






1.HDFS集群环境简介
1.1简介
全称 Hadoop Distributed File System, Hadoop分布式文件系统。 根据Google的GFS论文,由Doug Cutting使用JAVA开发的开源项目。HDFS是Hadoop项目的一部分。为Hadoop提供底层的数据存储,满足上次各种实际应用使用(如Map/Reduce)。HDFS是典型的的Master/Slave集群架构,由一个NameNode和多个DateNode组成,NameName只能有一个,扮演Master角色,负责对具体的存储块的元数据进行保存,比如控制某个存储块具体保存在哪个DataNode上;DataNode可以为多个,扮演着Slave的角色,负责对具体的存储块进行保存,一个相同的存储块根据配置可以保存到多个DataNode上,以保持数据的高可用性。
1.2 环境准备
需要三台linux虚拟机(配置基本一样),一台NameNode(Master),两台DataNode(Slave)。
虚拟机相关配置如下表所示:
NameNode 192.168.31.179 tj-namenode Master CentOS 7
DataNode 192.168.31.180 tj-datanode-1 Slave CentOS 7
DataNode 192.168.31.181 tj-datanode-2 Slave CentOS 7
2.搭建过程
2.1环境配置准备工作
(需要知道hadoop依赖Java和SSH)
1.创建hdfs账号(密码自己设置,我这里设置为hdfs),便于管理

2.修改主机名,修改后主机名如上表格所示

3.下载JDK1.8(HDFS是Java写的,需要支持JDK环境)
这里我用的是JDK1.8绿色版的,直接下载安装,根据Readme文档操作,无需配置环境变量。
下载地址:http://192.168.30.74:8080/jenkins/job/PublicComponent-dxm/ws/PublicService/
4.下载Hadoop安装包
在官方网站上下载最新版本的前一个版本(更稳定些)
2.2配置免密码的SSH访问机制
1.安装SSH
通常Centos系统都默认安装SSH,可以用以下截图的命令查看是否已经安装SSH(如图所示,已经安装好,故不用再安装了),如果没有安装,请单独安装,命令:yum install ssh

2.先切换到hdfs账号

3. $ cd ~

4.在NameNode上执行下面的命令,生成RSA密钥对,如图所示 $ ssh-keygen -t rsa
- $ ll -a 查看该目录下多了个.ssh的隐藏文件夹
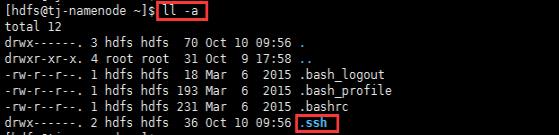
6.进入隐藏目录.ssh,然后执行如下命令 $ cat id_rsa.pub >> authorized_keys
7.将authorized_keys文件远程传给另外两个datanode机器的相应目录下。
$ scp authorized_keys hdfs@192.168.31.180:/home/hdfs/.ssh
$ scp authorized_keys hdfs@192.168.31.181:/home/hdfs/.ssh
!!!其中一个重要步骤,就是修改authorized_keys文件的权限(如下所示),否则下面无法测试免密连接通过。
8.ssh连接验证:无需密码,直接可以登录(namenode和两个datanode均可以免密连接)
9.至此,配置免密码的SSH访问机制就完成了。















 2786
2786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









