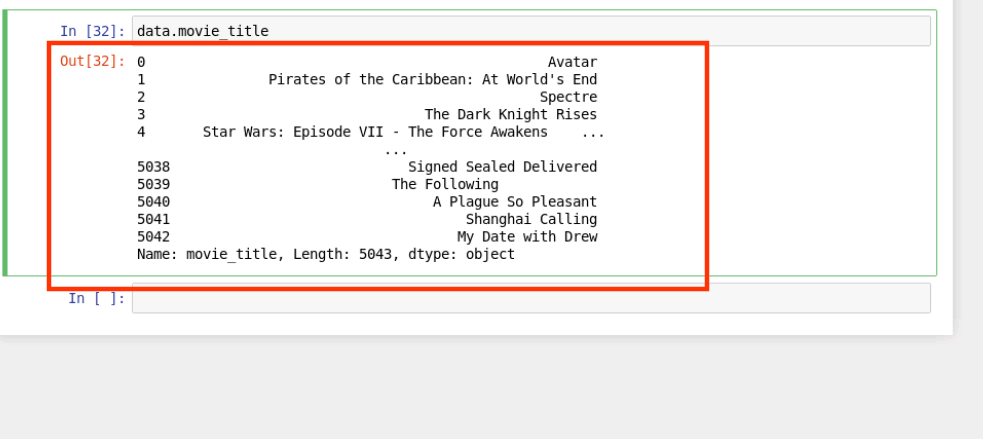
首先查看 movie_title 列数据
data.movie_title
结果如下:
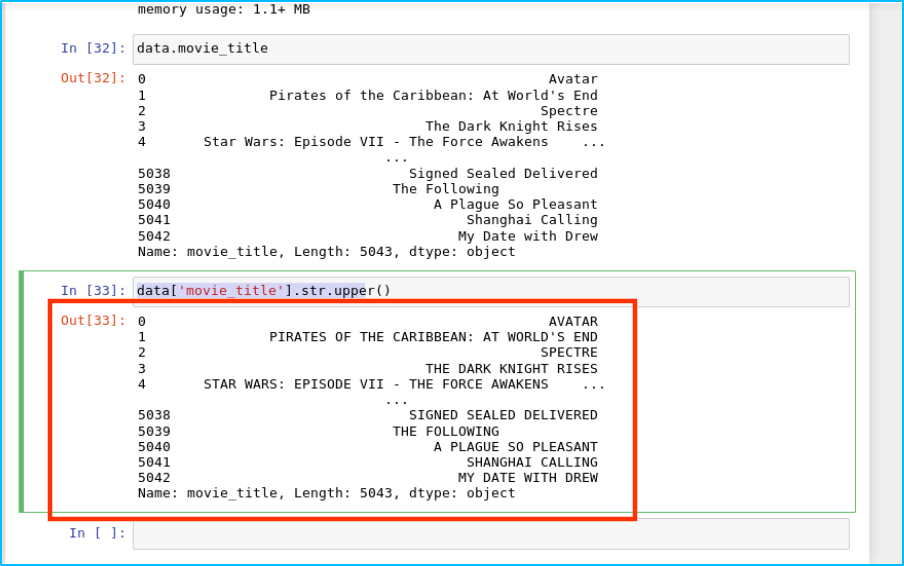
我们数据中所有的 movie_title 改成大写:
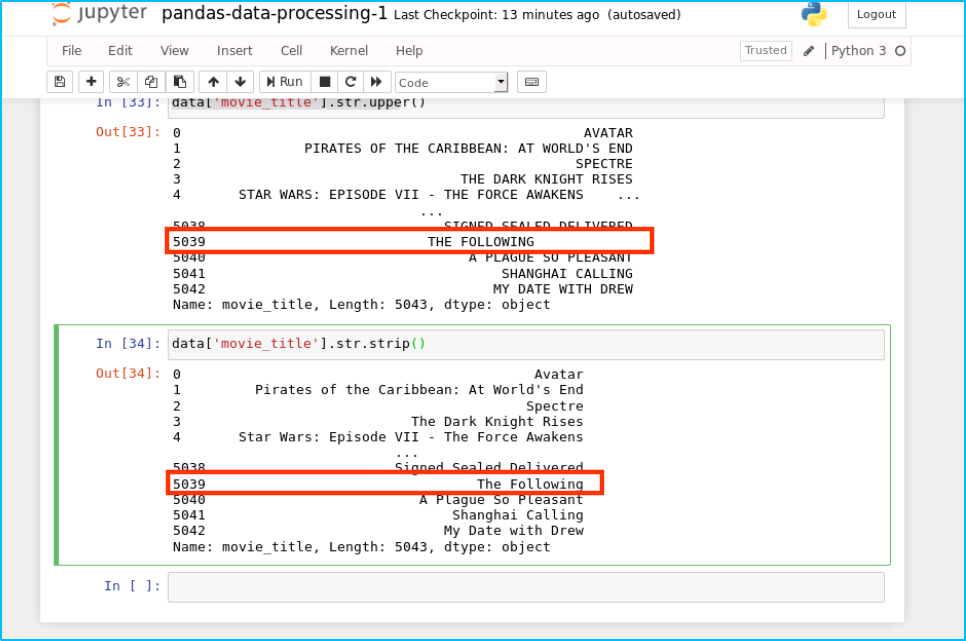
data['movie_title'].str.upper()
结果如下:
同样的,我们可以去掉末尾余的空格:
data['movie_title'].str.strip()
运行结果如下:
7、重命名列名
我们需要进行重新赋值才可以:
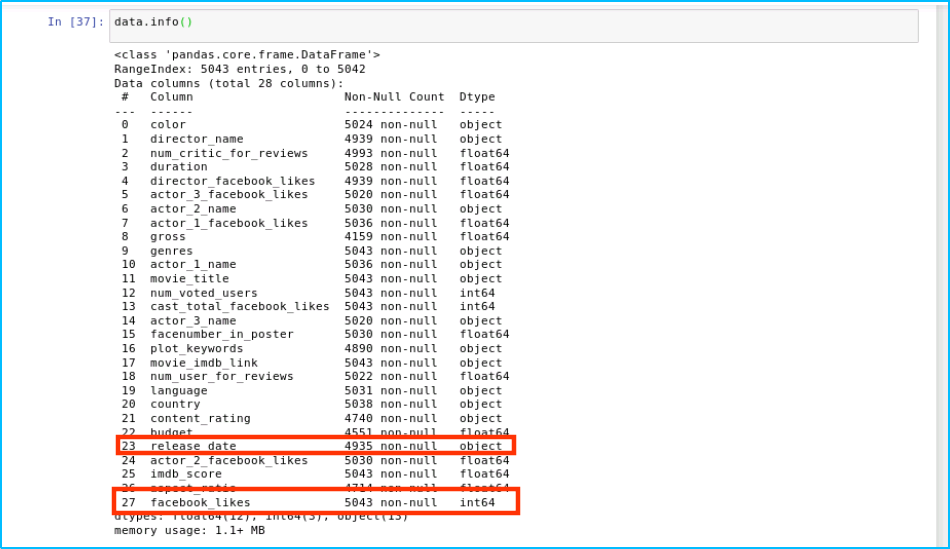
data = data.rename(columns={'title_year':'release_date', 'movie_facebook_likes':'facebook_likes'})
查看重命名后的数据列名称
data.info()
输出结果如下:
8、保存结果
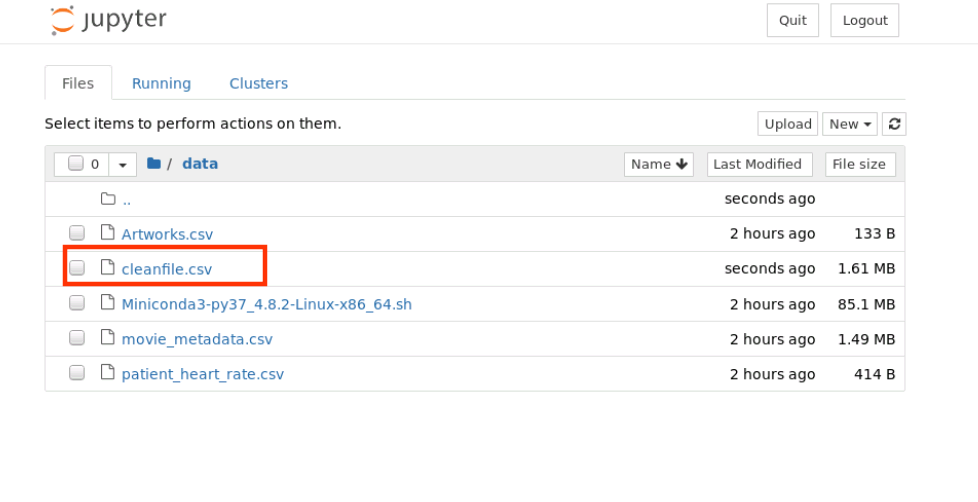
完成数据清洗之后,一般会把结果再以 csv 的格式保存下来,以便后续其他程序的处理。同样,Pandas 提供了非常易用的方法:
data.to_csv('./data/cleanfile.csv',encoding='utf-8')
查看 /home/student/data 目录内容如下,新增保存的 cleanfile.csv 文件
2、预备知识-python核心用法常用数据分析库(下)
实验环境
- Python 3.7
- Pycharm
任务二:Pandas数据分析实战-1
【任务目标】
本任务主要目标为使用pandas进行数据分析实战,在实战过程中带大家了解pandas模块的一下功能:
- 了解数据
- 分析数据问题
- 清洗数据
- 整合代码
【任务步骤】
1、准备工作
打开CMD窗口后,执行如下命令,打开jupyter notebook编辑器
jupyter notebook
成功执行以上命令后,系统将自动打开默认浏览器,如下图所示:
成功打开浏览器后,按如下流程创建 notebook 文件
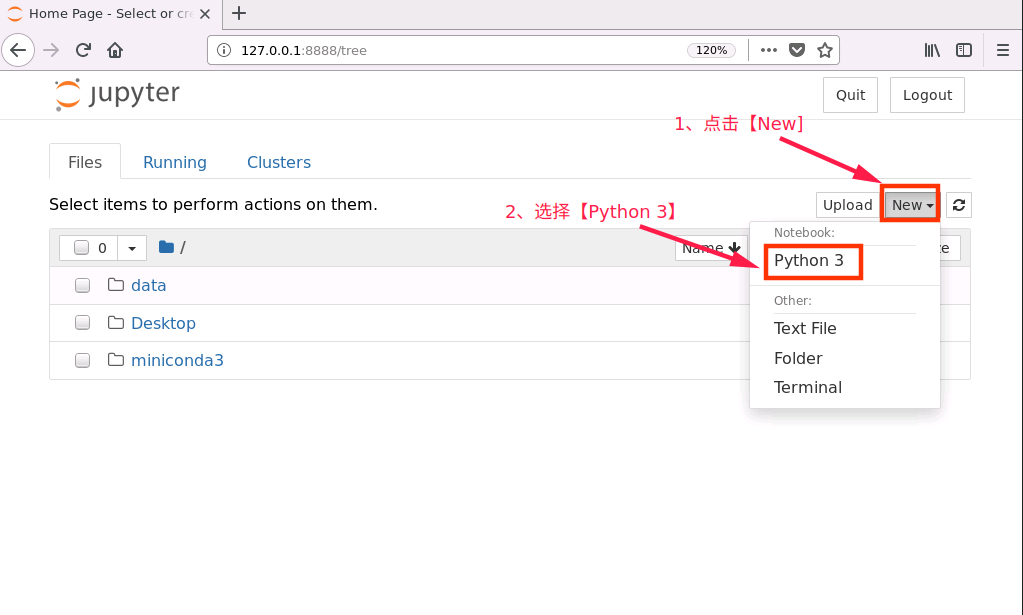
对新建notebook进行重命名操作
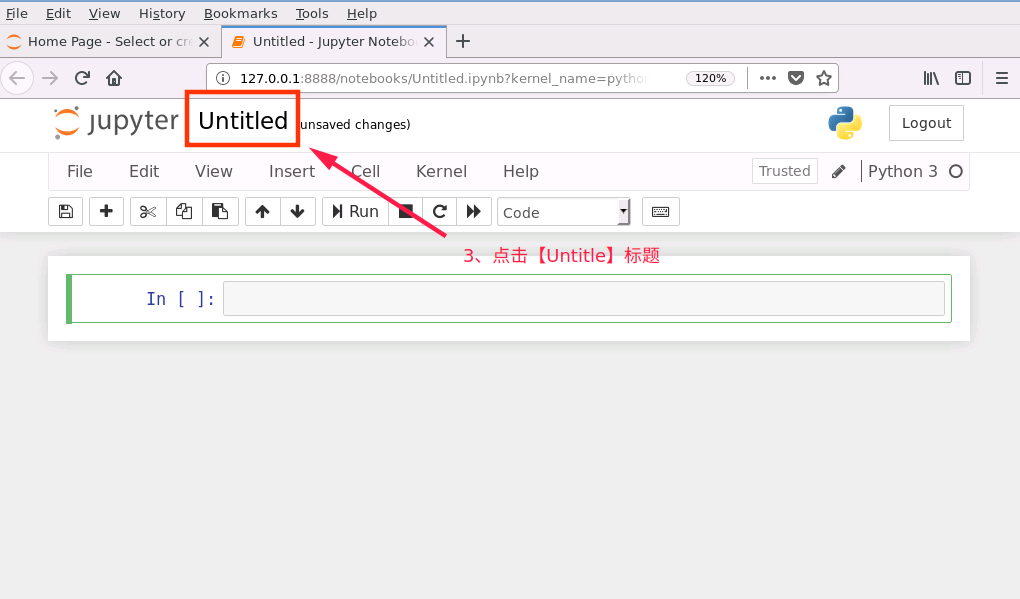
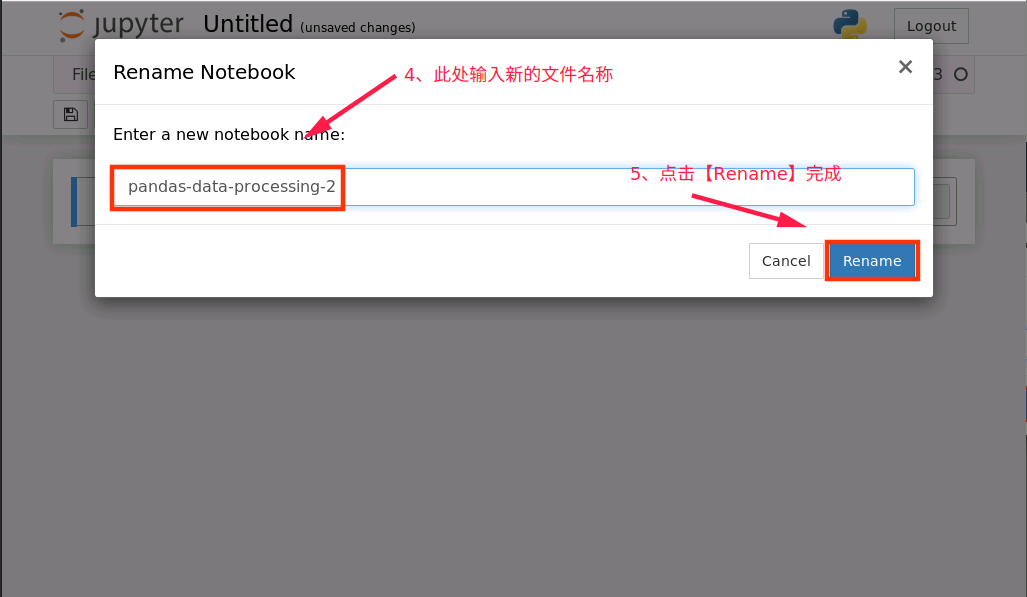
2、notebook 文件新建完成后,接下来在新建的 notebook 中编写代码
- 了解数据
在处理任何数据之前,我们的第一任务是理解数据以及数据是干什么用的。我们尝试去理解数据的列/行、记录、数据格式、语义错误、缺失的条目以及错误的格式,这样我们就可以大概了解数据分析之前要做哪些“清理”工作。
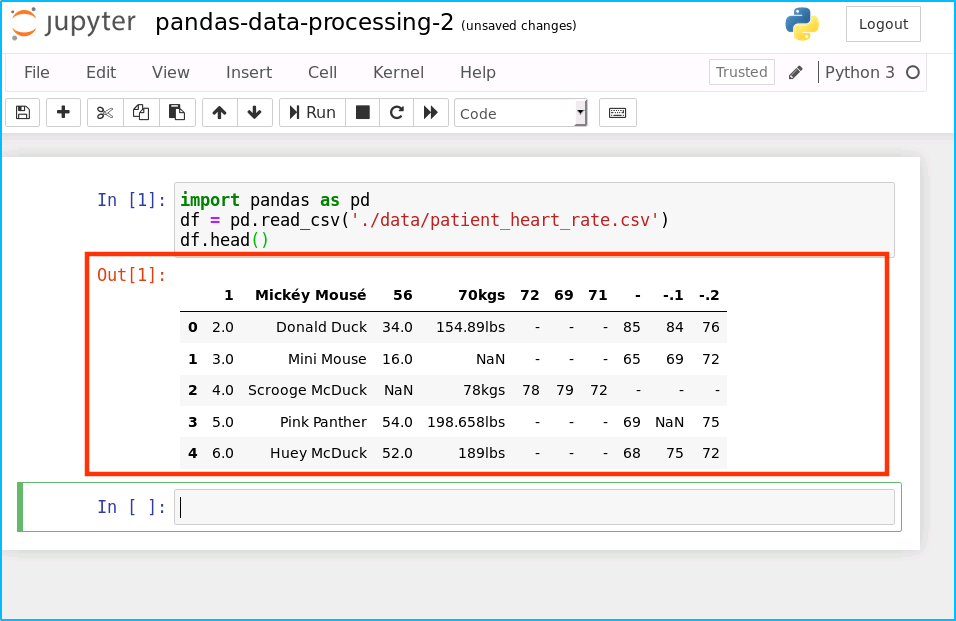
本次我们需要一个 patient_heart_rate.csv 的数据文件,这个数据很小,可以让我们一目了然。这个数据是 csv 格式。数据是描述不同个体在不同时间的心跳情况。数据的列信息包括人的年龄、体重、性别和不同时间的心率。
- 加载数据即查看数据集
import pandas as pd
df = pd.read_csv('data/patient_heart_rate.csv')
df.head()
运行结果如下:
分析数据问题
- 没有列头
- 一个列有多个参数
- 列数据的单位不统一
- 缺失值
- 重复数据
- 非 ASCII 字符
- 有些列头应该是数据,而不应该是列名参数 (行转列)
3、清洗数据
3.1、 没有列头
如果我们拿到的数据像上面的数据一样没有列头,Pandas 在读取 csv 提供了自定义列头的参数。下面我们就通过手动设置列头参数来读取 csv,代码如下:
import pandas as pd
column_names= ['id', 'name', 'age', 'weight','m0006',
'm0612','m1218','f0006','f0612','f1218']
df = pd.read_csv('data/patient_heart_rate.csv', names = column_names)
df.head()
运行结果如下:
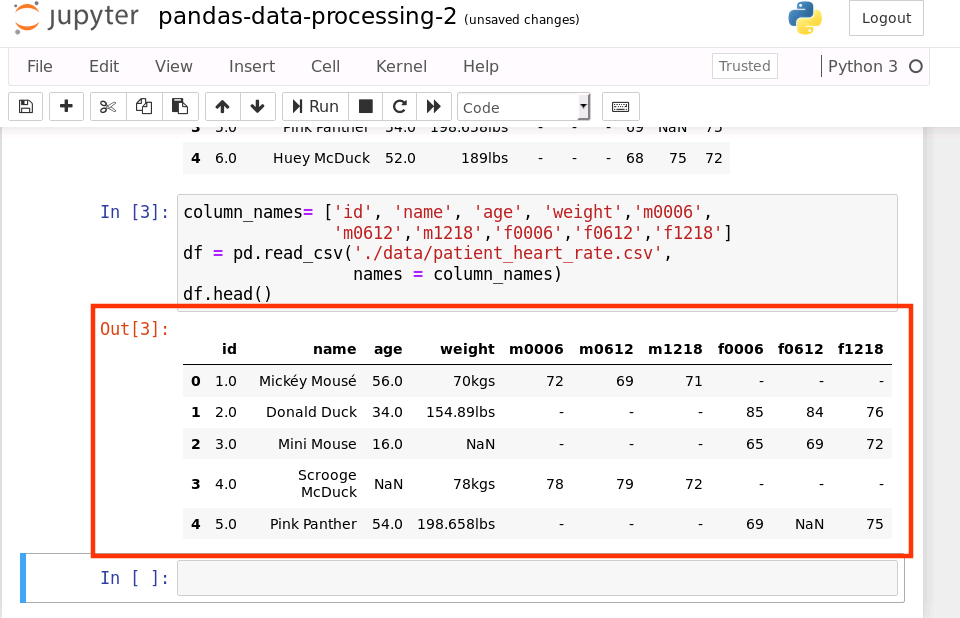
上面的结果展示了我们自定义的列头。我们只是在这次读取 csv 的时候,多了传了一个参数 names = column_names,这个就是告诉 Pandas 使用我们提供的列头。
4、一个列有多个参数
在数据中不难发现,Name 列包含了两个参数 Firtname 和 Lastname。为了达到数据整洁目的,我们决定将 name 列拆分成 Firstname 和 Lastname
使用 str.split(expand=True),将列表拆成新的列,再将原来的 Name 列删除
df[['first_name','last_name']] = df['name'].str.split(expand=True)
df.drop('name', axis=1, inplace=True)
df.head()
运行结果如下:
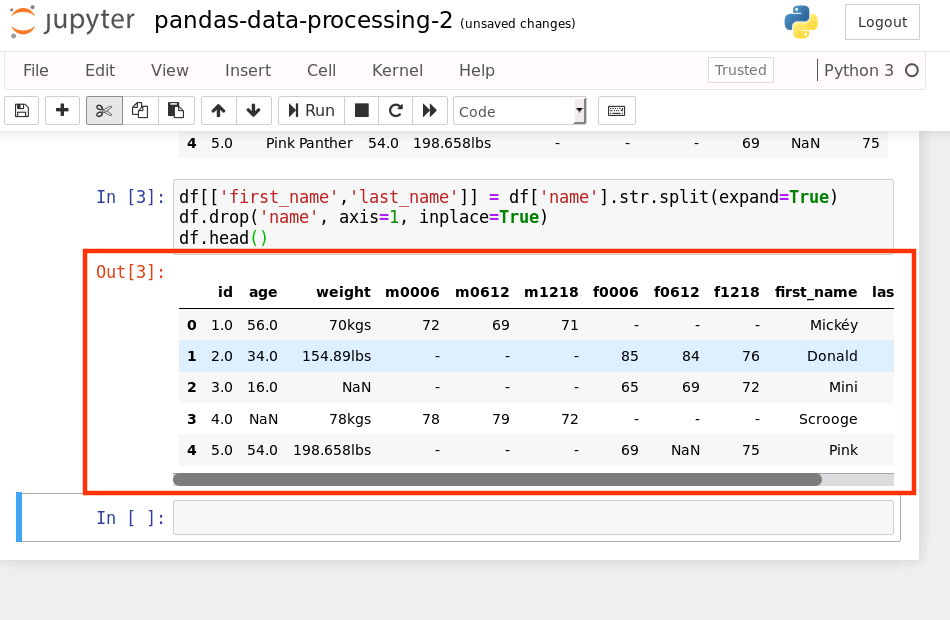
5、列数据的单位不统一
如果仔细观察数据集可以发现 Weight 列的单位不统一。有的单位是 kgs,有的单位是 lbs
// pandas 的 apply() 函数可以作用于 Series 或者整个 DataFrame,功能也是自动遍历整个 Series 或者 DataFrame
lbs_weight_s = df[df.weight.str.contains("lbs").fillna(False)]['weight']
lbs_weight_s = lbs_weight_s.apply(lambda lbs: "%.2fkgs" % (float(lbs[:-3])/2.2) )
df.loc[lbs_weight_s.index,'weight'] = lbs_weight_s
运行结果如下:
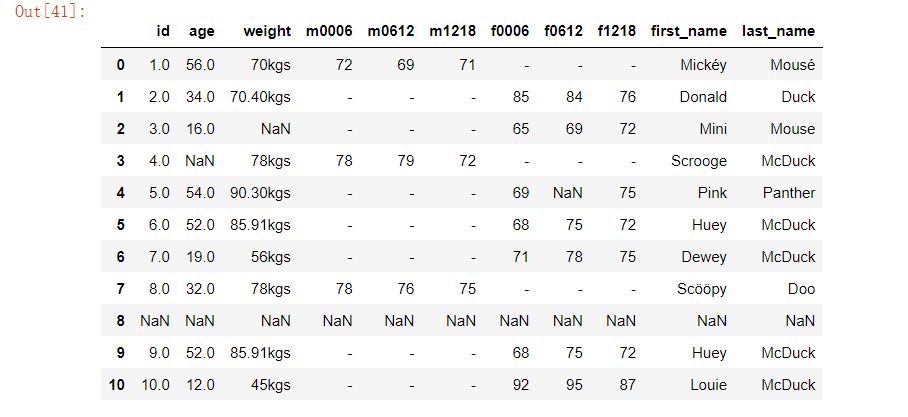
6、缺失值处理
在数据集中有些年龄、体重、心率是缺失的。我们又遇到了数据清洗最常见的问题——数据缺失。一般是因为没有收集到这些信息。我们可以咨询行业专家的意见。典型的处理缺失数据的方法:
- 删:删除数据缺失的记录
- 赝品:使用合法的初始值替换,数值类型可以使用 0,字符串可以使用空字符串“”
- 均值:使用当前列的均值
- 高频:使用当前列出现频率最高的数据
- 源头优化:如果能够和数据收集团队进行沟通,就共同排查问题,寻找解决方案。
7、重复数据处理
有的时候数据集中会有一些重复的数据,执行以下代码观察数据集前10条数据
df.head(10)
运行结果如下:
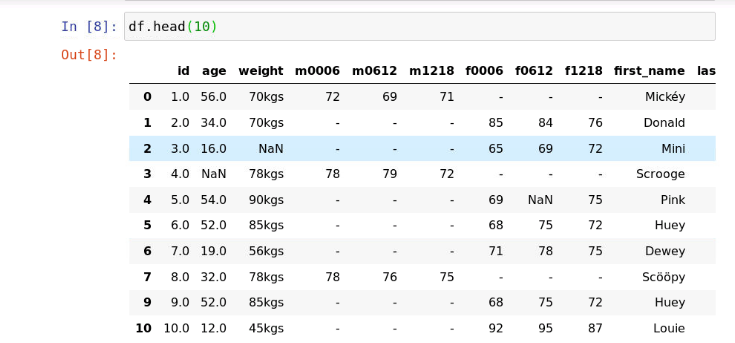
观察以上结果,可以发现在我们的数据集中也存在重复的数据,如下
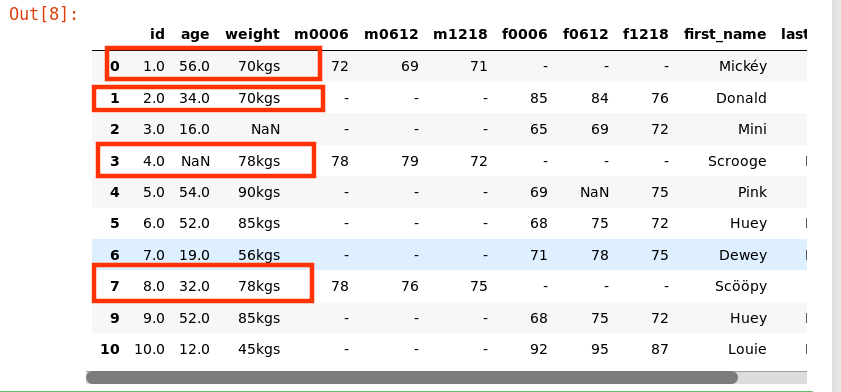
首先我们校验一下是否存在重复记录。如果存在重复记录,就使用 Pandas 提供的 drop_duplicates() 来删除重复数据。
df.drop_duplicates(['first_name','last_name'],inplace=True)
df.head(10)
运行结果如下:
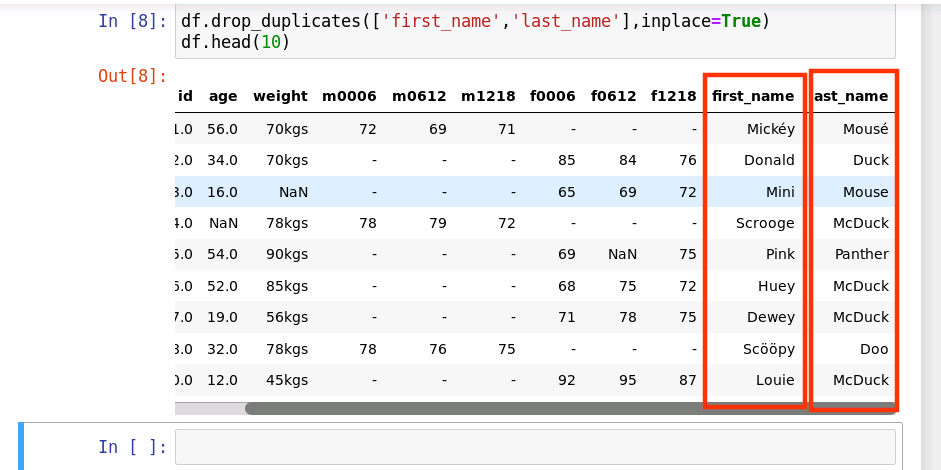
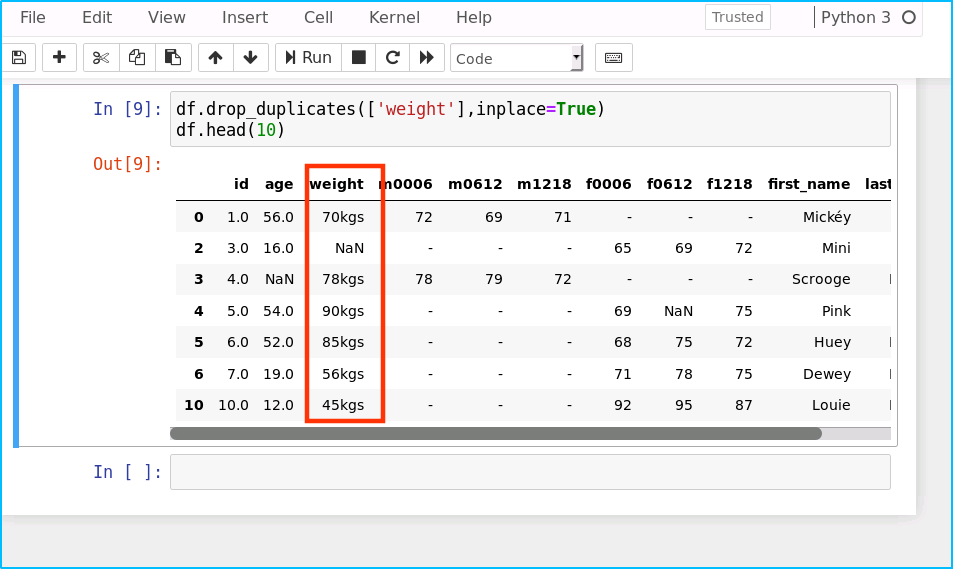
删除weight字段重复的数据
df.drop_duplicates(['weight'],inplace=True)
df.head(10)
运行结果如下
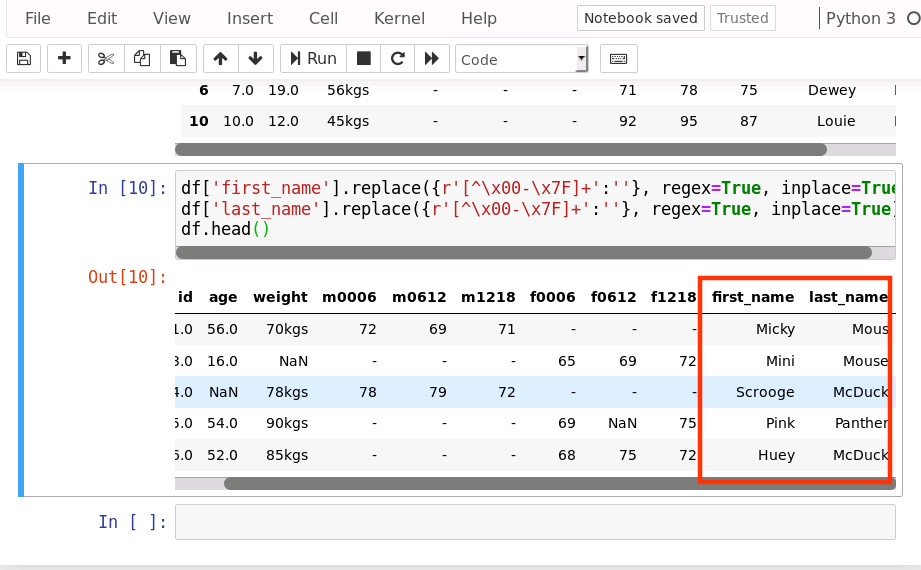
8、 非ASCII 字符
在数据集中 Fristname 和 Lastname 有一些非 ASCII 的字符。
处理非 ASCII 数据方式有多种
- 删除
- 替换
- 仅仅提示一下
我们使用删除的方式:
df['first_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)df['last_name'].replace({r'[^\x00-\x7F]+':''}, regex=True, inplace=True)df.head()
运行结果如下:
9、有些列头应该是数据,而不应该是列名参数
有一些列头是有性别和时间范围组成的,这些数据有可能是在处理收集的过程中进行了行列转换,或者收集器的固定命名规则。这些值应该被分解为性别(m,f),小时单位的时间范围(00-06,06-12,12-18)
sorted_columns = ['id','age','weight','first_name','last_name']
df = pd.melt(df,
id_vars=sorted_columns,
var_name='sex_hour',
value_name='puls_rate')
df = df[df.puls_rate != '-'].dropna()
df = df.sort_values(['id','first_name','']).reset_index()
def split_sex_date(sex_hour):
sex = sex_hour[:1]
if 'f' == sex:
sex = '女'
elif 'm' == sex:
sex = '男'
hour = sex_hour[1:]
return pd.Series([sex,hour])
df[['sex','hour']] = df.sex_hour.apply(split_sex_date)
df.drop('sex_hour',axis=1)
运行结果如下:
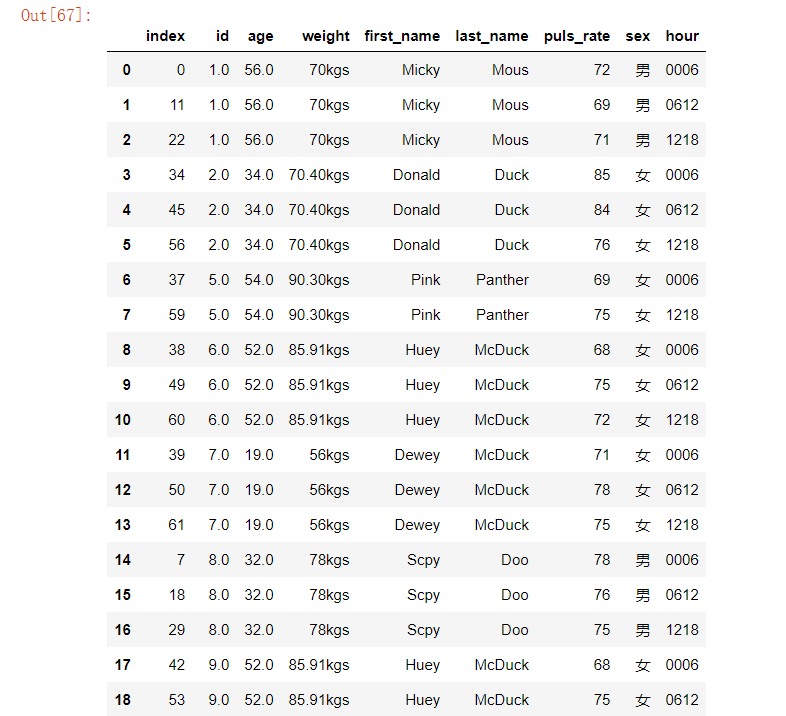
任务三:Pandas数据分析实战-2
【任务目标】
本任务主要目标为使用pandas进行数据分析实战,在实战过程中带大家了解pandas模块的一下功能:
- 日期的处理
- 字符编码的问题
【任务步骤】
1、参考【任务一】第1步中操作,在jupyter notebook编辑中重新新建一个notebook 文件,命名为 pandas-data-processing-3,如下图所示:
2、预览数据
这次我们使用 Artworks.csv,我们选取 100 行数据来完成本次内容。具体步骤:
- 导入Pandas
- 读取 csv 数据到 DataFrame(要确保数据已经下载到指定路径)
DataFrame 是 Pandas 内置的数据展示的结构,展示速度很快,通过 DataFrame 我们就可以快速的预览和分析数据。代码如下:
import pandas as pd
df = pd.read_csv('./data/Artworks.csv').head(100)
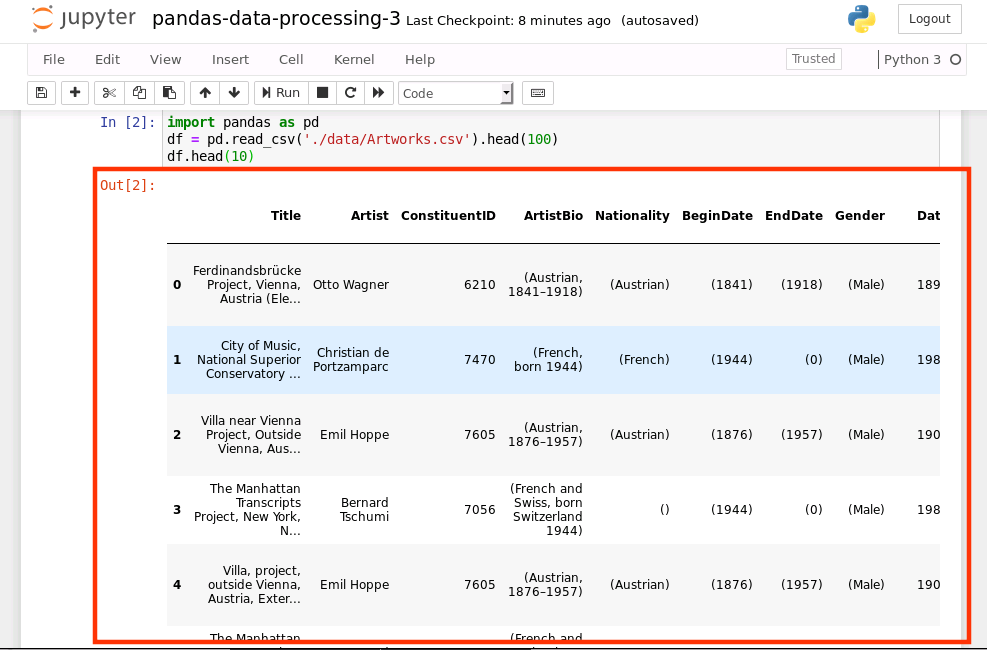
df.head(10)
运行结果如下:
2、统计日期数据
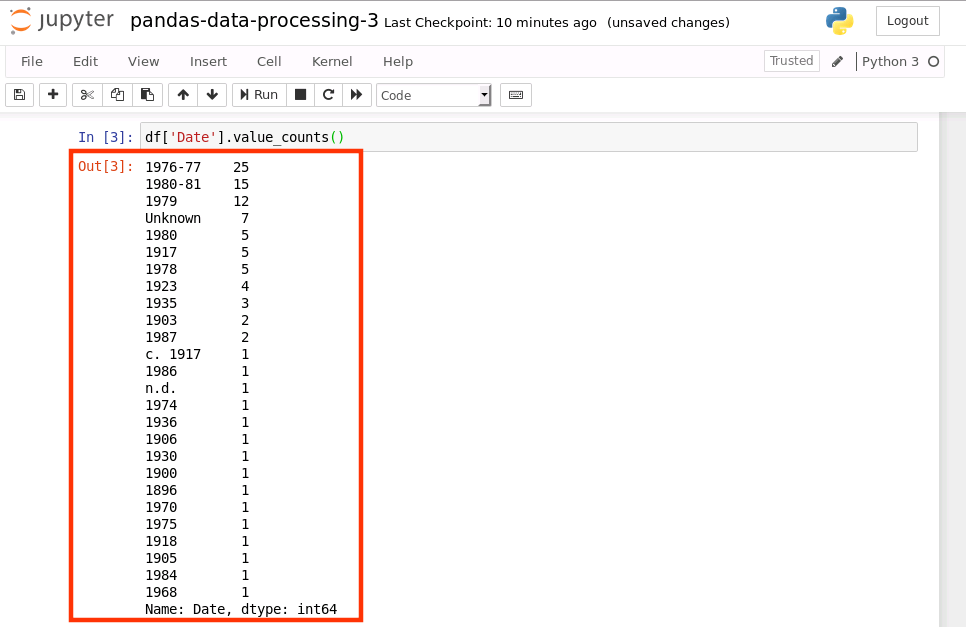
我们仔细观察一下 Date 列的数据,有一些数据是年的范围(1976-1977),而不是单独的一个年份。在我们使用年份数据画图时,就不能像单独的年份那样轻易的画出来。我们现在就使用 Pandas 的 value_counts() 来统计一下每种数据的数量。
首先,选择要统计的列,并调用 value_counts():
df['Date'].value_counts()
运行结果如下:
3、日期数据问题
Date 列数据,除了年份是范围外,还有三种非正常格式。下面我们将这几种列出来:
- 问题一,时间范围(1976-77)
- 问题二,估计(c. 1917,1917 年前后)
- 问题三,缺失数据(Unknown)
- 问题四,无意义数据(n.d.)
接下来我们会处理上面的每一个问题,使用 Pandas 将这些不规则的数据转换为统一格式的数据。
问题一和二是有数据的只是格式上欠妥当,问题三和四实际上不是有效数据。针对前两个问题,我们可以通过代码将据格式化来达到清洗的目的,然而,后两个问题,代码上只能将其作为缺失值来处理。简单起见,我们将问题三和四的数据处理为0。
处理问题一
问题一的数据都是两个年时间范围,我们选择其中的一个年份作为清洗之后的数据。为了简单起见,我们就使用开始的时间来替换这样问题的数据,因为这个时间是一个四位数的数字,如果要使用结束的年份,我们还要补齐前两位的数字。
首先,我们需要找到问题一的数据,这样我们才能将其更新。要保证其他的数据不被更新,因为其他的数据有可能是已经格式化好的,也有可能是我们下面要处理的。
我们要处理的时间范围的数据,其中包含有“-”,这样我们就可以通过这个特殊的字符串来过滤我们要处理的数据,然后,通过 split() 利用“-”将数据分割,将结果的第一部分作为处理的最终结果。
代码如下
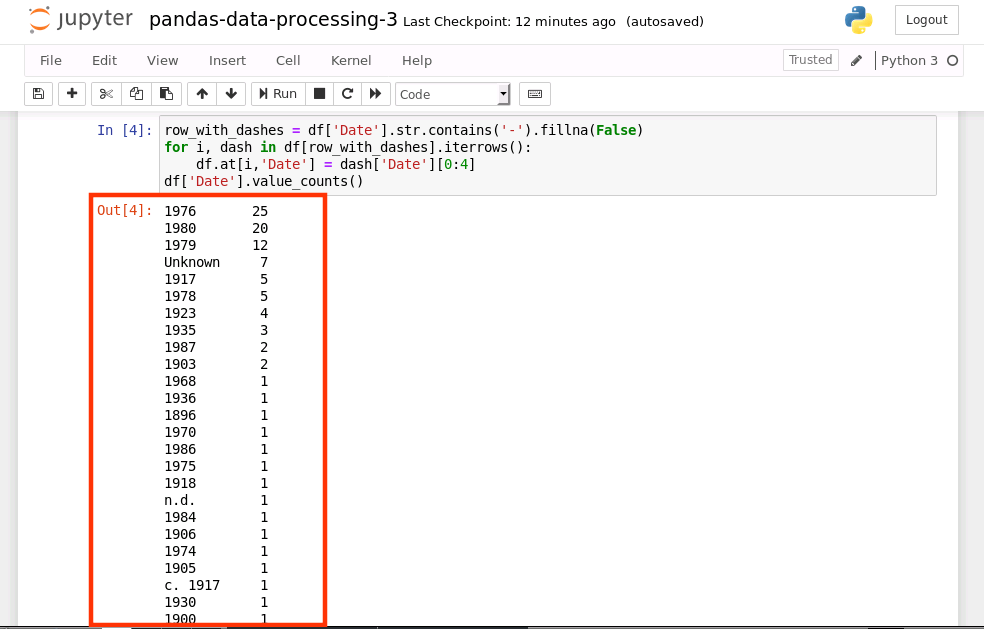
row_with_dashes = df['Date'].str.contains('-').fillna(False)
for i, dash in df[row_with_dashes].iterrows():
df.at[i,'Date'] = dash['Date'][0:4]
df['Date'].value_counts()
运行结果如下:
处理问题二
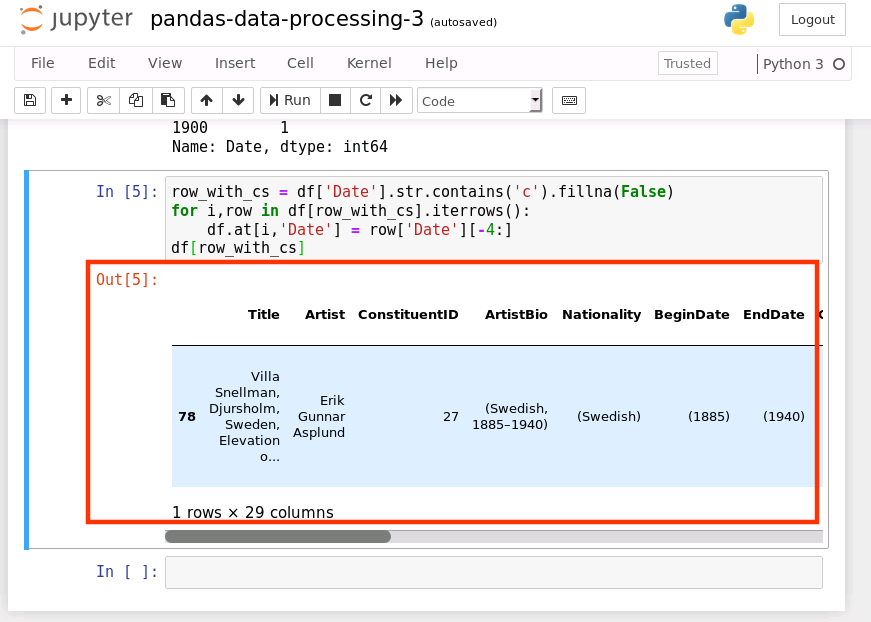
问题二的数据体现了数据本身的不准确性,是一个估计的年份时间,我们将其转换为年份,那么,就只要保留最后四位数字即可,该数据的特点就是数据包含“c”,这样我们就可以通过这一特征将需要转换的数据过滤出来。
row_with_cs = df['Date'].str.contains('c').fillna(False)
for i,row in df[row_with_cs].iterrows():
df.at[i,'Date'] = row['Date'][-4:]
df[row_with_cs]
运行结果如下:
处理问题三四
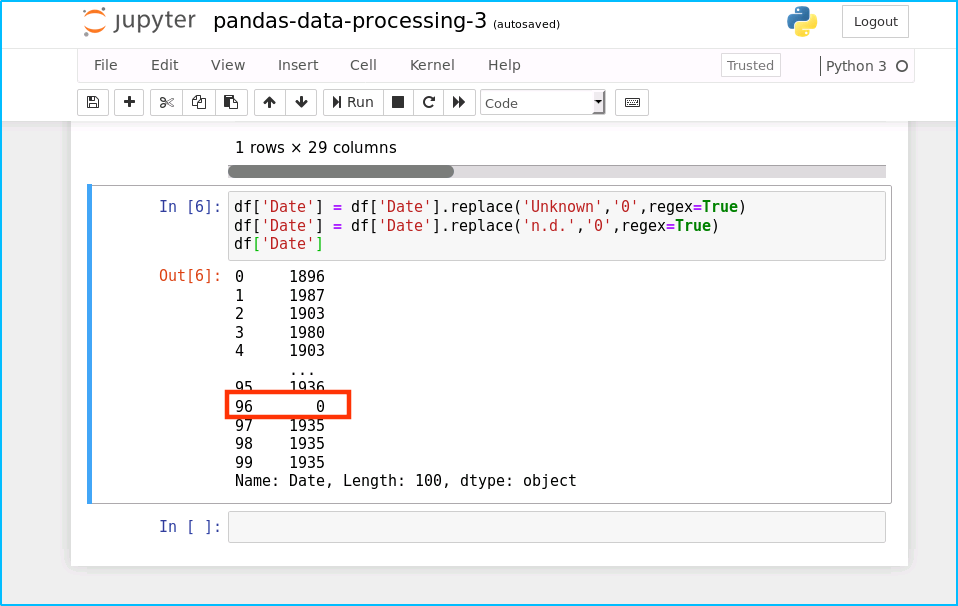
将这问题三四的数据赋值成初始值 0
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date']
运行结果如下:
4、附:完成代码
注意:完整代码中删除了数据展示部分
import pandas as pd
df = pd.read_csv('../data/Artworks.csv').head(100)
df.head(10)
df['Date'].value_counts()
row_with_dashes = df['Date'].str.contains('-').fillna(False)
for i, dash in df[row_with_dashes].iterrows():
df.at[i,'Date'] = dash['Date'][0:4]
df['Date'].value_counts()
row_with_cs = df['Date'].str.contains('c').fillna(False)
for i,row in df[row_with_cs].iterrows():
df.at[i,'Date'] = row['Date'][-4:]
df['Date'].value_counts()
df['Date'] = df['Date'].replace('Unknown','0',regex=True)
df['Date'] = df['Date'].replace('n.d.','0',regex=True)
df['Date'].value_counts()
















 1772
1772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











