







Mapper阶段:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
// Mapper中的业务逻辑写在map()方法里面
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String s = value.toString(); //获取一行数据
String[] words = s.split(" "); //按空格来切分字符
for (String word : words) {
k.set(word); // String类型需要转换为Text类型
context.write(k, v); //map中的key、value写入context
}
}
}
Reducer阶段:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// Reducer中的业务逻辑写在reduce()方法里
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable v : values) {
sum += v.get(); // v的类型与sum不一致先要转换数据类型
}
IntWritable intWritable = new IntWritable();
intWritable.set(sum);
context.write(key, intWritable); //reduce中的key、value写入context
}
}
驱动类来关联Mapper和Reducer
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
String inputPath = "E:/input/test.txt"; //文件的输入路径
String outputPath = "E:/output"; // 文件的输出路径
Configuration conf = new Configuration();
Job job = Job.getInstance(conf); //获取一个job的实例
job.setJarByClass(WordcountDriver.class); // 通过反射给定类的来源来设置Jar
job.setMapperClass(WordcountMapper.class); // 关联Map和Reduce
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class); // Mapper阶段的输出的K,V类型
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class); // 程序最终输出的K,V类型
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileOutputFormat.setOutputPath(job,new Path(outputPath));
boolean result = job.waitForCompletion(true);
//交给yarn去执行,直到执行结束才退出本程序,true为程序运行时可见此过程
System.exit(result ? 0 : 1);
}
}
原文件:

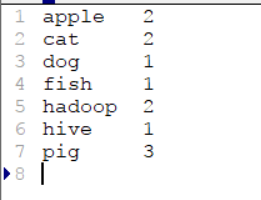
运行程序后可以发现在对应的路径已经生成了相应的文件。

打开part-r-00000这个文件发现和我们预期的结果一样。















 2217
2217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









