







-
以下内容会相当抽象,需要耐心学习
-
四种数据类型
-
gauge 当前值 最简单,看标签
-
counter 计数器 多用在请求计数,cpu统计
-
histogram 直方图样本观测 :服务端算分位值
-
summary 摘要:客户端算分位值
-
利用 sum/count 算平均值 :histogram 和summary 都适用
-
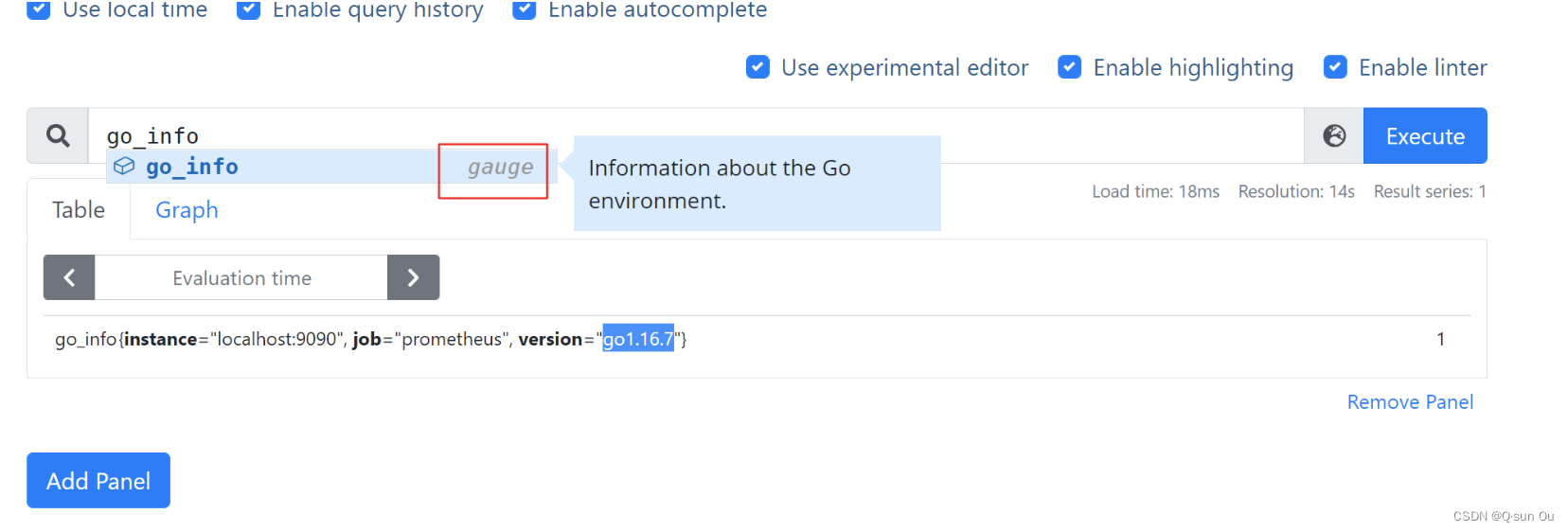
1.gauge 当前值
-
举例 go_info{instance="localhost:9090", job="prometheus", version="go1.16.7"}
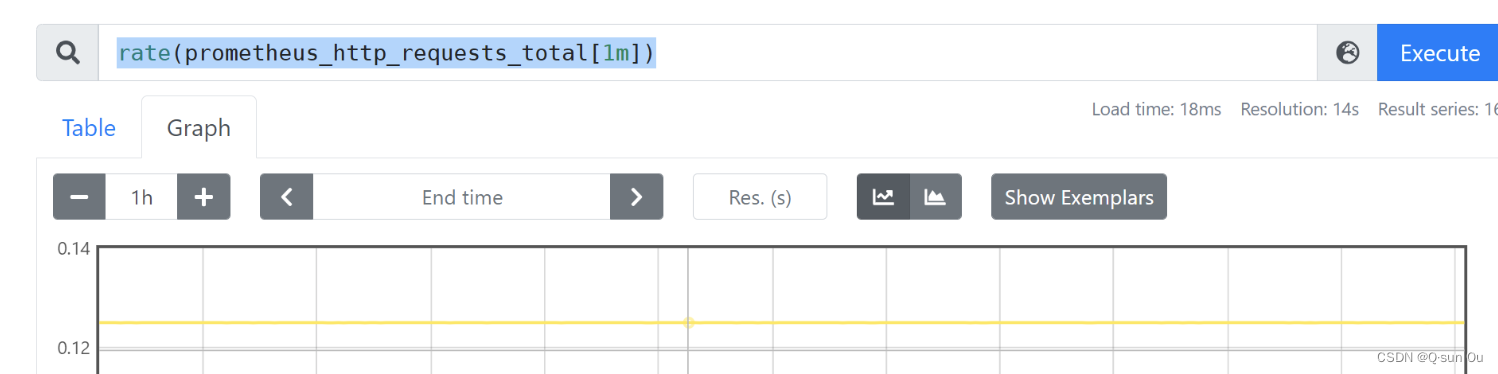
2.counter 计数器
-
代表一个累积指标单调递增计数器
-
使用rate 查看1分钟内qps(累积所有接收到的 HTTP 请求总数)
-
rate(prometheus_http_requests_total[1m])
3.histogram 直方图样本观测
-
histogram是一种用于度量和分析数据分布情况的指标类型。它主要用于记录请求响应时间、任务执行时间等具有分布特性的性能指标。 -
一个 Prometheus 的直方图(Histogram)由以下几部分组成:
-
计数器:记录所有观测样本的数量。
-
桶(Buckets):一组预定义的区间,每个区间表示一段时间范围内的观测值数量,每个区间就是一个桶。例如,可以设置一系列区间来统计延迟在[0.01s, 0.1s), [0.1s, 1s), [1s, 10s)等不同区间的请求数量,Prometheus 将根据其响应时间大小将其计入相应的桶内。
-
总结(Summary):除了桶之外,还包含两个额外的数据点,即所有观测样本的总和以及样本平方和,这些信息可用于计算平均值和标准差等统计数据。
举例:
-
Histogram_quantile(0.95,sum(rate(prometheus_http_request_duration_seconds_bucket[1m]))by (le))
-
在 Prometheus 中用来查询 HTTP 请求响应时间(1m)分布的 95% 分位数的一个表达式。
-
Histogram_quantile(): 这是一个内置函数,用于计算直方图(Histogram)的指定分位数。这里的
0.95表示要计算的是第 95 个百分位数,这意味着有 95% 的请求响应时间小于或等于该分位数值。 -
在一个服务的所有请求响应时间数据集合(例如有100个请求)里,如果我们将这些响应时间从小到大排序,当累计百分比达到 95% 的时候所对应的那个响应时间值,就是“第 95 个百分点”的响应时间。高于这部分数值的请求,说明是需要关注和优化的。
-
sum(rate(...)):在这里是将过去1分钟速率加总
rate()函数用于计算给定时间段内的瞬时速率,这里指过去一分钟内每秒新增的观测样本数量。sum()函数则将所有 bucket 的速率加总起来,以得到总的样本计数。-
prometheus_http_request_duration_seconds_bucket[1m]: 这是 Prometheus 自身监控指标,表示过去一分钟内 HTTP 请求处理完成所花费时间落入各个预定义桶范围内的次数。每个 bucket 对应一个特定的时间段。
4.summary 摘要会采样观察值
-
通常是请求持续时间和响应大小之类的东西
-
尽管它还提供了观测值的总数和所有观测值的总和
-
与 Histogram 类似,Summary 也用来跟踪具有分布特性的性能指标,比如 HTTP 请求处理时间。但 Summary 的实现方式略有不同:
- 样本累积:Summary 接收并累积观测样本,但不将它们分配到固定的桶内,而是直接计算统计信息。
- 统计信息:
count:累计收到的观测样本总数。sum:所有观测样本值的总和。quantile:可以自定义查询任意分位数的数据点,例如 p50(中位数)、p95、p99 等。
在 Prometheus 查询表达式中,Summary 可以通过内置函数获取相应的统计值,例如:
summarize()函数可以对 Summary 数据进行聚合和分组操作。quantile()函数可以用来获取 Summary 指标在指定时间段内的某个分位数数据。
-
http_request_duration_seconds_summary{job="myjob"}.quantile(0.95)
-
这个查询会返回过去5分钟内“myjob”服务HTTP请求延迟的第95个百分位数。
利用 sum/count 算平均值 :histogram 和summary 都适用
-
go_gc_duration_seconds_sum/go_gc_duration_seconds_count 算平均值

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









