






信息熵:描述一个系统不确定性的指标,它是系统信息量的期望,一个系统如果不确定性越大,比如A,B,C,D四个互斥事件的发生概率为[1/4,1/4,1/4,1/4],四个事件的发生概率一样,不确定性非常高,那么这个系统的信息熵就很大,反之系统的信息熵就很小。公式中p(i)代表每个事件的发生概率,而log(1/p(i))是事件的信息量,为啥这两个是对数关系呢,两个独立不相关的事件A与B,理想状态下他们的信息量之和I(A)+I(B)应该等于两件事同时发生的信息量I(A,B),而他们同时发生的概率为两件事发生的概率乘积p(A,B) = p(A)*p(B),所以我们推断信息量和概率之间存在某种对数关系,I(x) = log(1/p(x))。
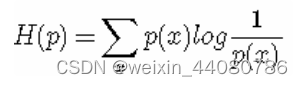
交叉熵:描述我们目前预测的概率分布q(x)与真实概率分布p(x)之间的差异,相当于用真实的概率分布,来衡量非真实的信息量期望。如果非真实分布q(x)预测正确了,那么明显交叉熵会非常小,所以交叉熵经常作为模型的损失函数。
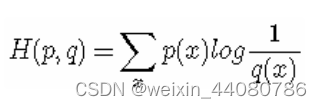
相对熵:描述两个概率分布之间的差异,KL散度就是相对熵。相对熵并不对称,比如:DKL(p||q)并不等于DKL(q||p),可以理解为用一个分布区拟合另一个分布所付出的代价。它与交叉熵的区别可以从公式中看出:p拟合q的相对熵 = p信息熵 - p与q的交叉熵。而且,在上述交叉熵的情景下,真实分布是一个one-hot的确定分布,如果不是确定分布,交叉熵无法等于0,而相对熵只要两个分布一致,无论这个分布是否确定,都可以等于0。
x














 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









